Java HashMap源码详解
Java数据结构-HashMap
1. HashMap
1.1 HashMap介绍
1.1.1 HashMap介绍
- HashMap是一个用于存储Key-Value键值对的集合,每一个键值对也叫做Entry,有着key与value两个基本属性以及有其他的包含其他结点位置信息的属性
- 通过HashMap我们可以存储键值对,并且可以在较短的时间复杂度内,
1.1.2 HashMap继承图
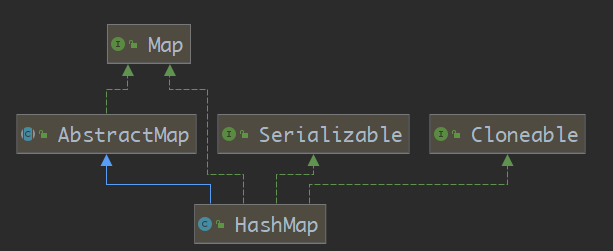
HashMap通过继承
AbstractMap实现了Map接口,且本身也实现了Map接口在接口实现关系上来看为多余操作
但有一点要注意,在使用反射获取实现接口时,如果不是显示实现某接口而是通过继承来实现该接口,则不会获取该接口类型,这一点在使用动态代理时要注意
HashMap.class.getInterfaces()//[interface java.util.Map, interface java.lang.Cloneable, interface java.io.Serializable]- HashMap 通过显示实现Map接口,从而在通过反射时能够获取到Map接口
HashMap实现了
Serializable接口,可以通过java.io.ObjectStream进行序列化HashMap实现了
Cloneable接口,实现了浅拷贝,通过以下代码可以证实:HashMap map = new HashMap(); map.put(1, "first"); HashMap copiedMap = (HashMap) map.clone(); System.out.println(copiedMap.get(1)==map.get(1));//true copiedMap.put(2, "second"); System.out.println(map);//{1=first}
1.2 HashMap 组成结构
1.2.1 Hashmap底层数据结构
- HashMap底层采用数组+链表/红黑树的数据结构
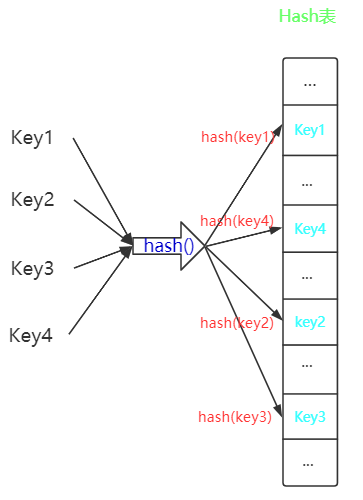
(1)哈希表
哈希表也成为散列表,它是根据关键字经过
hash()函数处理,将值映射到哈希表上的某一个位置,以该位置作为关键字的存储位置,无论存在哪,只需要进行一次hash计算,便可以找到该位置,整个查找过程时间复杂度为\(O(1)\)HashMap 使用数组作为哈希表,来存储Key的hash()信息
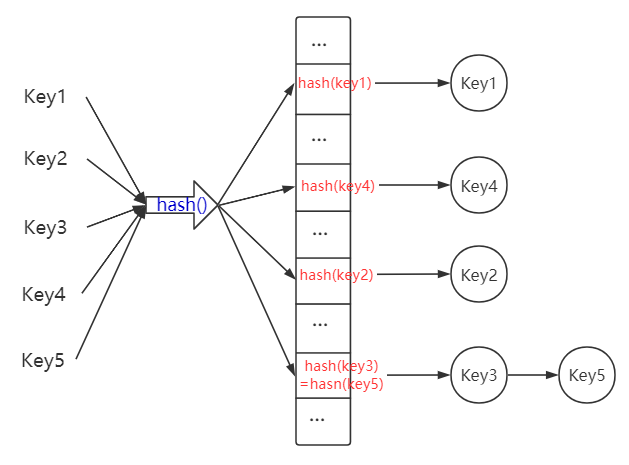
(2)链表
因为
hash()函数是将key值映射到有限的空间中,如果hash()函数碰撞性设计的不完善,或者哈希表存储的元素过多,必然会导致不同元素的hash值相同,即位置冲突,此时我们采用的方式一般有:- 使用链表,存储不同元素但hash()函数处理值相同的元素,哈希表对应位置存储该链表的头结点
- 扩大哈希表数组的大小,重新设计
hash()函数映射关系使元素分布地更加均匀,降低碰撞几率
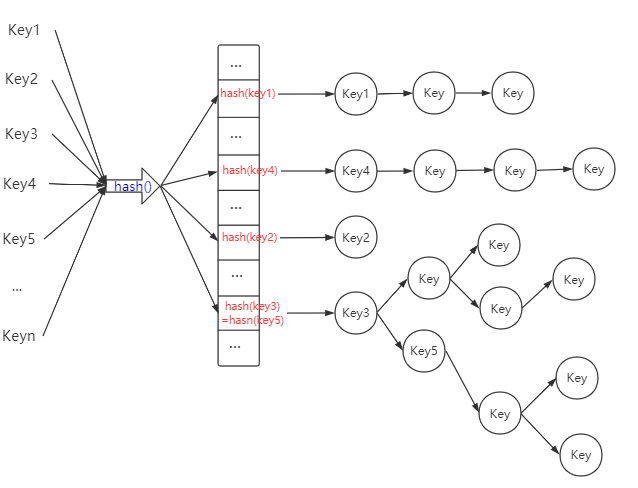
(3)红黑树
红黑树为一颗平衡二叉树
当元素越来越多时,hash碰撞也会越来越严重,链表的长度会变得很大,此时如果我们想要查找该链表的的某一个元素,其时间复杂度为\(O(n)\),必须采用一个阈值,当链表的长度达到该阈值时,便应该将链表转化为一颗红黑树,从而将时间复杂度从\(O(n)\)降低为\(O(logn)\),从而改善Hash表的查找性能
2.HashMap源码解析
2.1 HashMap属性源码解析
2.1.1 HashMap中的静态常量
(1)缺省table长度
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;//为16
(2)table长度的最大值
static final int MAXIMUM_CAPACITY = 1 << 30;
(3)缺省负载因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;- 负载因子 = 总键值对数 / 桶个数
(4)树化阈值-链表长度
static final int TREEIFY_THRESHOLD = 8;- 链表转换为红黑树的条件之一为桶的链表长度达到8及以上
(5)树化阈值-HashMap元素个数
static final int MIN_TREEIFY_CAPACITY = 64;- 链表转换为红黑树的条件之二为HashMap中的元素达到64及以上
(6)树降为链表的阈值
