第八篇、正则表达式 re模块
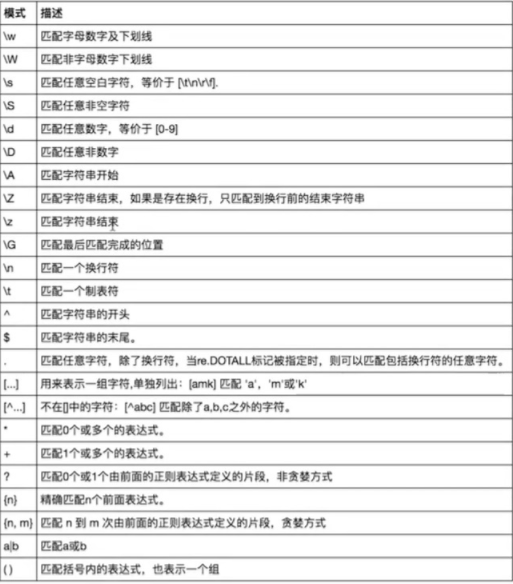
一、常用匹配模式
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import re
#贪婪匹配:从后面开始
#()只需要提取括号中的内容,顺序从外到内
line="pyrene11111pppp111 a"
# regex_str=".*(p.*p).*" #这个是贪婪模式,从后面匹配得到pp
regex_str=".*?(p.*p).*" #前面有?非贪婪模式,从前面匹配,后面是贪婪模式,后面匹配pyrene11111pppp match_obj=re.match(regex_str,line)
if match_obj:
print(match_obj.group(1)) #?非贪婪匹配:问号放左边从左边开始匹配
line="pyrene00000000p pppp123"
regex_str=".*?(p.*?p).*"
match_obj=re.match(regex_str,line)
if match_obj:
print(match_obj.group(1)) #+的用法
line="pyrene00000000p pppp123"
regex_str=".*(p.+p).*" #这是贪婪模式,所以会从后面开始,这里+最低出现一个,所以结果为ppp
match_obj=re.match(regex_str,line)
if match_obj:
print(match_obj.group(1)) #{n},限定前面字符出现几次,{1,3}前面字符出现最低1次最多3次
line="pyrene00000000p pppssp123"
# regex_str=".*(p.{1}p).*" #由于必须出现前面的字符一次,这又是贪婪模式,所以会从后往前找,结果pp
regex_str=".*(p.{2}p).*" #这里满足,结果pssp
match_obj=re.match(regex_str,line)
if match_obj:
print(match_obj.group(1)) #|代表或者
line="pyrene123"
# regex_str="(pssp123|pyrene)"
regex_str="((pssp|pyrene)123)"
match_obj=re.match(regex_str,line)
if match_obj:
print(match_obj.group(2)) #这里值为1的时候匹配pyrene123,参数为2匹配pyrene #[]
line="pyrene123"
regex_str="([abc]pyrene123)" #表示第一个字符为中括号中任意字符,就能够匹配到
match_obj=re.match(regex_str,line)
if match_obj:
print(match_obj.group(2)) #[] 代表区间 如果里面有.*就不表示特殊含义,^取反
line="18511391111"
# regex_str="(1[48357][0-9]{9})"#这里表示第一个字符是1,第二个字符是中括号中间的内容,第三个字符是0-9之间的树,第四个是前面的匹配9次
regex_str="(1[48357][^1]{9})"#第一个字符表示第一个是1,第二个是中括号的所有内容,第三个字符只要不是1就可以,第四个字符是前面的数字匹配9次 match_obj=re.match(regex_str,line)
if match_obj:
print(match_obj.group(1)) #\s代表空格
line="你 好"
regex_str="(你\s好)"
match_obj=re.match(regex_str,line)
if match_obj:
print(match_obj.group(1)) #\S 表示除了空格都可以
line="你a好"
regex_str="(你\S好)"
match_obj=re.match(regex_str,line)
if match_obj:
print(match_obj.group(1)) #\w 作用匹配[A-Za-z0-9_],\W作用相反
line="你a好"
regex_str="(你\W好)"
match_obj=re.match(regex_str,line)
if match_obj:
print(match_obj.group(1)) #[\u4E00-\u9FA5] 提取中文
