<algorithm>中常用函数
先说一下STL操作的区间是 [a, b),左边是闭区间,右边是开区间,这是STL的特性,所以<algorithm>里面的函数操作的区间也都是 [a, b)。
先声明一下, sort()函数在这篇文章中没讲,因为sort()函数功能比较强大(我自己认为的,哈哈),所以我专门用了另一篇文章来写sort()函数,
附上介绍sort()函数的链接:https://www.cnblogs.com/buanxu/p/12771502.html
algorithm的意思是算法,<algorithm>提供了很多算法,下面说一下常用的
1. max(x,y) 返回x、y中最大的那个
min(x,y) 返回x、y中最小的那个
abs(x) 返回x的绝对值
swap(x,y) 交换x、y的值
2. reverse(it,it+10);有两个参数;将区间 [it, it+10)内的元素翻转,it可以是数组也可以是顺序容器的迭代器;有一个地方要特别注意reverse()
中第一个参数指向第一个元素,第二个元素指向末尾元素的下一个位置,具体用法看代码
#include<iostream>
#include<vector>
#include<string>
#include<algorithm>
using namespace std;
int main()
{
int a[]={,,,,,,,,,};
string str="abcdefgh"; //string也是一种顺序容器,有各种成员函数,只不过它只能用来存放字符,
vector<int> v;
v.push_back();
v.push_back();
v.push_back();
v.push_back();
v.push_back();
v.push_back();
cout<<"翻转前:\n";
for(int i=;i<;i++)
cout<<a[i]<<" ";
cout<<"\n";
for(int i=;i<str.size();i++)
cout<<str[i]<<" ";
cout<<"\n";
for(int i=;i<v.size();i++)
cout<<v[i]<<" ";
cout<<"\n";
reverse(a,a+); //操作区间为[a,b),reverse()中第一个参数指向第一个元素,第二个元素指向末尾元素的下一个位置
reverse(str.begin(),str.end());
reverse(v.begin(),v.end());
cout<<"翻转后:\n";
for(int i=;i<;i++)
cout<<a[i]<<" ";
cout<<"\n";
for(int i=;i<str.size();i++)
cout<<str[i]<<" ";
cout<<"\n";
for(int i=;i<v.size();i++)
cout<<v[i]<<" ";
cout<<"\n";
return ;
}
结果如下:
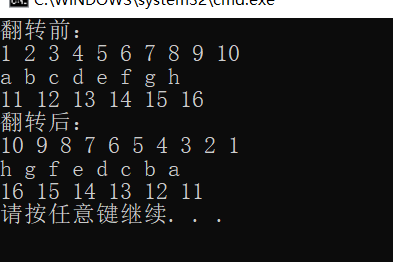
3. find(it, it+10, x);有三个参数;前两个参数为查找区间,第三个参数为待查找元素,即在[a, b)这个区间内查找x;find()和reverse()一样,操作的对象
可以是数组,也可以是容器;查找成功返回对应元素的位置,即若操作对象是数组就返回指针,指针指向对应元素的位置,若操作对象是容器就返回
迭代器,迭代器向对应元素的位置;查找不成功返回第二个参数的值。具体用法还是看代码吧,由于我写的比较详细,代码有点多,耐心点看
#include<iostream>
#include<vector>
#include<string>
#include<algorithm>
using namespace std;
