Hadoop2.x伪分模式部署
hadoop伪分布模式,只有一个节点,通常用来做测试。
一、环境准备
二、创建Hadoop用户(以后有关集群的操作都只用此用户);
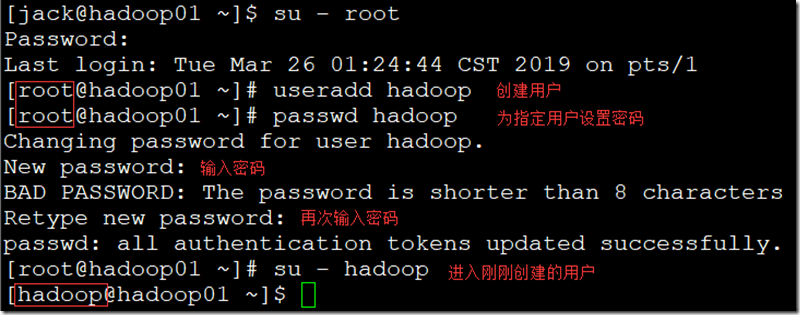
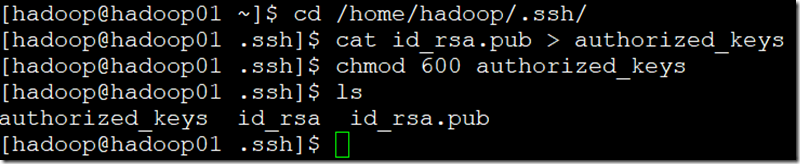
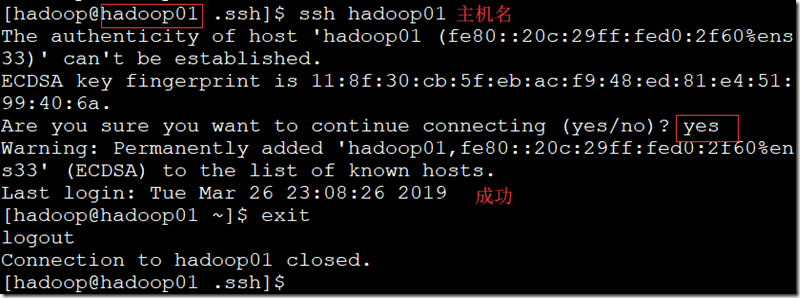
三、配置SSH互相(免密登录);

四、解压Hadoop安装包;


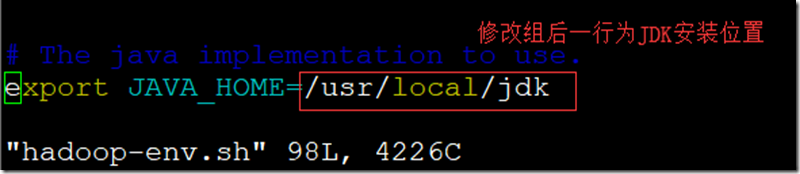
五、修改配置文件;
- 修改hadoop-env.sh,配置jdk位置;

- 修改core-site.xml;

- hdfs-site.xml配置;

- 配置Mapreduce调用方式;

- yarn有关的配置;

