Python爬虫丨大众点评数据爬虫教程(1)
大众点评数据获取 --- 基础版本
大众点评是一款非常受普罗大众喜爱的一个第三方的美食相关的点评网站。
因此,该网站的数据也就非常有价值。优惠,评价数量,好评度等数据也就非常受数据公司的欢迎。
今天就写了一个简单的大众点评列表页数据抓取demo。
希望对看到这篇文章的朋友有所帮助。
- 环境和工具包:
- python 3.6
- 自建的IP代理池(使用的是ipidea的国内代理)
- parsel(页面解析)
- loguru(报错提示)
下面就让我看开启探索之旅
第一步,页面解析
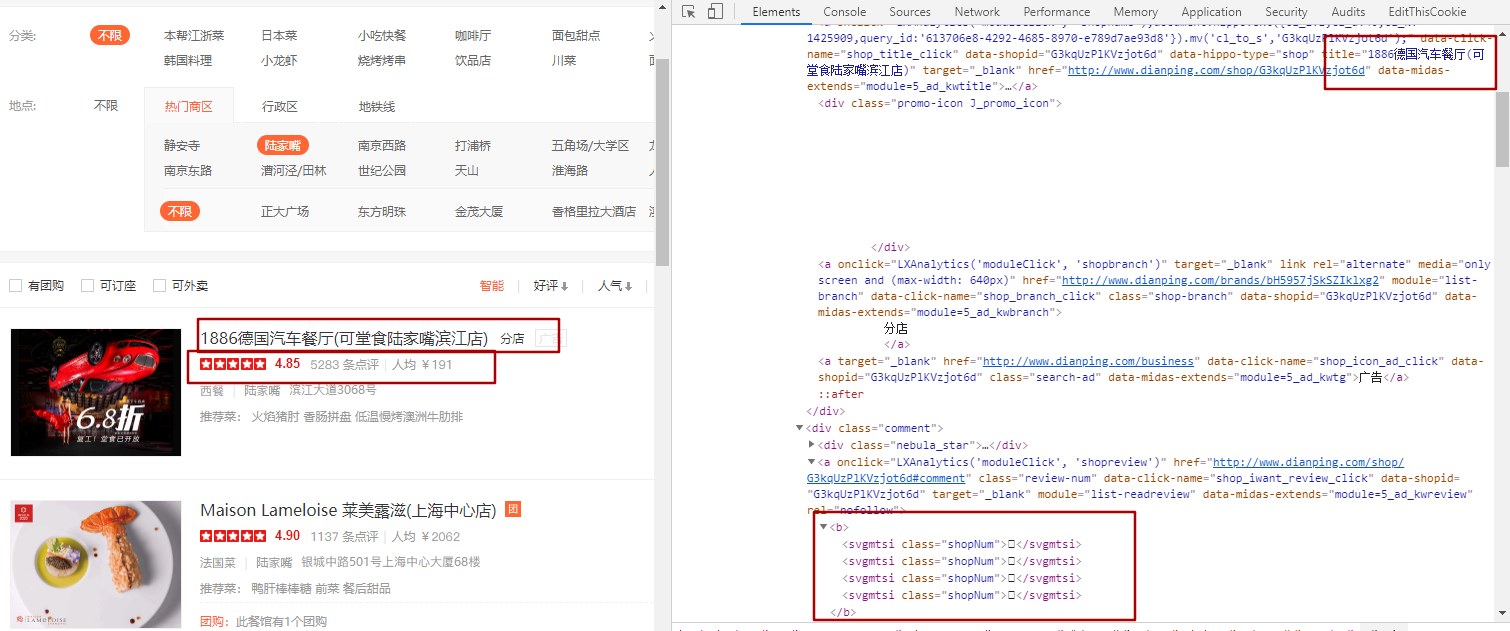
从图中可以看到,对应的数字都是方框。那具体是什么呢?