int main()
{
int a[]={,,,,,,,,,};
string str("abcdefgh"); //string也是一种顺序容器,有各种成员函数,只不过它只能用来存放字符,
vector<int> v;
v.push_back();
v.push_back();
v.push_back();
v.push_back();
v.push_back();
v.push_back();
int* p1=find(a,a+,); //在[a,a+10)这一区间查找
int* p2=find(a,a+,); //a中不存在12,查找失败;只是为了展示一下查找失败是什么样子
int* p3=find(a,a+,); //在[a,a+5)这一区间查找;只是想说明可以任意的合法区间内查找
int* p4=find(a,a+,); //在[a,a+5)这一区间内不存在6,查找失败
string::iterator iter1=find(str.begin(),str.end(),'d');
string::iterator iter2=find(str.begin(),str.end(),'m'); //str中不存在'm',查找失败
vector<int>::iterator iter3=find(v.begin(),v.end(),);
vector<int>::iterator iter4=find(v.begin(),v.end(),); //v中不存在17,查找失败 cout<<"在区间[a,a+10)内查找8:查找成功\n";
cout<<"p1的值:"<<p1<<" a[7]的地址"<<&a[]<<"\n"; //查找成功后,p1指向a[4],p1的值就是a[4]地址,这里就是为了验证p1是否等于&a[4]
cout<<"*p1="<<*p1<<" a[7]="<<a[]<<"\n\n"; //输出p1所指的元素 cout<<"在区间[a,a+10)内查找12:查找失败\n";
cout<<"p2的值:"<<p2<<" a+10的地址:"<<a+<<"\n"; //查找失败后,返回第二个参数的值,这里就是为了验证p2是否等于a+10
cout<<"*p2="<<*p2<<"\n\n"; //由于返回了第二个参数的值,p2此时指向数组a末尾元素的下一个位置(即a+10),所以此时输出的*p2会是非法值 cout<<"在区间[a,a+5)内查找5:查找成功\n";
cout<<"p3的值:"<<p3<<" a[4]的地址"<<&a[]<<"\n"; //和上面的差不多,只是想说明可以是任意的合法区间
cout<<"*p3="<<*p3<<" a[4]="<<a[]<<"\n\n"; //输出p3所指的元素 cout<<"在区间[a,a+5)内查找6:查找失败\n";
cout<<"p4的值:"<<p4<<" a+5的地址:"<<a+<<"\n"; //查找失败后,返回第二个参数的值,这里就是为了验证p2是否等于a+5
cout<<"*p4="<<*p4<<" a[5]="<<a[]<<"\n\n"; //返回第二个参数的值后,p4的值就是a+5,p4指向a[5],此时输出的*p4就是a[5]的值 cout<<"在str里查找'd':查找成功\n";
cout<<"*iter1="<<*iter1<<"\n"; //查找成功,输出迭代器所指元素
cout<<"结果为1代表查找失败,为0代表查找成功:"<<(iter1==str.end())<<"\n\n";//在这里判断一下是否查找成功
cout<<"在str里查找'm':查找失败\n";
cout<<"结果为1代表查找失败,为0代表查找成功:"<<(iter2==str.end())<<"\n\n"; //查找失败,返回str.end()的值,即iter2指向str末尾元素的下一个位置,在这里也做个判断 cout<<"在v里查找14:查找成功\n";