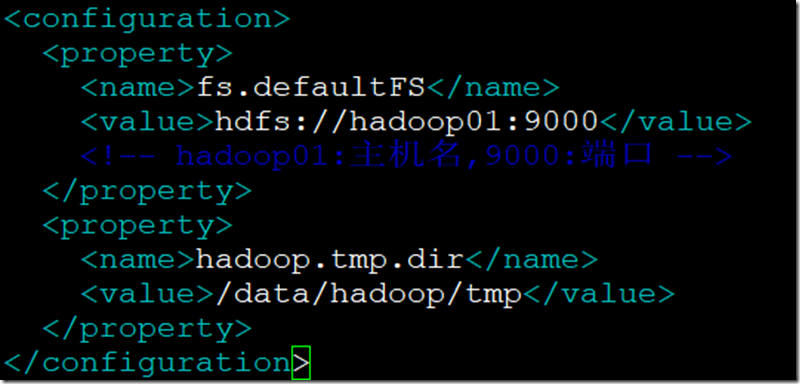
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:9000</value>
<!—- hadoop01:主机名,9000:端口 -->
</property> <property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop/tmp</value>
</property>
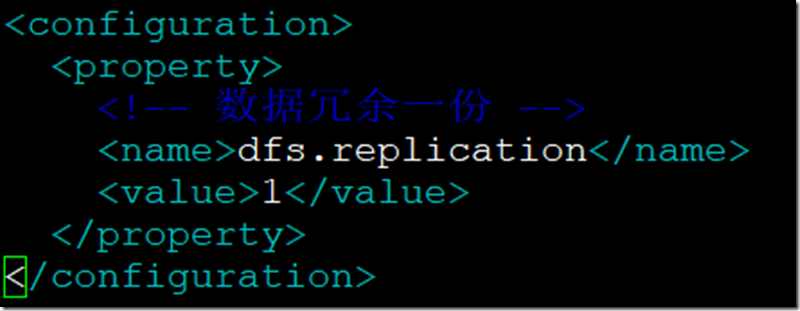
<property>
<!-- 数据冗余一份 -->
<name>dfs.replication</name>
<value>1</value>
</property>
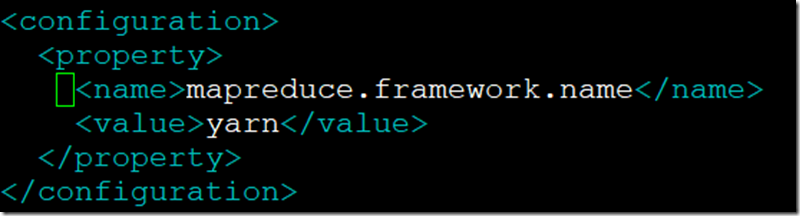
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
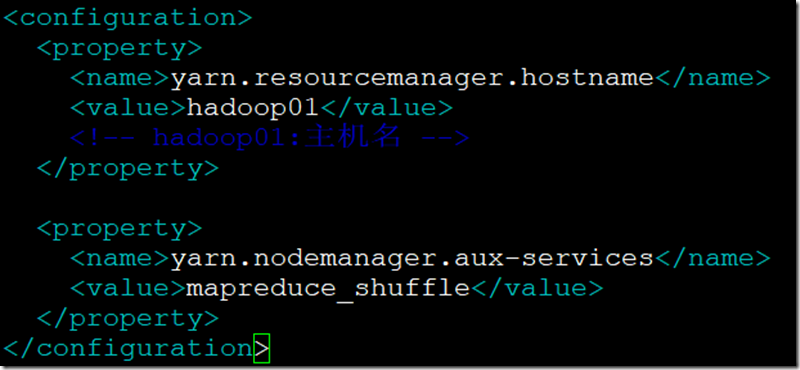
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
<!—hadoop01:主机名 -->
</property> <property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
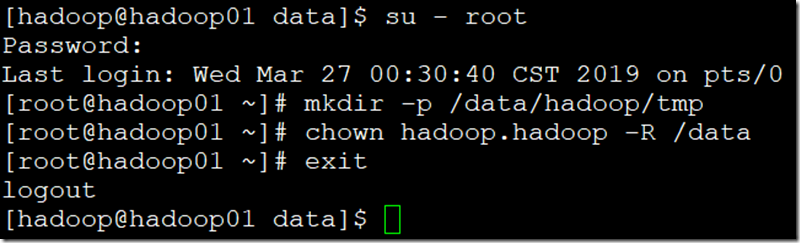
六、创建Hadoop数据目录(su到root用户下);
- su – root
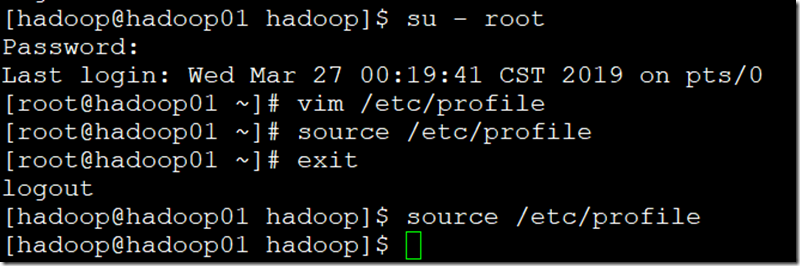
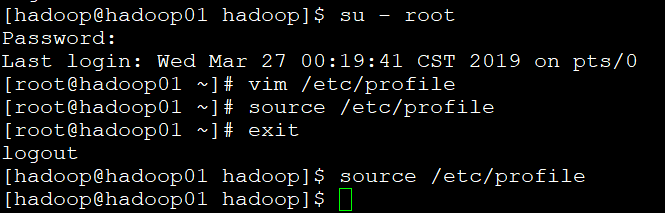
七、配置系统环境变量;
- 在root用户下修改环境变量,并使生效;
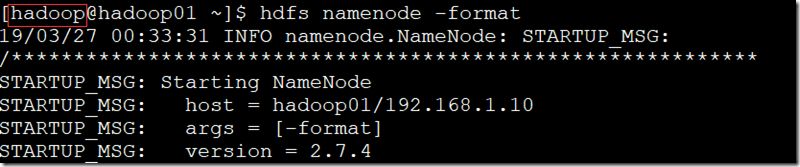
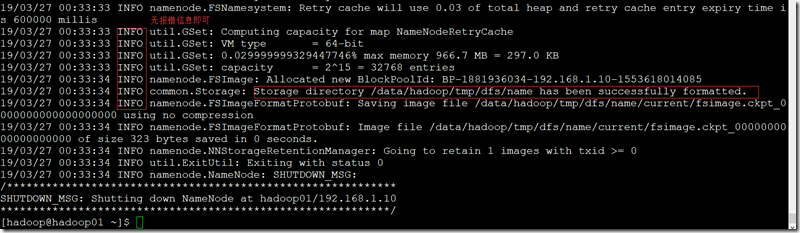
八、格式化namenode节点(注意:只能格式化一次);
- 在hodoop用户下,格式化namenode(执行一次命令即可);
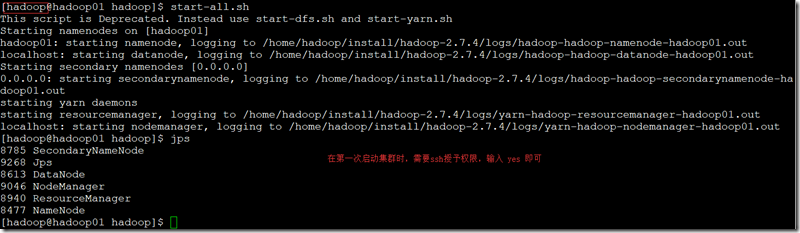
九、启动集群;
- 使用hadoop用户启动集群;
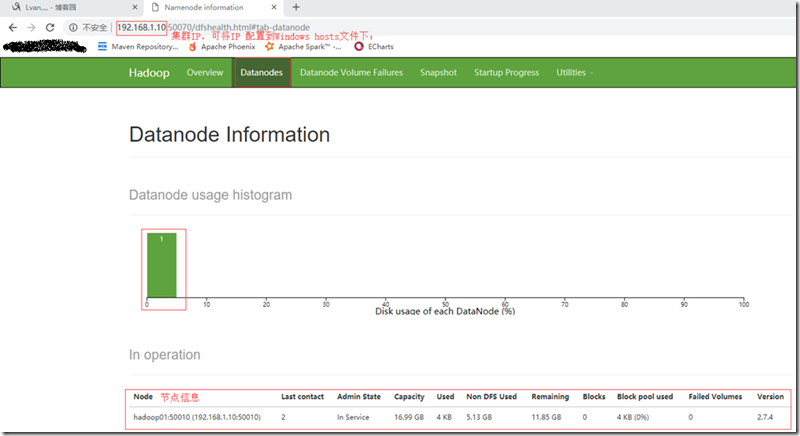
十、验证集群是否部署成功;
- 从Windows访问HDFS页面;
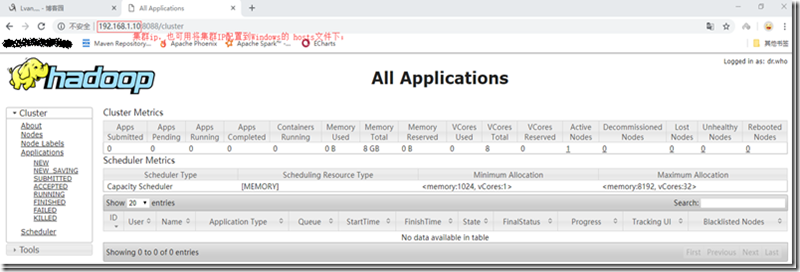