下图是我简单处理后,控制台输出的内容。以及直接在html中右键查看网页源码


由此可以看到下面连个内容
{'名称': 'Maison Lameloise 莱美露滋(上海中心店)', '评分': '4.90', '评价数': '11\ueeb5\ue753', '人均花费': '¥\uf802\uf0b6\ue753\ue867', '推荐': ['鸭肝棒棒糖', '前菜', '餐后甜品']}
<b>11<svgmtsi class="shopNum"></svgmtsi><svgmtsi class="shopNum"></svgmtsi></b>
<b>¥<svgmtsi class="shopNum"></svgmtsi><svgmtsi class="shopNum"></svgmtsi><svgmtsi class="shopNum"></svgmtsi><svgmtsi class="shopNum"></svgmtsi></b>
也就是说,评价数据和人均消费价格数据,都应经被隐藏了。
这种方式焦作svg映射。
那么该怎么搞定这些数据呢。
首先我们需要找到网页打开后,他们所引用的woff字体文件。
在F12中,选中Network,然后再次选中第三行菜单栏中的Font。现在,在杂论的网络访问内容中,就只有几个woff文件了。
下一步就是打开这个文件了。
打开的方式有两种
方式一:
首先下载好目标woff,直接右键这个访问内容,选中"Open in new tab"就会下载这个woff文件
打开https://www.fontke.com/tool/convfont/这个地址,在线转换成ttf文件
打开http://fontstore.baidu.com/static/editor/index.html这个地址,在线解析刚打开的ttf文件
会看到这种:
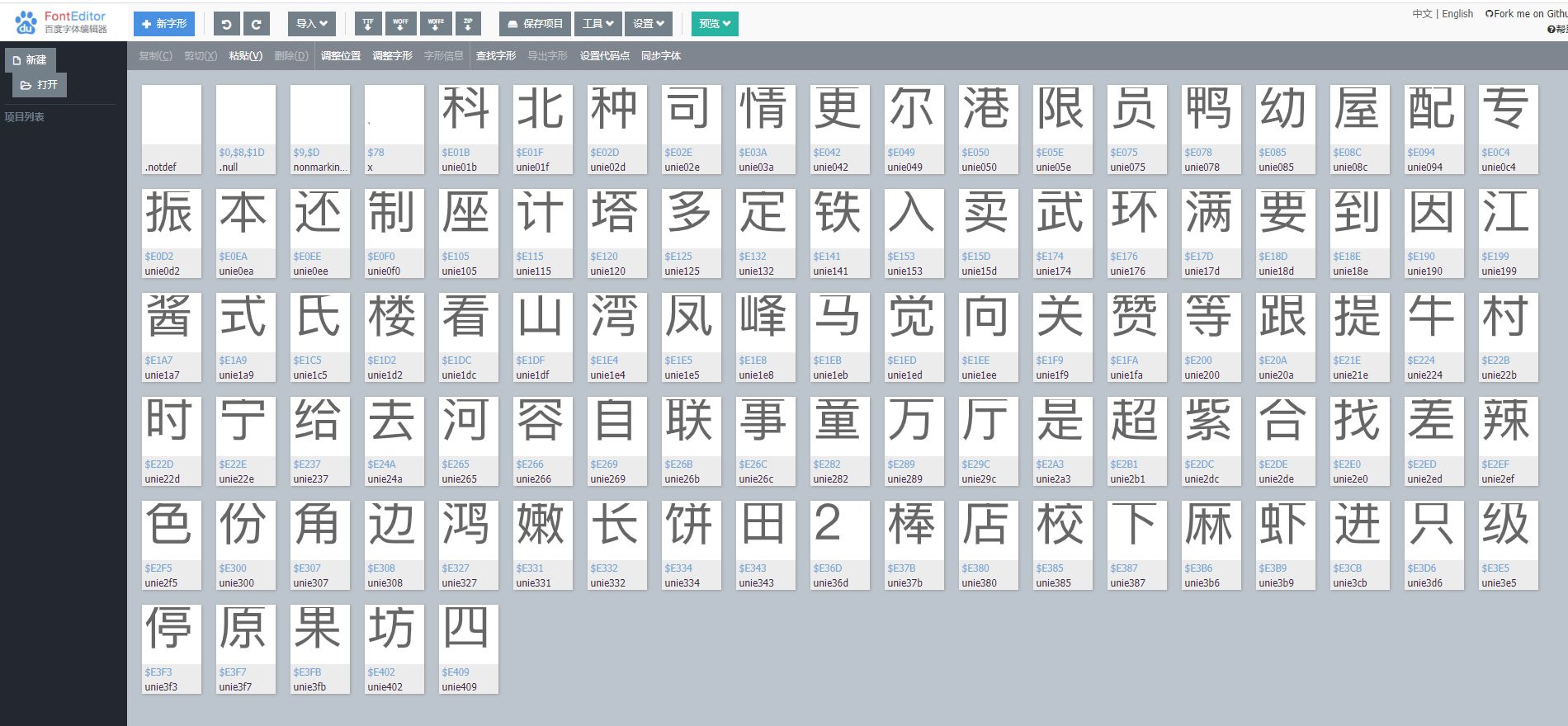
通过查找字形:
通过观察,我们看到在百度字体解析的文字代码中,都是以“unie”开头的,那么我们将之前看到的编码内容组合后进入字体文件中搜索,就可以验证该编码是否正确对应网页显示的数字了。
比如
 我们通过一一对应,很容易就知道“\ueeb5”是3,“\ue753”是7,还为什么要费尽做这个呢。
我们通过一一对应,很容易就知道“\ueeb5”是3,“\ue753”是7,还为什么要费尽做这个呢。目的有两个,一个是验证这种设想,还有一种是为了下一篇复杂篇的内容埋个伏笔。

果真,在其中一个文件中找到了对应的字符编码,说明想法没有错误
方式二:
需要安装fontTools包,没安装的请(pip install fontTools) from fontTools.ttLib import TTFont def get_xml(self): font = TTFont('dzdp.woff') font.saveXML('dzdp.xml')- 执行上述方法(和脚本放在同一目录下,改好名字),就会得到一个xml文件,然后用工具打开这个xml文件,直接全局搜索eeb5,很快就会定位到这么一行。从而就会很清楚的了解到。页面中的0xeeb5和ttf文件中的unieeb5是意义对应关系。也就再次证明了0xxeb5就是数字3
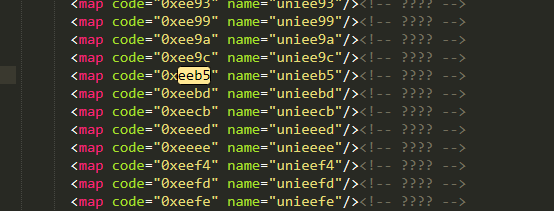
构造映射字典
从刚才的页面解析中,我们已经明白了“\ueeb5”是3,“\ue753”是7,那么咱们再次在页面中找到其他的相关数字,【0-9】十个数字很容易就组合出来了。记住,1不需要重构,。
self.woff = { "\uf0b6": "0", # "": "1", "\uf802": "2", "\ueeb5": "3", "\ueb5e": "4", "\uf508": "5", "\ue867": "6", "\ue753": "7", "\uf0a6": "8", "\uf506": "9", } 不要正对着数据抄写,点评的字体svg经常改变。需要自己对应当时的情况写一下省下的就是直接处理数据和解析数据了。
内容如下:
def get_count(self, uncode_list): try: count = "" for uncode in uncode_list: uncodes_ = uncode.replace('<svgmtsi class="shopNum"', "").replace("</svgmtsi", "").replace("</b>", "").replace( "</b>", "").replace("<b>", "").split('>') # pprint.pprint(uncodes_) for uncs in uncodes_: if uncs in self.woff.keys(): cc = self.woff[uncs] else: cc = uncs count += cc return count except Exception as e: logger.info("数字解析出现错误") return uncode_list[0] def run(self): url = 'http://www.dianping.com/shanghai/ch10/r801' html = self.get_html(url) shop_el_list = html.css("#shop-all-list li") for shop_info in shop_el_list: item = {} shop_name = shop_info.css("div.txt div.tit