elasticsearch5.6.8中文分词器
安装分词器,务必确保版本一致!
下载地址:https://github.com/medcl/elasticsearch-analysis-ik
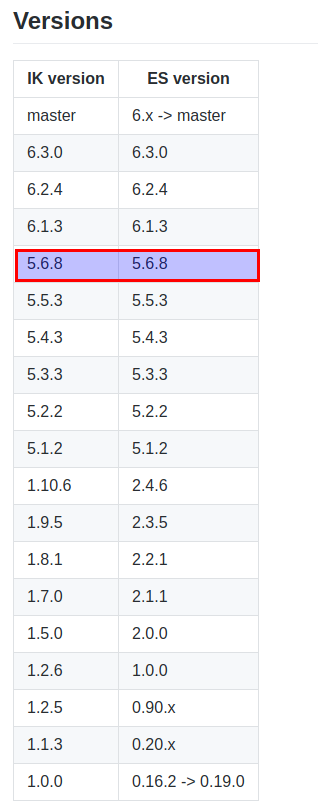
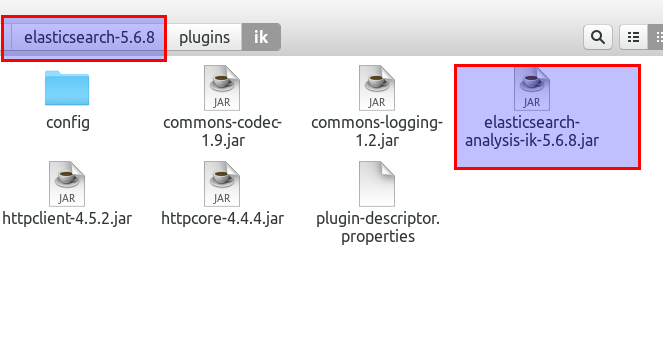
为了保证一致,我特地将elasticsearch进行降级。
ik_smart
GET _analyze?pretty
{
"analyzer": "ik_smart",
"text": "中华人民共和国国歌"
}
{
"tokens": [
{
"token": "中华人民共和国",
"start_offset": 0,
"end_offset": 7,
"type": "CN_WORD",
"position": 0
},
{
"token": "国歌",
"start_offset": 7,
"end_offset": 9,
"type": "CN_WORD",
"position": 1
}
]
}
ik_max_word
GET _analyze?pretty
{
"analyzer": "ik_max_word",
"text": "中华人民共和国国歌"
}
{
"tokens": [
{
"token": "中华人民共和国",
"start_offset": 0,
"end_offset": 7,
"type": "CN_WORD",
"position": 0
},
{
"token": "中华人民",
"start_offset": 0,
"end_offset": 4,
"type": "CN_WORD",
"position": 1
},
{
"token": "中华",
"start_offset": 0,
"end_offset": 2,
"type": "CN_WORD",
"position": 2
},
{
"token": "华人",
"start_offset": 1,
"end_offset": 3,
"type": "CN_WORD",
"position": 3
},
{
"token": "人民共和国",
"start_offset": 2,
"end_offset": 7,
"type": "CN_WORD",
"position": 4
},
{
"token": "人民",
"start_offset": 2,
"end_offset": 4,
"type": "CN_WORD",
"position": 5
},
{
"token": "共和国",
"start_offset": 4,
"end_offset": 7,
"type": "CN_WORD",
"position": 6
},
{
"token": "共和",
"start_offset": 4,
"end_offset": 6,
"type": "CN_WORD",
"position": 7
},
{
"token": "国",
"start_offset": 6,
"end_offset": 7,
"type": "CN_CHAR",
"position": 8
},
{
"token": "国歌",
"start_offset": 7,
"end_offset": 9,
"type": "CN_WORD",
"position": 9
}
]
}
elasticsearch5.6.8中文分词器的更多相关文章
- ElasticSearch速学 - IK中文分词器远程字典设置
前面已经对”IK中文分词器“有了简单的了解: 但是可以发现不是对所有的词都能很好的区分,比如: 逼格这个词就没有分出来. 词库 实际上IK分词器也是根据一些词库来进行分词的,我们可以丰富这个词库. ...
- ElasticSearch安装中文分词器IK
1.安装IK分词器,下载对应版本的插件,elasticsearch-analysis-ik中文分词器的开发者一直进行维护的,对应着elasticsearch的版本,所以选择好自己的版本即可.IKAna ...
- solr服务中集成IKAnalyzer中文分词器、集成dataimportHandler插件
昨天已经在Tomcat容器中成功的部署了solr全文检索引擎系统的服务:今天来分享一下solr服务在海量数据的网站中是如何实现数据的检索. 在solr服务中集成IKAnalyzer中文分词器的步骤: ...
