Web Scraper 高级用法——抓取属性信息 | 简易数据分析 16

这是简易数据分析系列的第 16 篇文章。
这期课程我们讲一个用的较少的 Web Scraper 功能——抓取属性信息。
网页在展示信息的时候,除了我们看到的内容,其实还有很多隐藏的信息。我们拿豆瓣电影250举个例子:
电影图片正常显示的时候是这个样子:

如果网络异常,图片加载失败,就会显示图片的默认文案,这个文案其实就是这个图片的属性信息:

我们查看一下这个结构的 HTML(查看方法可见 CSS 选择器的使用的第一节内容),就会发现图片的默认文案其实就是这个 <img/> 标签的 alt 属性:

我们可以看一下 HTML 文档里对 alt 属性的描述:
alt 属性是一个必需的属性,它规定在图像无法显示时的替代文本
在 web scraper 里,我们可以利用 Element attribute 属性来抓取这种属性信息。
因为这次的内容比较简单,新建 sitemap 这一步我就先省略了,我们直接上来使用 Element attribute 抓取数据。
我们把 Type 选为 Element attribute,然后用 Selector 选中图片这个元素:
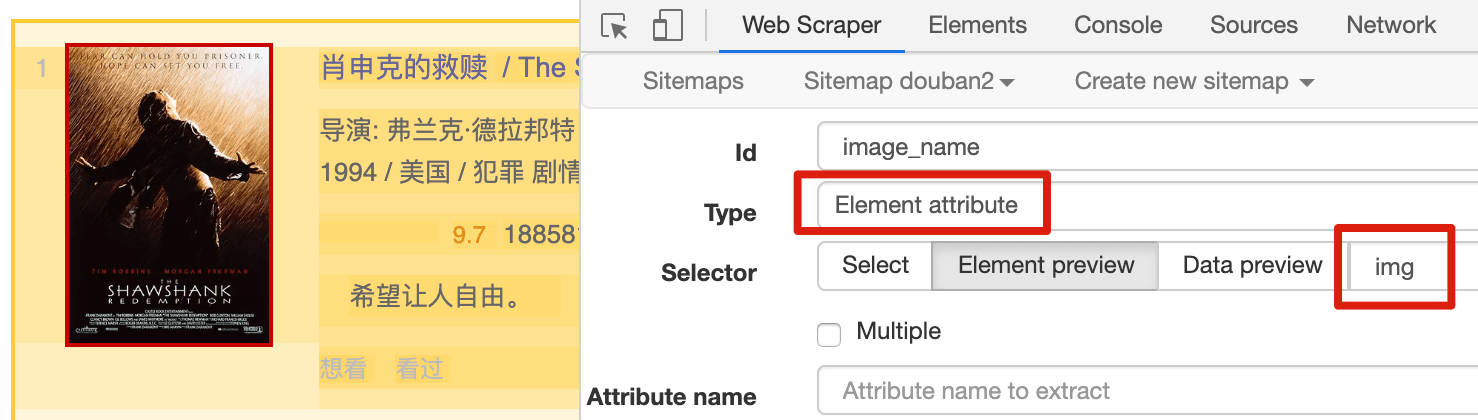
Element attribute 会多一个选项——Attribute name,我们在这个输入框里输入我们要抓取的属性名字。
观察一下这个 img 标签的属性,有 alt(替换文本)、width(图片宽度)和 src(图片链接)3 种:

这里我先输入 alt,表示抓取图片的替代文本:

还可以输入 src,表示抓取图片的链接:

也可以输入 width,抓取图片宽度:

通过 Element attribute 这个选择器,我们就可以抓取一些网页没有直接展示出来的数据信息,非常的方便。
sitemap 分享
{"_id":"douban2","startUrl":["https://movie.douban.com/top250?start=0&filter="],"selectors":[{"id":"ele","type":"SelectorElement","parentSelectors":["_root"],"selector":".grid_view li","multiple":true,"delay":0},{"id":"image_name","type":"SelectorElementAttribute","parentSelectors":["ele"],"selector":"img","multiple":false,"extractAttribute":"alt","delay":0}]}
推荐阅读
Web Scraper 高级用法——CSS 选择器的使用 | 简易数据分析 15
联系我
因为文章发在各大平台上,账号较多不能及时回复评论和私信,有问题可关注公众号 ——「卤蛋实验室」,(或 wx 搜索 egglabs)关注上车防失联。