- 从Windows访问yarn页面;
停止集集群:
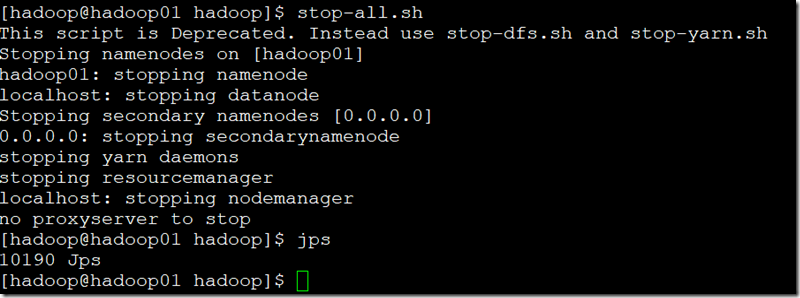
能出来以上界面,表明伪分布模式部署成功;
Hadoop2.x伪分模式部署的更多相关文章
- Hadoop伪分布式模式部署
Hadoop的安装有三种执行模式: 单机模式(Local (Standalone) Mode):Hadoop的默认模式,0配置.Hadoop执行在一个Java进程中.使用本地文件系统.不使用HDFS, ...
- 初学者值得拥有【Hadoop伪分布式模式安装部署】
目录 1.了解单机模式与伪分布模式有何区别 2.安装好单机模式的Hadoop 3.修改Hadoop配置文件---五个核心配置文件 (1)hadoop-env.sh 1.到hadoop目录中 2.修 ...
- zookeeper集群&伪集群模式部署
1.什么是单机部署 一台服务器上面部署一个单机版本的zookeeper服务,用于提供服务. 2.什么是集群部署? 集群部署就是多台服务器上面各部署单独的一个zookeeper服务,然后组建一个集群 3 ...
- 分布式集群HA模式部署
一:HDFS系统架构 (一)利用secondary node备份实现数据可靠性 (二)问题:NameNode的可用性不高,当NameNode节点宕机,则服务终止 二:HA架构---提高NameNode ...
- 3-2 Hadoop集群伪分布模式配置部署
Hadoop伪分布模式配置部署 一.实验介绍 1.1 实验内容 hadoop配置文件介绍及修改 hdfs格式化 启动hadoop进程,验证安装 1.2 实验知识点 hadoop核心配置文件 文件系统的 ...
- 一脸懵逼学习Hadoop分布式集群HA模式部署(七台机器跑集群)
1)集群规划:主机名 IP 安装的软件 运行的进程master 192.168.199.130 jdk.hadoop ...
- spark 源码编译 standalone 模式部署
本文介绍如何编译 spark 的源码,并且用 standalone 的方式在单机上部署 spark. 步骤如下: 1. 下载 spark 并且解压 本文选择 spark 的最新版本 2.2.0 (20 ...
- Spark运行模式与Standalone模式部署
上节中简单的介绍了Spark的一些概念还有Spark生态圈的一些情况,这里主要是介绍Spark运行模式与Spark Standalone模式的部署: Spark运行模式 在Spark中存在着多种运行模 ...
- Hadoop伪分布模式配置部署