static final int UNTREEIFY_THRESHOLD = 6;- 当该桶的链表树的结点数目低于该值时便会转化为链表,以便避免不必要的平衡修复运算
2.1.2 HashMap中的属性
(1)HashMap元素个数
transient int size;
(2)Hash表结构修改次数
transient int modCount;- 结构修改:插入或删除元素等操作,改变了HashMap的结构(插入相同元素替换掉原来元素因为并没有改变结构,所以不算修改)
(3)扩容阈值
int threshold;- 扩容阈值,当table中的元素达到阈值时,触发扩容
threshold = loadFactor * capacity
(4)负载因子
final float loadFactor;
2.1.2 HashMap中的存储结点
(1)静态结点类源码
static class Node<K,V> implements Map.Entry<K,V> { final int hash; final K key; V value; Node<K,V> next; . . . 构造方法 . . . getter&&setter //重写的hash()方法 public final int hashCode() { return Objects.hashCode(key) ^ Objects.hashCode(value); } //重写的equals方法 public final boolean equals(Object o) { //如果为该对象 if (o == this) return true; //如果是Map.Entry类型 if (o instanceof Map.Entry) { Map.Entry<?,?> e = (Map.Entry<?,?>)o; //如键,值equals方法都为真 if (Objects.equals(key, e.getKey()) && Objects.equals(value, e.getValue())) return true; } return false; } ...toString(){...} }结点Node类为实现了
Map.Entry接口的一个静态内部类,主要包含:hash计算值:后面构造时用以保存hashcode,避免每次重新计算key:键value:值next:指向下一个结点的引用:如果发生哈希碰撞,使用链式结构存储hash值相同的键值对
重写的
hash()方法将key和value经Objects.hashCode(Object o)处理后进行与操作,使得hash()函数映射更加随机均匀重写的
equals方法中只有传入结点为自身结点或者key与value都相同时,结果才为真
2.1.3 Hash表
(1)Hash表源码
Hash表定义源码:
transient Node<K,V>[] table;为了能够通过确定计算的hashcod找到桶的位置,HashMap中底层采用Node<K,V>结点类型数组作为桶
transient修饰在序列化时会被跳过
(2)确定桶的位置
- 当
put一个结点时,通过以下算法来确定结点应该位于哪个桶index = (table.length - 1) & node.hash,也就是说位置完全取决于node.hash的后几位(table.length-1的二进制位数)
(3)长度的确定
hash表长度计算方法源码:
static final int tableSizeFor(int cap) { int n = cap; n |= n >>> 1; n |= n >>> 2; n |= n >>> 4; n |= n >>> 8; n |= n >>> 16; return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1; }该方法的作用是,当初始化时,通过传入capacity返回一个大于等于当前值cap的一个数字,并且这个数字一定是2的次方数
该方法不断通过右移然后进行‘或’操作,可以将穿传入的cap中的0位填满,变为
1...1的形式,即\(2^{n的位数}-1\)例:
cap = 10 n = 10 - 1 => 9 0b1001 | 0b0100 => 0b1101 0b1101 | 0b0011 => 0b1111 0b1111 | 0b0000 => 0b1111 = 15 return 15+1 = 16cap = 16 n = 16; 0b10000 | 0b01000 =>0b11000 0b11000 | 0b00110 =>0b11110 0b11110 | 0b00001 =>0b11111 return 31 + 1;
Hash表的长度必须为2的整数次幂