cout<<"*iter3="<<*iter3<<"\n"; //查找成功,输出迭代器所指元素
cout<<"结果为1代表查找失败,为0代表查找成功:"<<(iter3==v.end())<<"\n\n";//在这里判断一下是否查找成功
cout<<"在v里查找17:查找失败\n";
cout<<"结果为1代表查找失败,为0代表查找成功:"<<(iter4==v.end())<<"\n"; //查找失败,返回str.end()的值,即iter2指向str末尾元素的下一个位置,在这里也做个判断 return ;
}
结果看图:
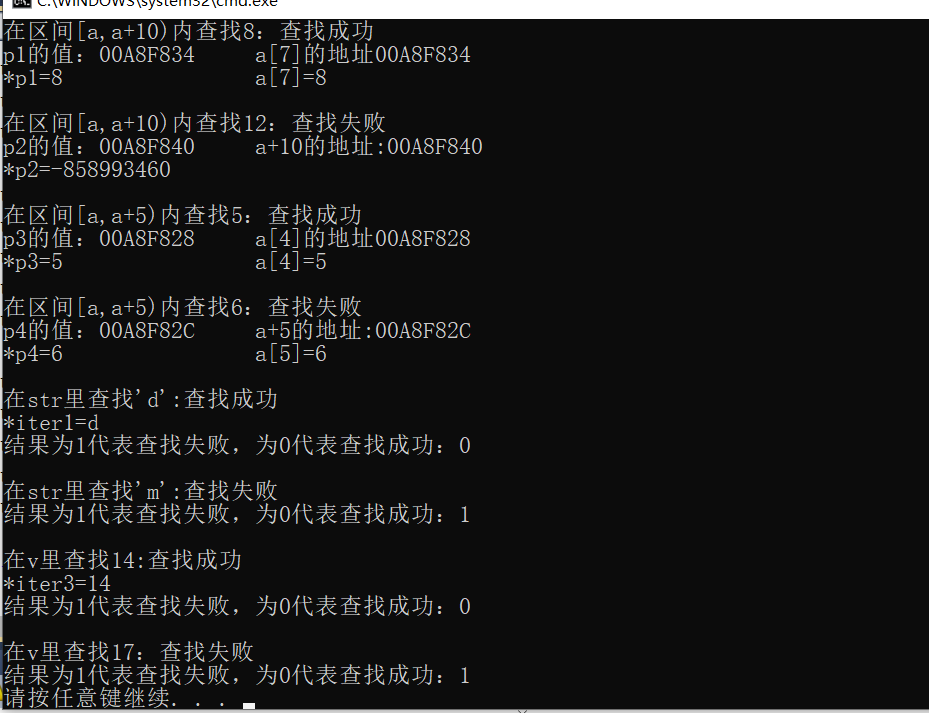
4. fill(it,it+10,x);前两个参数为填充区间,第三个参数为待填充的数据,可以是任意数值;可以将数组it的[a,b)这一区间填充为x,或者对容器进行填充。
具体用法还是看代码吧
#include<iostream>
#include<vector>
#include<string>
#include<algorithm>
using namespace std;
int main()
{
int a[]={,,,,,,,,,};
string str("abcdefgh"); //string也是一种顺序容器,有各种成员函数,只不过它只能用来存放字符,
vector<int> v;
v.push_back();
v.push_back();
v.push_back();
v.push_back();
v.push_back();
v.push_back(); cout<<"数组a填充前:";
for(int i=;i<;i++)
cout<<a[i]<<" ";
cout<<"\n数组a填充后:";
fill(a+,a+,); //指定填充区间
for(int i=;i<;i++)
cout<<a[i]<<" ";
cout<<"\n\n"; cout<<"str填充前:";
for(int i=;i<str.size();i++)
cout<<str[i]<<" ";
cout<<"\nstr填充后:";
fill(str.begin()+,str.end()-,'x'); //用迭代器指定填充区间
for(int i=;i<str.size();i++)
cout<<str[i]<<" ";
cout<<"\n\n"; cout<<"v填充前:";
for(int i=;i<v.size();i++)
cout<<v[i]<<" ";
cout<<"\nv填充后:";
fill(v.begin()+,v.end(),); //用迭代器指定填充区间
for(int i=;i<v.size();i++)
cout<<v[i]<<" ";
cout<<"\n";
return ;
}
运行结果看图:

5. copy(v1.begin(),v1.end(),v2.begin());copy()用于容器之间的复制,返回一个迭代器,这个迭代器指向v2中已被复制区间的最后一个位置;前两个参数是v1的复制区间,
把容器v1中[a,b)区间内的元素复制到容器v2中;第三个参数是复制到v2的起始位置(起始位置可以设置成任意合法的位置,不能越界),会覆盖掉v2对应区间的数据。特别要注意,
区间[a,b)的长度一定要小于 v2的复制起始位置到v2的末尾位置的长度,否则v2会溢出,运行结果会报错。
#include<iostream>
#include<vector>
#include<algorithm>
using namespace std;
int main()
{
vector<int> v1,v2;