.实验环境说明 注意:本实验需要按照上一节单机模式部署后继续进行操作 1. 环境登录 无需密码自动登录,系统用户名 shiyanlou,密码 shiyanlou 2. 环境介绍 本实验环境采用带桌面的 ...
随机推荐
- PLSQL导出语句的查询结果
不需要把全部结果都展示出来
- Docker Community Edition 镜像使用帮助
1.什么是Docker 容器技术 在计算机的世界中,容器拥有一段漫长且传奇的历史.容器与管理程序虚拟化 (hypervisor virtualization,HV)有所不同,管理程序虚拟化通过中间层将 ...
- [BZOJ 4850][Jsoi2016]灯塔
传送门 #include <bits/stdc++.h> using namespace std; #define rep(i,a,b) for(int i=a;i<=b;++i) ...
- Intelligent Poetry
Readme: Creat poems. import re import random from collections import Counter def Creat_Poem(number): ...
- SCU - 4439 最小点覆盖
题意:求最小的染色顶点数满足所有的边至少有个一端点被染色 2015四川省赛,过题数17/120+,还以为是什么难题,这不就是裸的二分图最小点覆盖吗.. 掏出了尘封一年的破板子 #include< ...
- UVA - 11795 状压DP
#include<iostream> #include<algorithm> #include<cstdio> #include<cstring> #i ...
- ZOJ - 3624
当A连向C,B连向D时存在相交路径 #include<bits/stdc++.h> #define rep(i,j,k) for(int i=j;i<=k;i++) #define ...
- ECharts 雷达图怎么在类目值下面显示数值
需要实现的效果: 官网里面的demo显示数值,都是在拐点处: [解决] 1.只显示类目 <div id="mychart" style="width:300px;h ...
- Python Flask框架之页面跳转
IDE用的PyCharm(还是vs强大啊). 项目结构: 2:页面: <!doctype html> <html lang="zh"> <head&g ...
- if __name__ == '__main__' 详解
1.__name__是啥 __name__ 是Python的模块名字. 手册解释:The name of the module. 2.__name__的值 首先,一个变量一次只有一个值. 其次,__n ...