a::attr(title) ").extract_first() item["名称"] = shop_name score = shop_info.css("div.txt div.comment div.nebula_star div.star_score::text").extract_first() item["评分"] = score review_num = shop_info.css("div.txt div.comment>a.review-num > b ").extract() item["评价数"] = self.get_count(review_num) mean_price = shop_info.css("div.txt div.comment>a.mean-price > b ").extract() item["人均花费"]=self.get_count(mean_price) # item["类型"] # item["地址"] recommend = shop_info.css("div.txt div.recommend>a::text").extract() item["推荐"] = recommend print(item)上述代码就是这个demo中最关键的两个内容,一个是逻辑,一个是数字解析。这里我就不费口舌进行一一解释了。同学们自己看下吧。
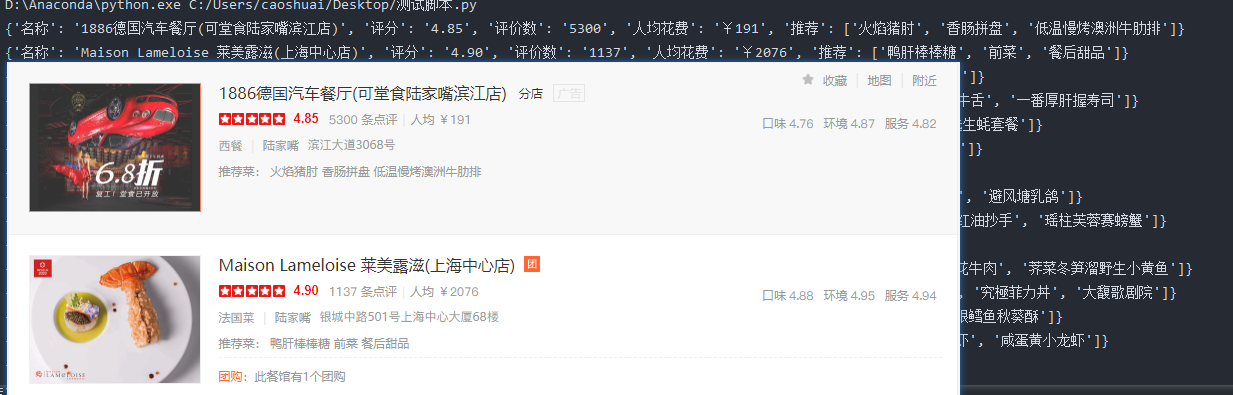
成果展示
存在的缺点
如果点评换了一版映射,咱们就要重新做一次字典集合
只是简单的对【0-9】十个数字的映射做了解析。我想拿文字怎么办?
我的demo中就有类型和地址两个字段没有进行数据填充,因为这两个字段就是有文字映射的,这个问题会在下一篇中进行解答。
同时也会解决点评网站换动态字体该怎么解决的。
咱们Python爬虫丨大众点评数据爬虫教程(2)见~~~
本文章旨在用于交流分享,【未经允许,谢绝转载】
Python爬虫丨大众点评数据爬虫教程(1)的更多相关文章
- Python爬虫丨大众点评数据爬虫教程(2)
大众点评数据爬虫获取教程 --- [SVG映射版本] 前言: 大众点评是一款非常受大众喜爱的一个第三方的美食相关的点评网站.从网站内可以推荐吃喝玩乐优惠信息,提供美食餐厅.酒店旅游.电影票.家居装修. ...
- 用Python爬取大众点评数据,推荐火锅店里最受欢迎的食品
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者:有趣的Python PS:如有需要Python学习资料的小伙伴可以加点 ...
- Python数据分析:大众点评数据进行选址
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者:砂糖侠 如果你处于想学Python或者正在学习Python,Pyth ...