line="你a好"
regex_str=".*?([\u4E00-\u9FA5])" #非贪婪模式 从左开始匹配
match_obj=re.match(regex_str,line)
if match_obj:
print(match_obj.group(1)) #
line = "xxx2000年"
regex_str = ".*(\d)年"#这个只获取到了0怎么获取全部呢?方法一是加?,方法二加上{4}
match_obj = re.match(regex_str, line)
if match_obj:
print(match_obj.group(1))
小练习:匹配下面的出生日期
line="xxx出生于2001年6月"
line="xxx出生于2001/6/1"
line="xxx出生于2001-6-1"
line="xxx出生于2001-06-01"
line="xxx出生于2001-06"
regex_str=".*出生于(\d{4}[年/-]\d{1,2}([月/-]\d{1,2}|[月/-]$|$))"
match_obj=re.match(regex_str,line)
if match_obj:
print(match_obj.group(1))
re.match和re.compile()
import re
#3位数字-3到8个数字 \d{3}-\d{3-8} #下面如果匹配成功就打印出来
m=re.match(r"\d{3}-\d{3,8}","010-222346512")
print(m.string) #分组
m=re.match(r"(\d{3})-(\d{3,8})","010-1231231")
print(m.group(0)) #原始结果
print(m.group(1)) #第一个分组括号
print(m.group(2))
print(m.groups()) #把所有的组全部放到元祖里面 #匹配时分秒
t='20:15:45'
m=re.match(r'^(0[0-9]|1[0-9]|2[0-9|[0-9])\:(0[0-9]|1[0-9]|2[0-9|3[0-9]|4[0-9]|5[0-9]|[0-9])\:(0[0-9]|1[0-9]|2[0-9]|3[0-9]|4[0-9]|5[0-9]|[0-9])$',t) #注意这里:要去掉特殊含义,$结尾后面的引号不能有空格
print(m.groups()) #分割字符串
p=re.compile(r'\d+') #compile就是把一个模式编译好,然后拿着这个模式到处匹配
print(p.split("sdaasd1321321"))
第八篇、正则表达式 re模块的更多相关文章
- Python之路【第八篇】:Python模块
阅读目录 一.模块和包 模块(module)的概念: 在计算机程序的开发过程中,随着程序代码越写越多,在一个文件里代码会越来越长,越来越不容易维护. 为了编写可维护的代码,我们把很多函数分组,分别放到 ...
- python学习【第八篇】python模块
模块与包 模块的概念 在python中一个.py文件就是一个模块. 使用模块可以提高代码的可维护性. 模块分为三种: python标准库 第三方模块 自定义模块 模块的导入方法 1.import语句 ...
- 【黑金原创教程】【FPGA那些事儿-驱动篇I 】实验八:PS/2模块② — 键盘与组合键
实验八:PS/2模块② — 键盘与组合键 实验七之际,我们学习如何读取PS/2键盘发送过来的通码与断码,不过实验内容也是一键按下然后释放,简单按键行为而已.然而,实验八的实验内容却是学习组合键的按键行 ...
- Python之路【第十八篇】:Web框架们
Python之路[第十八篇]:Web框架们 Python的WEB框架 Bottle Bottle是一个快速.简洁.轻量级的基于WSIG的微型Web框架,此框架只由一个 .py 文件,除了Pytho ...
- Python之路【第八篇】:堡垒机实例以及数据库操作
Python之路[第八篇]:堡垒机实例以及数据库操作 堡垒机前戏 开发堡垒机之前,先来学习Python的paramiko模块,该模块机遇SSH用于连接远程服务器并执行相关操作 SSHClient ...
- python正则表达式Re模块备忘录
title: python正则表达式Re模块备忘录 date: 2019/1/31 18:17:08 toc: true --- python正则表达式Re模块备忘录 备忘录 python中的数量词为 ...