- 因为当数组的长度为2的整数次幂时,table.length-1的二进制位(11...1)(例如15:1111,7:111)
- 假设当前长度为16,其table.length-1 = 1111b,如果进来两个元素的hash分别是(。。。0111 b)与(。。。0001 b)分别进行与操作,其位置结果不同;
- 如果当前长度为10,其table.length-1 = 1001b,上面两个元素分别进行与操作结果相同(即该长度只需要传入元素的hashcode的最低字节的最高位与最低位相同即可(只比较了两位))必然导致分配不均匀,而使用2的整数次幂-1可以保证进行与操作时,只有hashcode的位比较全部相同才会相同,提高了分散程度
2.2 方法源码分析
2.2.1 构造方法分析
(1)HashMap(int initialCapacity, float loadFactor)
public HashMap(int initialCapacity, float loadFactor) { //前面都是校验传入参数是否合法,不合法抛出 IllegalArgumentException //initialCapacity必须是大于0 ,最大值为 MAX_CAPACITY if (initialCapacity < 0) throw new IllegalArgumentException("Illegal initial capacity: " +initialCapacity); if (initialCapacity > MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY; //loadFactor必须大于0且不是NaN if (loadFactor <= 0 || Float.isNaN(loadFactor)) throw new IllegalArgumentException("Illegal load factor: " +loadFactor); this.loadFactor = loadFactor; //HashMap的树化阈值通过以下方法取得 this.threshold = tableSizeFor(initialCapacity); }
(2)其它构造方法
其它构造方法源码
public HashMap() { this.loadFactor = DEFAULT_LOAD_FACTOR; // 0.75 } public HashMap(int initialCapacity) { this(initialCapacity, DEFAULT_LOAD_FACTOR); } public HashMap(Map<? extends K, ? extends V> m) { this.loadFactor = DEFAULT_LOAD_FACTOR; //调用putMapEntries,添加键值对s putMapEntries(m, false); }- 其它构造方法的属性处了传入参数属性其它皆为默认属性
putMapEntries(.)源码:
final void putMapEntries(Map<? extends K, ? extends V> m, boolean evict) { //获取键值对map长度 int s = m.size(); if (s > 0) { //如果table没有初始化,先计算一系列属性再初始化 if (table == null) { // pre-size //计算初始的table长度 float ft = ((float)s / loadFactor) + 1.0F; //选取table长度与最大长度的最小值 int t = ((ft < (float)MAXIMUM_CAPACITY) ? (int)ft : MAXIMUM_CAPACITY); if (t > threshold) threshold = tableSizeFor(t); } //如果map的长度大于扩容阈值,扩容table else if (s > threshold) resize(); //遍历调用put方法添加键值对 for (Map.Entry<? extends K, ? extends V> e : m.entrySet()) { K key = e.getKey(); V value = e.getValue(); putVal(hash(key), key, value, false, evict); } } }
2.2.2 Put(K key,V value)
(1)put(K key, V value)
增加键值对源码:
public V put(K key, V value) { return putVal(hash(key), key, value, false, true); }