- Python 爬取大众点评 50 页数据,最好吃的成都火锅竟是它!
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: 胡萝卜酱 PS:如有需要Python学习资料的小伙伴可以加点击下方链 ...
- 【Python3爬虫】大众点评爬虫(破解CSS反爬)
本次爬虫的爬取目标是大众点评上的一些店铺的店铺名称.推荐菜和评分信息. 一.页面分析 进入大众点评,然后选择美食(http://www.dianping.com/wuhan/ch10),可以看到一页有 ...
- python爬取大众点评
拖了好久的代码 1.首先进入页面确定自己要抓取的数据(我们要抓取的是左侧分类栏-----包括美食.火锅)先爬取第一级分类(美食.婚纱摄影.电影),之后根据第一级链接爬取第二层(火锅).要注意第二级的p ...
- python爬取大众点评并写入mongodb数据库和redis数据库
抓取大众点评首页左侧信息,如图: 我们要实现把中文名字都存到mongodb,而每个链接存入redis数据库. 因为将数据存到mongodb时每一个信息都会有一个对应的id,那样就方便我们存入redis ...
- python python 入门学习之网页数据爬虫cnbeta文章保存
需求驱动学习的动力. 因为我们单位上不了外网所以读新闻是那么的痛苦,试着自己抓取网页保存下来,然后离线阅读.今天抓取的是cnbeta科技新闻,抓取地址是http://m.cnbeta.com/wap/ ...
- python python 入门学习之网页数据爬虫搜狐汽车数据库
自己从事的是汽车行业,所以首先要做的第一个程序是抓取搜狐汽车的销量数据库(http://db.auto.sohu.com/cxdata/): 数据库提供了07年至今的汽车月销量,每个车型对应一个xml ...
随机推荐
- 记一个openwrt reboot异步信号处理死锁问题
写在前面 觉得本页面排版单调的话,可以尝试到这里看. 问题背景 在 openwrt 上碰到了一个偶现的 reboot 失效问题.执行 reboot 之后系统并没有重启,此时控制台还能工作. 初步排查 ...
- Daily Scrum 12/24/2015
Process: Zhaoyang: Some UI change and compile the Caffe in the IOS. Yandong: Do some code integratio ...
- JavaScript函数作用域和声明提前(3.10.1 page.57)
<h4>3.函数作用域和声明提前</h4> <p> <!--<script type="text/javascript">-- ...
- react-devtools安装调试
初学react,Chrome F12调试,需要一款插件react-devtools. 网上大多对于翻墙不利索的同学大多才用了git源码.npm本地手动打包Chrome拓展程序.如:https://ww ...
- Java 基础讲解
Hello,老同学们,又见面啦,新同学们,你们好哦! 在看完本人的<数据结构与算法>专栏的博文的老同学,恭喜你们在学习本专栏时,你们将会发现好多知识点都讲解过,都易于理解,那么,没看过的同 ...
- 如何将Python项目发布到PyPI
The Python Package Index (PyPI) is a repository of software for the Python programming language. 如何打 ...
- Python软件定时器APScheduler使用【软件定时器,非操作系统定时器,软件可控的定时器】【用途:定时同步数据库和缓存等】【刘新宇】
APScheduler使用 APScheduler (advanceded python scheduler)是一款Python开发的定时任务工具. 文档地址 https://apscheduler. ...
- python之实现图像的手绘效果
https://blog.csdn.net/riba2534/article/details/74152285 原图: b: c: d: 最终图:
- 笔记本安装ubuntu18.08,解决过程中出现的各种问题
笔记本安装ubuntu18.08,解决过程中出现的各种问题 1.做启动U盘 在官网下载要安装的镜像,使用软碟通制作U盘安装盘 文件 -- 打开 然后 启动 -- 写入硬盘映像 -- 选择你的u盘 -- ...
- thinkphp5.1+layui2.x 时间戳转换为日期格式
layui.use(['table','util'],function(){ var table = layui.table,form = layui.form; table.render({ ele ...