- 洗礼灵魂,修炼python(69)--爬虫篇—番外篇之feedparser模块
feedparser模块 1.简介 feedparser是一个Python的Feed解析库,可以处理RSS ,CDF,Atom .使用它我们可从任何 RSS 或 Atom 订阅源得到标题.链接和文章的 ...
- Flask最强攻略 - 跟DragonFire学Flask - 第八篇 实例化Flask的参数 及 对app的配置
Flask 是一个非常灵活且短小精干的web框架 , 那么灵活性从什么地方体现呢? 有一个神奇的东西叫 Flask配置 , 这个东西怎么用呢? 它能给我们带来怎么样的方便呢? 首先展示一下: from ...
- ElasticSearch入门 第八篇:存储
这是ElasticSearch 2.4 版本系列的第八篇: ElasticSearch入门 第一篇:Windows下安装ElasticSearch ElasticSearch入门 第二篇:集群配置 E ...
- 跟我学SpringCloud | 第八篇:Spring Cloud Bus 消息总线
SpringCloud系列教程 | 第八篇:Spring Cloud Bus 消息总线 Springboot: 2.1.6.RELEASE SpringCloud: Greenwich.SR1 如无特 ...
随机推荐
- 微信小程序 模块化
模块化也就是将一些通用的东西抽出来放到一个文件中,通过module.exports去暴露接口.我们在最初新建项目时就有个util.js文件就是被模块化处理时间的 /** * 处理具体业务逻辑 */ f ...
- 高通音频 媒体喇叭增益隐藏参数(一个QACT无法修改的参数)
源文件位置:modem_proc\multimedia\audio\avs\src\sndhwg2.c sndhw_init()函数,2520行左右:pm_set_speaker_gain(PM_SP ...
- 非常实用的JavaScript小技巧
使用!!操作符转换布尔值 有时候我们需要对一个变量查检其是否存在或者检查值是否有一个有效值,如果存在就返回true值.为了做这样的验证,我们可以使用!!操作符来实现是非常的方便与简单.对于变量可以使用 ...
- Android开发:《Gradle Recipes for Android》阅读笔记(翻译)4.2——增加自定义task
问题: 你想要在整体的构建过程中加入自定义的task. 解决方案: 使用dependOn属性将你的任务插入 directed acyclic graph 讨论: 在初始化阶段,Gradle将任务根据依 ...
- uva 12730(期望经典)
选自: http://blog.csdn.net/myhelperisme/article/details/39724515 用dp(n)表示有n个位置时的期望值,那么,对于一个刚进来的人来说,他有 ...
- VMware Workstation 虚拟机纯 Linux 终端如何安装 VMware Tools ?
VMware Workstation 虚拟机纯 Linux 终端如何安装 VMware Tools ? 1.首先在虚拟机设置里面设置一个共享文件夹 2.在虚拟机菜单栏中选择 VMware Tools ...
- 0x01 MySQL What's DataBase
0x01 数据库管理软件的由来 在此之前,数据要想永久保存,都是保存于文件中,毫无疑问,一个文件仅仅能存在于某一台机器上. 如果暂且忽略直接基于文件来存取数据的效率问题,并且假设程序所有的组件都运行在 ...
- 怎样使用Chrome模拟手机浏览器測试移动端网站
作者:zhanhailiang 日期:2014-10-10 环境说明: Chrome 37.0.2062.124 m 1. 通过[菜单→工具→开发人员工具|Javascript控制台]或[快捷键Ctr ...
- xml数据发送请求,读取xml
# coding:utf-8 import requests url = "http://httpbin.org/post" # python3字符串换行,在右边加个反斜杠 bod ...
- 鸟哥的Linux私房菜-第一部分-第2章Linux如何学习
第2章 Linux如何学习 Linux可以干什么 企业级:网络服务器.金融数据库.大型企业网管环境.高性能计算.集群 个人:桌面计算机.手机.PDA(掌上电脑,这个电脑的意义十分广泛,在不同的场景下有 ...