Web Scraper 高级用法——抓取属性信息 | 简易数据分析 16的更多相关文章
- Web Scraper 高级用法——使用 CouchDB 存储数据 | 简易数据分析 18
这是简易数据分析系列的第 18 篇文章. 利用 web scraper 抓取数据的时候,大家一定会遇到一个问题:数据是乱序的.在之前的教程里,我建议大家利用 Excel 等工具对数据二次加工排序,但还 ...
- Web Scraper 翻页——控制链接批量抓取数据(Web Scraper 高级用法)| 简易数据分析 05
这是简易数据分析系列的第 5 篇文章. 上篇文章我们爬取了豆瓣电影 TOP250 前 25 个电影的数据,今天我们就要在原来的 Web Scraper 配置上做一些小改动,让爬虫把 250 条电影数据 ...
- 简易数据分析 12 | Web Scraper 翻页——抓取分页器翻页的网页
这是简易数据分析系列的第 12 篇文章. 前面几篇文章我们介绍了 Web Scraper 应对各种翻页的解决方法,比如说修改网页链接加载数据.点击"更多按钮"加载数据和下拉自动加载 ...
- Web Scraper 高级用法——利用正则表达式筛选文本信息 | 简易数据分析 17
这是简易数据分析系列的第 17 篇文章. 学习了这么多课,我想大家已经发现了,web scraper 主要是用来爬取文本信息的. 在爬取的过程中,我们经常会遇到一个问题:网页上的数据比较脏,我们只需要 ...
- 简易数据分析 15 | Web Scraper 高级用法——CSS 选择器的使用
这是简易数据分析系列的第 15 篇文章. 年末事情比较忙,很久不更新了,后台一直有读者催更,我看了一些读者给我的私信,发现一些通用的问题,所以单独写篇文章,介绍一些 Web Scraper 的进阶用法 ...
- 简易数据分析 10 | Web Scraper 翻页——抓取「滚动加载」类型网页
这是简易数据分析系列的第 10 篇文章. 友情提示:这一篇文章的内容较多,信息量比较大,希望大家学习的时候多看几遍. 我们在刷朋友圈刷微博的时候,总会强调一个『刷』字,因为看动态的时候,当把内容拉到屏 ...
- Fiddler高级用法-抓取手机app数据包
在上一篇中介绍了Fiddler的基本使用方法.通过上一篇的操作我们可以直接抓取浏览器的数据包.但在APP测试中,我们需要抓取手机APP上的数据包,应该怎么操作呢? Andriod配置方法 1)确保手机 ...
- 简易数据分析 04 | Web Scraper 初尝--抓取豆瓣高分电影
这是简易数据分析系列的第 4 篇文章. 今天我们开始数据抓取的第一课,完成我们的第一个爬虫.因为是刚刚开始,操作我会讲的非常详细,可能会有些啰嗦,希望各位不要嫌弃啊:) 有人之前可能学过一些爬虫知识, ...
- 网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(3): 抓取amazon.com价格
通过上一篇随笔的处理,我们已经拿到了书的书名和ISBN码.(网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(2): 抓取allitebooks.com书籍信息 ...
随机推荐
- Android开发学习1----AndroidStudio的安装、创建第一个Android Studio文件、Android Studio界面介绍和HelloWord!
移动开发的工具有很多:Android Studio,eclipse,Hbuilder等,其中,现如今最火的开发工具是Android Studio,Android Studio是谷歌自己推出的一款集成开 ...
- Downton Abbey
1. 当女儿以为泰坦尼克号不会沉的时候,父亲用了一个有意思的比喻: - I thought it was supposed to be unsinkable. - Every mountain is ...
- rare alleles
I.4 Where the rare alleles are found p是基因A的频率,N是个体数目(也就是基因型个数,所以基因个数是2n,所以全部个体的基因A的个数是2np),p方是PAA,np ...
- Opencv笔记(十三)——图像的梯度
目标 认识图像梯度.边界 学习函数cv2.Sobel(),cv2.Schar(),cv2.Laplacian() 原理 图像梯度可以把图像看成二维离散函数,图像梯度其实就是这个二维离散函数的求导.Op ...
- 三、linux-mysql mysql的多实例
1.什么是mysql多实例 一个机器开通多个端口,运行多个mysql服务器进程,这些服务进程通过不同的socket监听不同的服务端口提供各自的服务,但它们共用一台mysql安装程序,使用不同的my.c ...
- 27)PHP,视图
其实,视图就是一堆select形成的一个表格,但是这个表格也是存在一个数据库里面的,但是,他不会和一般的表格似得在数据库中显示,就好像虚拟存储器的那种感觉一样. 比如 必看我的一下句子 create ...
- nginx.conf文件详解
https://www.jb51.net/article/103968.htm https://www.cnblogs.com/zhang-shijie/p/5428640.html https:// ...
- jQ给下拉框绑定事件,为什么要绑定在框(select标签)上,而不是绑定在选项(option标签)上
这是我在学习锋利的 jquery 书中 5.1.4 的代码时遇到的一个小问题,源代码如下: <head> <style type="text/css"> * ...
- [LC] 426. Convert Binary Search Tree to Sorted Doubly Linked List
Convert a BST to a sorted circular doubly-linked list in-place. Think of the left and right pointers ...
- GIL锁和进程/线程池
GIL锁 1.GIL锁 全局解释器锁,就是一个把互斥锁,将并发变成串行,同一时刻只能有一个线程使用共享资源,牺牲效率,保证数据安全,也让程序员避免自己一个个加锁,减轻开发负担 带来的问题 感觉单核处理 ...