(2)hash(K key)
hash扰动函数源码:
static final int hash(Object key) { int h;//h=0 return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }当table长度比较小时,从前面位置算法
index = (table.length-1)|node.hash()可以看出,如果不经处理,计算的index只取决于结点的hash的后几位(table.length-1的二进制长度),这样会使不同元素的位置结果相同概率大大增加h>>16使得h的高16位全为0,
(h = key.hashCode()) ^ (h >>> 16)就可以让结果的高16位为key.hashCode()的高16位,使得高16位也参与表位置的计算例:
h = 0b 0010 0101 1010 1100 0011 1111 0010 1110 0b 0010 0101 1010 1100 0011 1111 0010 1110 ^ 0b 0000 0000 0000 0000 0010 0101 1010 1100 => 0010 0101 1010 1100 0001 1010 1000 0010
(3)putVal
putVal源码
/** * Implements Map.put and related methods. * * @param hash hash for key -key的hash值 * @param key the key * @param value the value to put * @param onlyIfAbsent if true, don't change existing value -true:如果该元素已经存在与HashMap中就不操作了 * @param evict if false, the table is in creation mode. * @return previous value, or null if none */ final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) { //tab:引用当前hashMap的散列表 //p:表示当前散列表的元素 //n:表示散列表数组的长度 //i:表示路由寻址结果 Node<K,V>[] tab; Node<K,V> p; int n, i; //延迟初始化逻辑,第一次调用putVal时会初始化hashMap对象中的最耗费内存的散列表 //这样会防止new出来HashMap对象之后却不存数据,导致空间浪费的情况 if ((tab = table) == null || (n = tab.length) == 0)//此处进行tab与n的赋值 n = (tab = resize()).length; //情形1:寻址找到的桶位,赋值给p,如果p刚好是 null,这个时候,直接将当前k-v=>node 扔进去就可以了 if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null); else { //e:临时的Node元素,不为null的话,找到了一个与当前要插入的key-value一致的key的元素 //k:表示临时的一个key Node<K,V> e; K k; //情形2:表示桶位中的该元素,与你当前插入的元素的key完全一致,表示后续需要进行替换操作 if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; //情形3:如果改桶为存储的结点与插入结点的hash不同或者key不一致吗,且为红黑树的树根结点,在需要插入结点到红黑树中 else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); //情形4:链表的情况,而且链表的头元素与我们要插入的key不一致。 