v1.push_back();
v1.push_back();
v1.push_back();
v1.push_back();
v2.push_back();
v2.push_back();
v2.push_back();
v2.push_back();
v2.push_back();
v2.push_back(); vector<int>::iterator iter,it;
cout<<"复制前v2中的元素:";
for(it=v2.begin();it!=v2.end();it++)
cout<<*it<<" ";
iter=copy(v1.begin(),v1.end(),v2.begin()+),it; //前两个参数指定复制区间,第三个参数指定v2的起始位置;返回迭代器,指向v2中被复制过来的最后一个元素的下一个位置
cout<<"\n把v1复制到v2中后,v2中的元素:";
for(it=v2.begin();it!=v2.end();it++)
cout<<*it<<" ";
cout<<"\n*iter="<<*iter<<"\n"; //iter指向v2中被复制过来的最后一个元素的下一个位置
return ;
}
结果如下图:
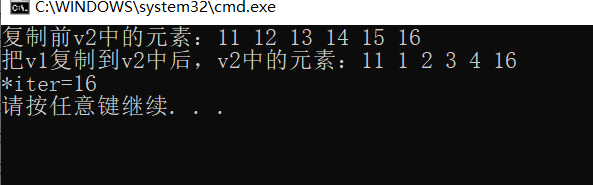
下面来验证一下我上面说过的 “区间[a,b)的长度一定要小于 v2的复制起始位置到v2的末尾位置的长度,否则v2会溢出,运行结果会报错”(一定要理解这句话,可以自已去试试),
为此我把v2改了一下,把v2长度改短了。看代码
#include<iostream>
#include<vector>
#include<algorithm>
using namespace std;
int main()
{
vector<int> v1,v2;
v1.push_back();
v1.push_back();
v1.push_back();
v1.push_back();
v2.push_back();
v2.push_back();
v2.push_back(); vector<int>::iterator iter,it;
cout<<"复制前v2中的元素:";
for(it=v2.begin();it!=v2.end();it++)
cout<<*it<<" ";
iter=copy(v1.begin(),v1.end(),v2.begin()+),it; //前两个参数指定复制区间,第三个参数指定v2的起始位置;返回迭代器,指向v2中被复制过来的最后一个元素的下一个位置
cout<<"\n把v1复制到v2中后,v2中的元素:";
for(it=v2.begin();it!=v2.end();it++)
cout<<*it<<" ";
cout<<"\n*iter="<<*iter<<"\n"; //iter指向v2中被复制过来的最后一个元素的下一个位置
return ;
}
结果如下:
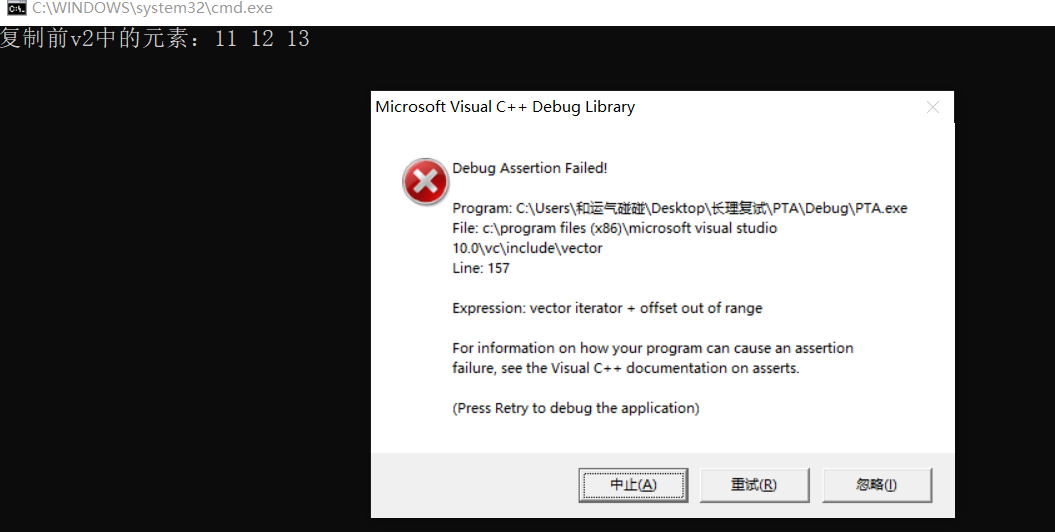
可以看到程序还没运行完就报错了,所以一定要注意这一点。
<algorithm>中常用函数的更多相关文章
- LoadRunner中常用函数参考手册
基础篇1:LoadRunner中常用函数参考手册 常用函数列表 web_url web_submmit_form VS web_submmit_data VS web_custom_request w ...
- 【c++进阶:c++ algorithm的常用函数】
c++ algorithm的常用函数 https://blog.csdn.net/hy971216/article/details/80056933 reverse() reverse(it,it2) ...