- 11大Java开源中文分词器的使用方法和分词效果对比
本文的目标有两个: 1.学会使用11大Java开源中文分词器 2.对比分析11大Java开源中文分词器的分词效果 本文给出了11大Java开源中文分词的使用方法以及分词结果对比代码,至于效果哪个好,那 ...
- 转:solr6.0配置中文分词器IK Analyzer
solr6.0中进行中文分词器IK Analyzer的配置和solr低版本中最大不同点在于IK Analyzer中jar包的引用.一般的IK分词jar包都是不能用的,因为IK分词中传统的jar不支持s ...
- 我与solr(六)--solr6.0配置中文分词器IK Analyzer
转自:http://blog.csdn.net/linzhiqiang0316/article/details/51554217,表示感谢. 由于前面没有设置分词器,以至于查询的结果出入比较大,并且无 ...
- Solr入门之(8)中文分词器配置
Solr中虽然提供了一个中文分词器,但是效果很差,可以使用IKAnalyzer或Mmseg4j 或其他中文分词器. 一.IKAnalyzer分词器配置: 1.下载IKAnalyzer(IKAnalyz ...
- Solr学习笔记之2、集成IK中文分词器
Solr学习笔记之2.集成IK中文分词器 一.下载IK中文分词器 IK中文分词器 此文IK版本:IK Analyer 2012-FF hotfix 1 完整分发包 二.在Solr中集成IK中文分词器 ...
- solr4.7中文分词器(ik-analyzer)配置
solr本身对中文分词的处理不是太好,所以中文应用很多时候都需要额外加一个中文分词器对中文进行分词处理,ik-analyzer就是其中一个不错的中文分词器. 一.版本信息 solr版本:4.7.0 需 ...
随机推荐
- yii2:不使用composer安装yii2-jui的方法
今天有一个功能需要用到autocomplete,既然用yii2开发,在这里当然使用它自带的yii2-jui中的autocomplete组件了.yii2basic版默认是没有yii2-jui组件的,需要 ...
- 前端读取Excel报表文件 js-xlsx
1.http://www.cnblogs.com/imwtr/p/6001480.html (前端读取Excel报表文件) 2.https://github.com/SheetJS/js-xlsx
- 有云Ceph课堂:使用CivetWeb快速搭建RGW
转自:https://www.ustack.com/blog/civetweb/ 优秀的开源项目正在改变传统IT,OpenStack名头最响,已经成为了IaaS的事实标准.Ceph同样颇有建树,通过其 ...
- 双系统在Linux下查看win的硬盘(Ubuntu 16.04 挂载Windows的 硬盘)
一般情况下,Linux的桌面系统能够直接查看到计算机各个硬盘的文件情况 但是,当我们想通过命令行查看Windows下的硬盘的时候,会发现在 /media/ (一般Windows下的盘会挂载到这里)文件 ...
- 【spark】示例:二次排序
我们有这样一个文件 首先我们的思路是把输入文件数据转化成键值对的形式进行比较不就好了嘛! 但是你要明白这一点,我们平时所使用的键值对是不具有比较意义的,也就说他们没法拿来直接比较. ...
- .html() .text() .val() 的区别
.html()用为读取和修改元素的HTML标签(包括其Html标签) .text()用来读取或修改元素的纯文本内容 (包括其后代元素) .val()用来读取或修改表单元素的value值.(只能用于表单 ...
- 【2018年全国多校算法寒假训练营练习比赛(第五场)-C】字符串问题(KMP)
题目链接:https://www.nowcoder.com/acm/contest/77/C [题意] 求一个字符串中最长的子串,要求子串既是原串的前缀又是后缀,除前后缀还在中间出现过. [思路] K ...
- redis memcache rabbitMQ
Python之路[第九篇]:Python操作 RabbitMQ.Redis.Memcache.SQLAlchemy Memcached Memcached 是一个高性能的分布式内存对象缓存系统,用于动 ...
- Flask--信号 blinker
Flask--信号 blinker Flask框架中的信号基于blinker,可以让开发者在flask请求过程中 定制一些用户行为执行. 在请求前后,模板渲染前后,上下文前后,异常 的时候 安装: p ...
- 网站 安全 ---- 常见的 web 攻击
网站 安全 ---- 常见的 web 攻击 1 sql 注入(常用的攻击性)(django的orm是做过sql防护处理的) 危害: 非法读取,篡改,删除数据库中的数据 盗取用户的各类敏感信息.获取利益 ...