Web Scraper 高级用法——利用正则表达式筛选文本信息 | 简易数据分析 17

这是简易数据分析系列的第 17 篇文章。
学习了这么多课,我想大家已经发现了,web scraper 主要是用来爬取文本信息的。
在爬取的过程中,我们经常会遇到一个问题:网页上的数据比较脏,我们只需要里面的一部分信息。比如说要抓取 电影的评价人数,网页中抓到的原始数据是 1926853人评价,但是我们期望只抓取数字,把 人评价 这三个汉字丢掉。

这种类似的操作在 Excel 可以利用公式等工具处理,其实在 web scraper 里,也有一个利器,那就是正则表达式。
正则表达式是一个非常强大工具,它主要是用来处理文本数据的,常用来匹配、提取和替换文本,在计算机程序中有非常广泛的应用。
web scraper 中也内置了正则表达式工具,但只提供了提取的功能。虽然功能有所残缺,对于 web scraper 使用者来说完全够用了,毕竟 web scraper 的定位就是不会写代码的小白,我们只需要学习最基础的知识就可以了。
1.正则表达式初尝
我们先用 web scraper 初步尝试一下正则表达式。这里还是用豆瓣电影做例子,我们先选择电影的评价人数,预览图是这个样子的:
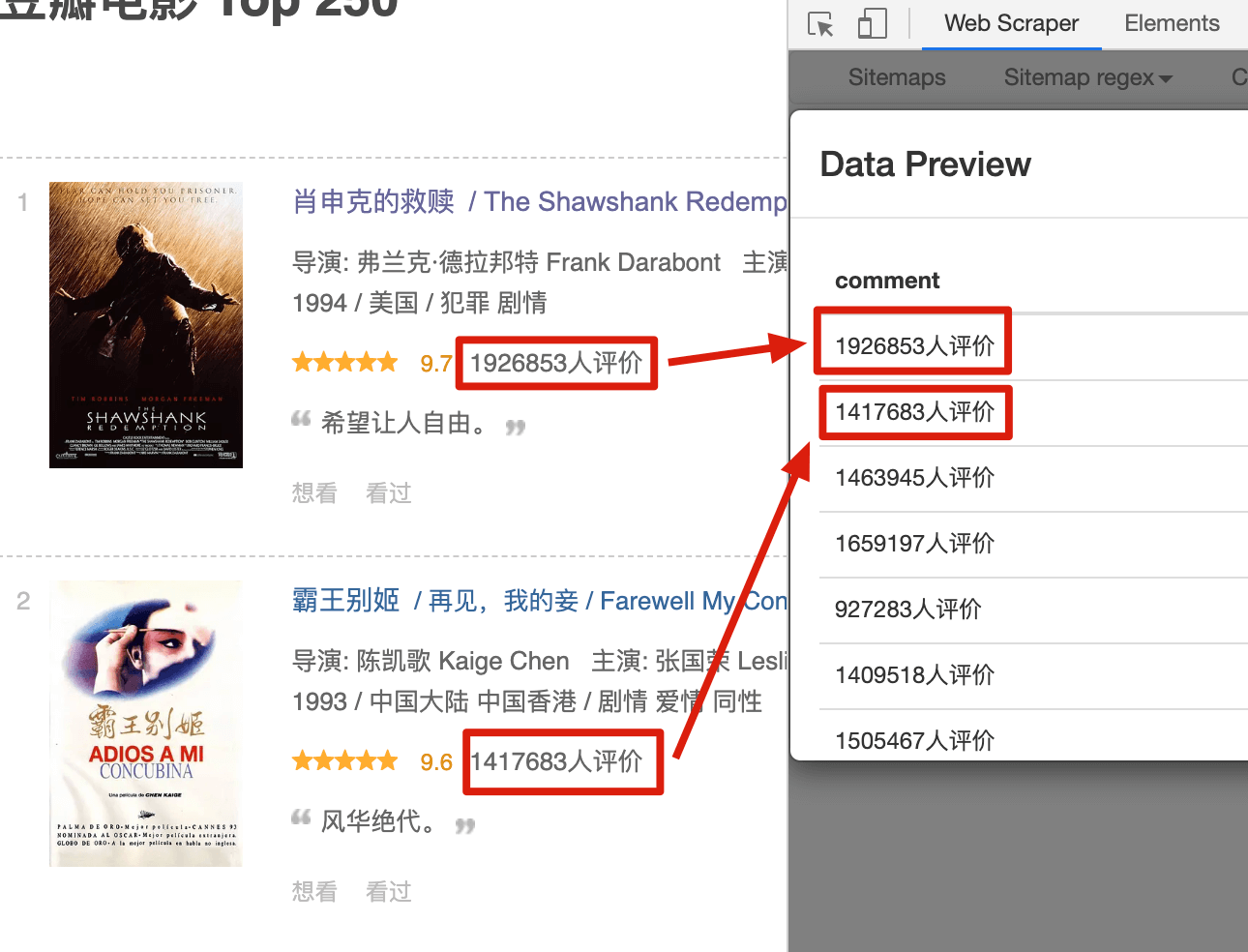
Text 选择器有个 Regex 的输入框,这个就是输入正则表达式的地方。我们输入 [0-9],然后再点击预览,是这个样子的:

这时候你应该就明白了, [0-9] 就是匹配一个数字的意思。如果我们要匹配多个数字呢?很简单,后面再加个「 + 」号就好。把 [0-9]+ 输入进去,预览一下:

很明显,所有的数字都匹配出来了。
2.正则表达式字符簇
上面讲了用 [0-9] 匹配数字,我们想一下日常用到的文本信息,不外乎这几种:数字、小写字母、大些字母,汉字,特殊字符(比如说各种计量单位、下划线回车等符号) 。
正则表达式里都有匹配这些字符的方法,下面我用一个表格列举出来:
| 字符簇 | 匹配 |
|---|---|
[0-9] |
匹配所有的数字 |
[1-9] |
匹配 1 到 9 |
[a-z] |
匹配所有的小写字母 |
[A-Z] |
匹配所有的大写字母 |
sky |
匹配 sky 这个单词,其余文本同理 |
天空 |
匹配 天空 这个词,其余文本同理 |
[\u4e00-\u9fa5] |
匹配所有的汉字(绝大部分情况下可以匹配成功) |
[ \f\r\t\n] |
匹配所有的空白字符 |
上面列举了一些常用的,其实这些规则可以组合起来,比如说 [a-z] 和 [A-Z] 组合起来,就是 [a-zA-Z],表示匹配所有的字母。这些组合也有一些简写,我这里也列举一些:
| 字符簇 | 匹配 |
|---|---|
\w |
匹配字母、数字、下划线。等价于 [A-Za-z0-9_] |
\W |
匹配非字母、数字、下划线 |
\s |
匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v] |
\S |
匹配任何非空白字符 |
基本上掌握以上内容就能匹配绝大多数字符了,这里我推荐一个正则练习网站:
http://c.runoob.com/front-end/854
按照下图所示就可以练习正则匹配了:
结合前面的例子,我们知道这些规则只能匹配一个字符,如何匹配多个字符?这就要学习正则表达式限定符。
3.正则表达式限定符
我们已经知道在 [0-9] 后面加个加号「+」就可以匹配多个字符了,其实还有很多限定符。
我们举个例子,用正则表达式匹配 100000001(表示一个亿这个小目标加一块钱,中间有 7 个 0)。
| 限定符 | 匹配解释 | 原始数据 | 例子 |
|---|---|---|---|
{n} |
n 是一个非负整数。匹配确定的 n 次 | 100001 | 10{2},表示 0 这个字符匹配 2 次,匹配结果是 100 |
{n,m} |
m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次 | 100001 | 10{2,3},表示 0 这个字符最少匹配 2 次且最多匹配 3 次,匹配结果是 1000 |
{n,} |
n 是一个非负整数。至少匹配 n 次 | 100001 | 10{2,},表示 0 这个字符至少匹配 2 次,匹配结果是 10000 |
+ |
匹配前面的子表达式一次或多次,等价于 {1,} |
z,zo,zoo | zo+ 能匹配「zo」以及「zoo」,但不能匹配「z」 |
* |
匹配前面的子表达式零次或多次,等价于 {0,} |
z,zo,zoo | zo* 能匹配「z」、「zo」以及「zoo」 |
? |
匹配前面的子表达式零次或一次,等价于 {0,1} |
z,zo,zoo | zo? 能匹配「z」以及「zo」,但不能匹配「zoo」 |
4.实战练习
学到这里,正则表达式可以算是入门了,我们可以上手几个真实的例子练习一下:
1.提取价格标签中的数字
假设 web scraper 爬到的文本信息是 价格:12.34 ¥,我们要把 12.34 提取出来。这个这个文本里有 5 类数据:
- 汉字:
价格 - 标点符号:
: - 数字
12和34 - 小数点:
. - 特殊字符:
¥
首先我们匹配小数点前的数字 12,因为价格什么数字可以能出现,而且位数一般都大于 1 位,所以我们用 [0-9]+ 来匹配;考虑到小数点「.」在正则表达式里有特殊含义,我们需要小数点前面加反斜杠 \ 表示转义,用 \. 匹配;小数部分同理,也用 [0-9]+ 匹配。
把这三部分组合在一起,即「[0-9]+\.[0-9]+」,这个表达式可以用一个图来表示:
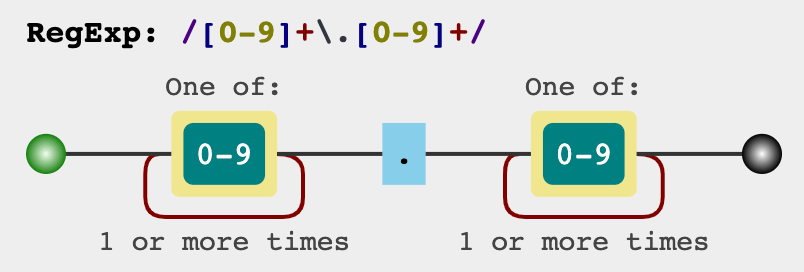
上面就是我们写出的匹配正则,可以放在刚刚推荐的网站上验证一下:

2.匹配日期
假设 web scraper 爬到的文本信息是 日期:2020-02-02[星期日],我们要把 2020-02-02[星期日] 提取出来。我们把这个文本分解一下:
- 描述信息
日期:不匹配,需要丢弃掉 - 年,一般是 4 位,可以用
[0-9]{4}匹配 - 月,一般是 2 位,可以用
[0-9]{2}匹配 - 日,一般是 2 位,可以用
[0-9]{2}匹配 - 星期,多个汉字,可以用
[\u4e00-\u9fa5]+匹配 - 分隔符
-,可以直接用「-」匹配 - 分隔符
[和],为了避免和正则表达式里的[]撞车,我们可以在前面加反斜杠\表示转义,用\[和\]匹配
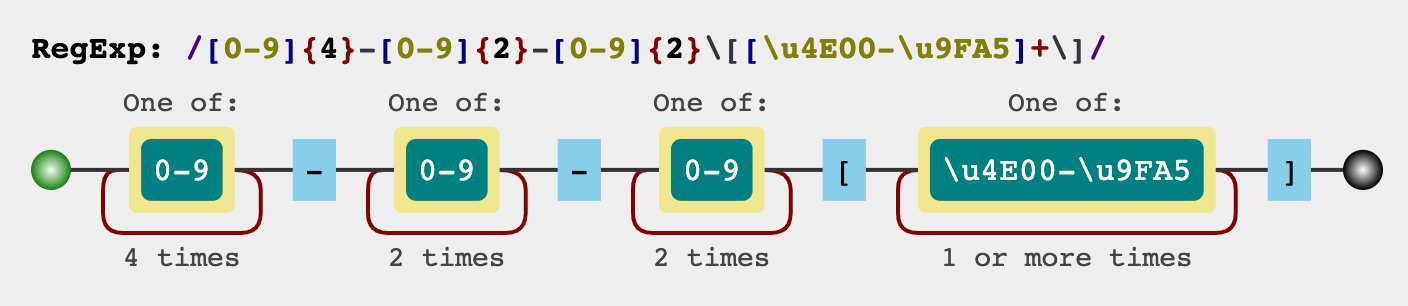
把上面的分析结果综合一下,就是
[0-9]{4}-[0-9]{2}-[0-9]{2}\[[\u4e00-\u9fa5]+\]
看上去还是挺复杂的,但是如果按上面的分析步骤一步一步来,你会发现匹配规则其实还是比较清晰的。
同样我们可以用一张图来表示上面的正则表达式:
5.进阶学习
本篇教程只是正则的入门学习,很多知识点还没有讲到。如果你对此感兴趣,可以去下面几个网站学习:
继续深入学习的一个网站,不过想成为高手,还得多加练习
可以测试自己写的正则是否正确的一个网站,而且网页末有常用的正则表达式,很多可以直接复制黏贴来用。
可以可视化的显示自己的正则匹配规则,教程中我就用了 regulex 生成正则匹配规则图。
6.温馨提示(踩坑预警)
我看了 web scraper 的源代码,它的正则表达式支持不完全,目前只支持提取文字的功能:

他欠缺的功能有:
- 全局匹配不支持
- 忽略大小写不支持
- 不支持分组提取,默认返回第一个匹配值
- 不支持文本替换
如果有以上的需求,可能要借助 Excel 等工具来支持。
7.联系我
因为文章发在各大平台上,账号较多不能及时回复评论和私信,有问题可关注公众号 ——「卤代烃实验室」,(或 wx 搜索 sky-chx)关注上车防失联。