else { for (int binCount = 0; ; ++binCount) { //条件成立的话,说明迭代到最后一个元素了,也没找到一个与你要插入的key一致的node,说明需要加入到当前链表的末尾 if ((e = p.next) == null) { //链表末尾添加新的结点 p.next = newNode(hash, key, value, null); //条件成立的话,说明当前链表的长度,达到树化标准了,需要进行树化 //TREEIFY_THRESHOLD - 1 = 7 if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st //树化操作 treeifyBin(tab, hash); break; } //条件成立的话,说明找到了相同key的node元素,需要进行替换操作 if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; p = e; } } //e不等于null,条件成立说明,找到了一个与你插入元素key完全一致的数据,需要进行替换 if (e != null) { // existing mapping for key V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) e.value = value; afterNodeAccess(e); //返回旧元素 return oldValue; } } //modCount:表示散列表结构被修改的次数,替换Node元素的value不计数 ++modCount; //插入新元素,size自增,如果自增后的值大于扩容阈值,则触发扩容。 if (++size > threshold) resize(); afterNodeInsertion(evict); return null; }再啰嗦一遍整个方法的流程:
传入参数
int hash:上层调用者经过hash扰动后的hash值K key,V vey:键,值boolean onlyIfAbsent:如果为true,则对相同的元素不进行替换处理boolean evict:
方法执行逻辑:
- 如果table为null或者table长度为0
- 进行扩容方法,并取得表长
- 如果经过位置计算的到的table相应位置的元素
p为null- new新的结点并赋值到table对应位置
- 否则,先创建临时
Node e,K k- 如果经过位置计算得到的元素
p.hash值与传入的hash值相同,并且p.key==key或者说equals方法比较为true- 保存p的引用(
e=p),下一步进行结点的值的替换
- 保存p的引用(
- 否则,如果
p为红黑树结点- 调用红黑树的结点插入操作
- 否则,该情形为链表,从头结点
p开始遍历,binCount=0,之后每次循环+1- 如果已经到链表末尾(
(e=p.next)==null,e为当前结点p的下一个结点),说明并没有找到该元素,new 新的结点插入到链表尾部(p.next = new Node(...))- 遍历的长度(该链表长度与树化阈值比较(
binCount >= TREEIFY_THRESHOLD - 1)),即当binCount到达7时,即插入操作后链表长度为8时(binCount从0开始计数,而p开始就对应第一个结点),调用树化方法 - break
- 遍历的长度(该链表长度与树化阈值比较(
- 否则找到链表中的元素
e.hash值与传入的hash值相同,并且e.key==key或者说equals方法比较为true- 退出
- 保存结点p = e
- 如果已经到链表末尾(
- 如果经过位置计算得到的元素
- 如果e不为null,说明找到了一个key一致的元素,需要将该结点e的value进行替换
- 保存旧的
oldvalue = e.value - 如果
!onlyIfAbsent || oldValue == null- 将e.value = value进行替换
- afterNodeAccess(e);
return oldvalue;
- 保存旧的
- HashMap this.modCount++ 修改次数
- 如果++size超过扩容阈值
- 执行扩容方法
- afterNodeInsertion(evict);
return null
- 如果table为null或者table长度为0
待续...
Java HashMap源码详解的更多相关文章
- HashMap源码详解(JDK7版本)
一.内部属性 内部属性源码: //内部数组的默认初始容量,作为hashmap的初始容量,是2的4次方,2的n次方的作用是减少hash冲突 static final int DEFAULT_INITIA ...
- HashMap源码详解与对比
前几天工作忙得焦头烂额时,同事问了一下关于Map的特性,刹那间懵了一下,紧接着就想起来了一些关于Map的一些知识,因为只要涉及到Collection集合类时,就会谈及Map类,因此理解好Map相关的知 ...
- 数据结构与算法系列2 线性表 使用java实现动态数组+ArrayList源码详解
数据结构与算法系列2 线性表 使用java实现动态数组+ArrayList源码详解 对数组有不了解的可以先看看我的另一篇文章,那篇文章对数组有很多详细的解析,而本篇文章则着重讲动态数组,另一篇文章链接 ...