- OpenCV图像处理中常用函数汇总(1)
//俗话说:好记性不如烂笔头 //用到opencv 中的函数时往往会一时记不起这个函数的具体参数怎么设置,故在此将常用函数做一汇总: Mat srcImage = imread("C:/Us ...
- JavaScript中常用函数(入门级)(持续更新)
本文中枫竹梦介绍一些JavaScript中入门级的常用函数,对于已经过了入门的童鞋可选择略过,都是一些非常实用的函数.如果发现什么问题,欢迎讨论. 问题列表 Q1: 设计一个函数repeatIt(st ...
- 5. openCV中常用函数学习
一.前言 经过两个星期的努力,一边学习,一边写代码,初步完成了毕业论文系统的界面和一些基本功能,主要包括:1 数据的读写和显示,及相关的基本操作(放大.缩小和移动):2 样本数据的选择:3 数据归一化 ...
- javascript中常用函数汇总
js中函数很多,在实际项目开发中,函数的应用可以很大程度上简化我们的代码,所以在此记下开发中js中常用的函数,增强记忆. 1.isNaN(X):函数用于检查其参数是否是非数字值. 如果 x 是特殊的非 ...
- SqlServer存储过程中常用函数及操作
1.case语句 用于选择语句 SELECT ProductNumber, Category = CASE ProductLine WHEN 'R' THEN 'Road' WHEN 'M' THEN ...
- mysql中常用函数简介(不定时更新)
常用函数version() 显示当前数据库版本database() 返回当前数据库名称user() 返回当前登录用户名inet_aton(IP) 返回IP地址的数值形式,为IP地址的数学计算做准备in ...
- SQL中常用函数
SELECT CONVERT(varchar(100), GETDATE(), 23) AS 日期 结果:2017-01-05 select ISNULL(price,'0.0') ...
随机推荐
- Python基础 | pandas中dataframe的整合与形变(merge & reshape)
目录 行的union pd.concat df.append 列的join pd.concat pd.merge df.join 行列转置 pivot stack & unstack melt ...
- Python操作JSON数据代码示例
#!/usr/bin/env python import json import os def json_test(): return_dic = {} json_data = { 'appid':' ...
- 数据库连接JOIN
1,连接类型及差异 INNER JOIN:结果集只有配对成功的数据,即不包含左表或右表为空的情况: OUTER JOIN: LEFT JOIN:结果包含左表的所有记录,右表不能成功匹配的显示NULL ...
- java如何自定义一个线程池
java线程池的一些简单功能,后续会更新,代码不多,很好理解 package com.rbac.thread; import java.util.ArrayList; import java.util ...
- XHTML 简介
一.XHTML 简介 XHTML 指可扩展超文本标签语言(EXtensible HyperText Markup Language). XHTML 的目标是取代 HTML. XHTML 与 HTML ...
- C. Yet Another Walking Robot Round #617 (Div. 3)()(map + 前后相同状态的存储)
C. Yet Another Walking Robot time limit per test 1 second memory limit per test 256 megabytes input ...
- Apache本地服务器搭建(Mac版)
由于Mac自带apache服务器,所以无需下载,apache默认处于开启状态. 可以在浏览器输入localhost,显示It works!,代表目前处于开启状态,默认文件目录为/Library/Web ...
- Java并发基础02. 传统线程技术中的定时器技术
传统线程技术中有个定时器,定时器的类是Timer,我们使用定时器的目的就是给它安排任务,让它在指定的时间完成任务.所以先来看一下Timer类中的方法(主要看常用的TimerTask()方法): 前面两 ...
- python基础-深浅拷贝
深拷贝与浅拷贝 总结: # 浅拷贝:list dict: 嵌套的可变数据类型是同一个 # 深拷贝:list dict: 嵌套的不可变数据类型彼此独立 浅拷贝 # 个人理解: # 在内存中重新创建一个空 ...
- CSS实现文本,DIV垂直居中
https://blog.csdn.net/linayangoo/article/details/88528774 1.水平居中 1.行内元素水平居中 text-align:center; 利用tex ...