Web Scraper 高级用法——利用正则表达式筛选文本信息 | 简易数据分析 17的更多相关文章
- Web Scraper 翻页——利用 Link 选择器翻页 | 简易数据分析 14
这是简易数据分析系列的第 14 篇文章. 今天我们还来聊聊 Web Scraper 翻页的技巧. 这次的更新是受一位读者启发的,他当时想用 Web scraper 爬取一个分页器分页的网页,却发现我之 ...
- Web Scraper 高级用法——抓取属性信息 | 简易数据分析 16
这是简易数据分析系列的第 16 篇文章. 这期课程我们讲一个用的较少的 Web Scraper 功能--抓取属性信息. 网页在展示信息的时候,除了我们看到的内容,其实还有很多隐藏的信息.我们拿豆瓣电影 ...
- 简易数据分析 15 | Web Scraper 高级用法——CSS 选择器的使用
这是简易数据分析系列的第 15 篇文章. 年末事情比较忙,很久不更新了,后台一直有读者催更,我看了一些读者给我的私信,发现一些通用的问题,所以单独写篇文章,介绍一些 Web Scraper 的进阶用法 ...
- Web Scraper 翻页——控制链接批量抓取数据(Web Scraper 高级用法)| 简易数据分析 05
这是简易数据分析系列的第 5 篇文章. 上篇文章我们爬取了豆瓣电影 TOP250 前 25 个电影的数据,今天我们就要在原来的 Web Scraper 配置上做一些小改动,让爬虫把 250 条电影数据 ...
- Web Scraper 高级用法——使用 CouchDB 存储数据 | 简易数据分析 18
这是简易数据分析系列的第 18 篇文章. 利用 web scraper 抓取数据的时候,大家一定会遇到一个问题:数据是乱序的.在之前的教程里,我建议大家利用 Excel 等工具对数据二次加工排序,但还 ...
- python-用正则表达式筛选文本信息
[摘要] 本文主要介绍如何对多个文本进行读取,并采用正则表达式对其中的信息进行筛选,将筛选出来的信息存写到一个新文本. 打开文件:open(‘文件名’,‘打开方式’)>>>file ...
- sscanf高级用法级正则表达式
sscanf高级用法级正则表达式 摘自:https://www.cnblogs.com/bluestorm/p/6864540.html sscanf与scanf类似,都是用于输入的,只是后者以屏幕 ...
- python利用正则表达式提取文本中特定内容
正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配. Python 自1.5版本起增加了re 模块,它提供 Perl 风格的正则表达式模式. re 模块使 Python ...
- 简易数据分析 08 | Web Scraper 翻页——点击「更多按钮」翻页
这是简易数据分析系列的第 8 篇文章. 我们在Web Scraper 翻页--控制链接批量抓取数据一文中,介绍了控制网页链接批量抓取数据的办法. 但是你在预览一些网站时,会发现随着网页的下拉,你需要点 ...
随机推荐
- Hashtable和Hashmap的区别?
1.实现的继承的父类不同 Hashtable继承Dictionary类 HashMap继承abstractMap类 两个类都实现了Map接口 2.线程安全性不同 Hashmap线程是不安全的 H ...
- inventor安装未完成,某些产品无法安装的解决方法
inventor提示安装未完成,某些产品无法安装该怎样解决呢?,一些朋友在win7或者win10系统下安装inventor失败提示inventor安装未完成,某些产品无法安装,也有时候想重新安装inv ...
- python3多线程爬虫(第一卷)
多进程虽然使用方便,可以充分利用CPU,但是由于个进程之间是并行且各自有自己的数据存储,所以很难进行数据间的通信,需要接入第三方模块,现在我依旧用糗事百科讲解下多线程的应用,举个例子之前用4个进程同时 ...
- docker 创建实例
docker创建mysql实例要注意表名大小写和端口号映射的问题.下面是使用文件挂载解决表名大小写问题. docker run --name mysql-1 -e MYSQL_ROOT_PASSWOR ...
- 吴裕雄--天生自然python学习笔记:Python3 错误和异常
语法错误 Python 的语法错误或者称之为解析错,是初学者经常碰到的,如下实例 >>>while True print('Hello world') File "< ...
- 关于使用gitlab协同开发提交代码步骤
记录使用gitlab协同开发时从自己的分支向master分支提交代码的步骤: 环境:安装了git和TortoiseGit(git的可视化工具) 1.首先切换到自己的分支(如果不在自己的分支) 2.gi ...
- mysql中not exists的简单理解
http://www.cnblogs.com/glory-jzx/archive/2012/07/19/2599215.html http://sunxiaqw.blog.163.com/blog/s ...
- 基于seo的话 一个页面里的h1标签应该控制在多少个
不能出现多个,一个页面只能出现一次,次数多了就会造成权重分散
- TesterHome创始人思寒:如何从手工测试进阶自动化测试?十余年经验分享
做测试十多年,有不少人问过我下面问题: 现在的手工测试真的不行了吗? 测试工程师,三年多快四年的经验,入门自动化测试需要多久? 自学自动化测试到底需要学哪些东西? 不得不说,随着行业的竞争加剧,互 ...
- Hexo搭建总结
Hexo搭建过程记录 1.Hexo基本环境搭建 1.Hexo安装前提 Node.js和Git,他们的安装方法可以自行百度. 2.具体安装步骤可以参考: https://www.cnblogs.com/ ...