- Java源码详解系列(十)--全面分析mybatis的使用、源码和代码生成器(总计5篇博客)
简介 Mybatis 是一个持久层框架,它对 JDBC 进行了高级封装,使我们的代码中不会出现任何的 JDBC 代码,另外,它还通过 xml 或注解的方式将 sql 从 DAO/Repository ...
- Activiti架构分析及源码详解
目录 Activiti架构分析及源码详解 引言 一.Activiti设计解析-架构&领域模型 1.1 架构 1.2 领域模型 二.Activiti设计解析-PVM执行树 2.1 核心理念 2. ...
- RocketMQ源码详解 | Producer篇 · 其二:消息组成、发送链路
概述 在上一节 RocketMQ源码详解 | Producer篇 · 其一:Start,然后 Send 一条消息 中,我们了解了 Producer 在发送消息的流程.这次我们再来具体下看消息的构成与其 ...
- Shiro 登录认证源码详解
Shiro 登录认证源码详解 Apache Shiro 是一个强大且灵活的 Java 开源安全框架,拥有登录认证.授权管理.企业级会话管理和加密等功能,相比 Spring Security 来说要更加 ...
- 源码详解系列(六) ------ 全面讲解druid的使用和源码
简介 druid是用于创建和管理连接,利用"池"的方式复用连接减少资源开销,和其他数据源一样,也具有连接数控制.连接可靠性测试.连接泄露控制.缓存语句等功能,另外,druid还扩展 ...
- 源码详解系列(七) ------ 全面讲解logback的使用和源码
什么是logback logback 用于日志记录,可以将日志输出到控制台.文件.数据库和邮件等,相比其它所有的日志系统,logback 更快并且更小,包含了许多独特并且有用的特性. logback ...
随机推荐
- SpringBoot框架——从SpringBoot看IoC容器初始化流程之方法分析
目录 一.概观Spring Boot 二.Spring Boot应用初始化 2.1 初始化入口 2.2 SpringApplication的run方法 2.3 方法分析 三.容器创建与初始化 3.1 ...
- 波兰政府在继韩国之后也增加了对 Linux 的使用
导读 前段时间, 韩国政府起草了一项战略,准备采用基于 Linux 的开源操作系统全面取代 Windows 7,以摆脱对其的依赖. 目前,波兰的社会保险公司 ZUS( Zakład Ubezpiecz ...
- ASP.NET Core ActionFilter引发的一个EF异常
最近在使用ASP.NET Core的时候出现了一个奇怪的问题.在一个Controller上使用了一个ActionFilter之后经常出现EF报错. InvalidOperationException: ...
- Python包的应用
包的简介 你们听到的包,可不是女同胞疯狂喜欢的那个包,我们来看看这个是啥包 官方解释: ? 1 2 3 4 5 6 7 8 9 Packages are a way of structuring Py ...
- js 面向对象 模拟日历
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- python对接elasticsearch的基本操作
基本操作 #!/usr/bin/env python # -*- coding: utf-8 -*- # author tom from elasticsearch import Elasticsea ...
- Spark入门(二)--如何用Idea运行我们的Spark项目
用Idea搭建我们的Spark环境 用IDEA搭建我们的环境有很多好处,其中最大的好处,就是我们甚至可以在工程当中直接运行.调试我们的代码,在控制台输出我们的结果.或者可以逐行跟踪代码,了解spark ...
- Java 基础(四):数组
数组,一种应用非常广泛的数据结构,简单地来说就是一组类型相同且无序的元素的存储在固定长度且有序的内存空间. 创建一个数组 在Java中,我们可以通过[]去声明一个指定类型的数组 int[] a; // ...
- 深入理解“骑士”漏洞 VoltJockey
先理解一下题目:VoltJockey: Breaching TrustZone by Software-Controlled Voltage Manipulation over Multi-core ...
- SQL常见错误总结
目录 语法错误 标点错漏 重命名 数据拼接 null值 逻辑顺序 函数错误 参数的数量 参数的格式 逻辑错误 数据重复 无效筛选 标签重叠 时间错位 SQL是数据分析中最高频的操作之一,本文梳理常见的 ...