常用正则表达式最强汇总(含Python代码举例讲解+爬虫实战)
大家好,我是辰哥~
本文带大家学习正则表达式,并通过python代码举例讲解常用的正则表达式
最后实战爬取小说网页:重点在于爬取的网页通过正则表达式进行解析。
正则表达式语法
Python的re模块(正则表达式)提供各种正则表达式的匹配操作。在绝大多数情况下能够有效地实现对复杂字符串的分析并取出相关信息。在讲解如何实际应用正则表达式之前,先教大家学习并掌握正则表达式的基本语法(匹配规则)。
正则表达式匹配过程如下:
(1)将定义好的正则表达式和字符串进行比较。
(2)如果每一个字符串都能匹配,则成功;一旦有匹配不成功的字符则匹配失败。
正则表达式规则
常见规则
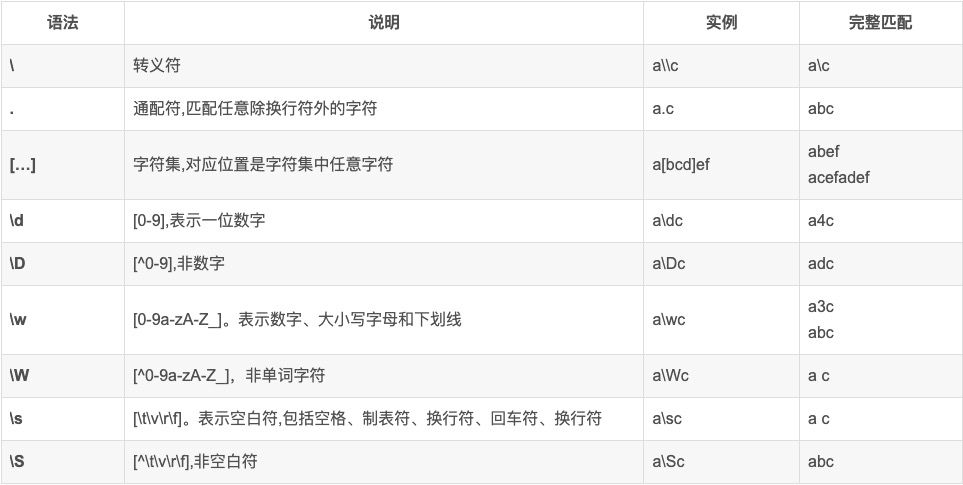
数量词匹配规则
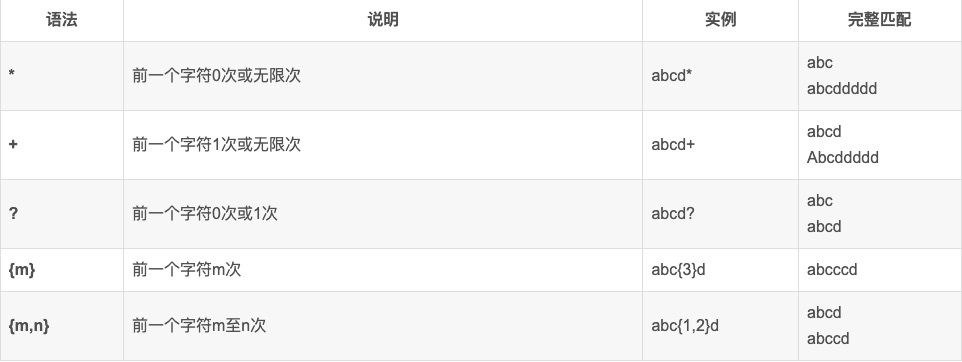
边界匹配规则

Re模块
Python中使用Re库去定义的正则表达式,常用的方法列举如下:
lpattern对象
re.compile(string[,flag])
l匹配所用函数
re.match(pattern, string[, flags])
re.search(pattern, string[, flags])
re.split(pattern, string[, maxsplit])
re.findall(pattern, string[, flags])
re.finditer(pattern, string[, flags])
re.sub(pattern, repl, string[, count])
re.subn(pattern, repl, string[, count])
其中pattern对象是由我们传入字符串对象,通过compile方法生成。利用这个对象来进行下一步的匹配。针对上述列举的各种正则表达式匹配规则和函数,下面通过Python代码进行举例讲解。
(1) re.match(pattern, string[, flags])
match函数将会从String(待匹配的字符串)的开头开始,尝试匹配pattern,一直向后匹配。如果中途匹配pattern成功,则终止匹配,返回匹配结果。如果无法匹配或者到字符串末尾还未匹配到,则返回None。
举例:
#导入re模块
import re
pattern = re.compile(r'python')
# 使用re.match匹配文本,获得匹配结果,无法匹配时将返回None
result1 = re.match(pattern,'python')
result2 = re.match(pattern,'pythonn CQC!')
result3 = re.match(pattern,'pthon CQC!')
print(result1)
print(result2)
print(result3)
"""
结果:
<_sre.SRE_Match object; span=(0, 6), match='python'>
<_sre.SRE_Match object; span=(0, 6), match='python'>
None
"""
(2) re.search(pattern, string[, flags])
Search函数会扫描整个string字符串查找匹配,存在的话返回匹配结果,不存在则返回None。
举例:
import re
pattern = re.compile(r'python')
#从“hello pythonnnnn!”中匹配“python”
result1 = re.search(pattern,'hello pythonnnnn!')
#从“hello pyhon!”中匹配“python”
result2 = re.search(pattern,'hello pyhon!')
print(result1)
print(result2)
"""
结果:
<_sre.SRE_Match object; span=(6, 12), match='python'>
None
"""
(3) re.split(pattern, string[, maxsplit])
split函数可以按照pattern匹配模式将string字符串分割后返回列表,其中maxsplit参数可以指定最大分割次数,不指定则将字符串全部分割。
举例:
import re
#以一位或者多位数字作为分割间隔
pattern = re.compile(r'\d+')
print(re.split(pattern,'python1java2php3js'))
#只分割两次
print(re.split(pattern,'python1java2php3js',maxsplit=2))
"""
结果:
['python', 'java', 'php', 'js']
['python', 'java', 'php3js']
"""
(4) re.findall(pattern, string[, flags])
findall函数作用是搜索整个字符串,以列表形式返回全部能匹配的子串。
举例:
import re
pattern = re.compile(r'\d+')
print(re.findall(pattern,'python1java2php3js2245'))
"""
结果:
['1', '2', '3', '2245']
"""
(5) re.finditer(pattern, string[, flags])
finditer函数作用是搜索整个字符串,返回一个符合匹配结果(Match对象)的迭代器。
举例:
import re
#以一位或者多位数字作为搜索条件
pattern = re.compile(r'\d+')
#搜索结果得到一个集合,通过循环对集合遍历输出
for item in re.finditer(pattern,'python1java2php3js2245'):
print(item.group())
"""
结果:
1
2
3
2245
"""
(6) re.sub(pattern, repl, string[, count])
先看两个例子,然后再解释这个sub函数的作用。
举例:
import re
pattern1 = re.compile(r'music')
#例1中“i love the music”里的music替换成python
print(re.sub(pattern1, 'python', 'i love the music'))
pattern2 = re.compile(r'(\d+)')
#例2中“数字123 和9”被python替换。
print(re.sub(pattern2, 'python', 'My number is 123 and my favorite number is 9'))
"""
结果:
i love the python
My number is python and my favorite number is python
"""
(7) re.subn(pattern, repl, string[, count])
subn可以指定替换次数,不指定则默认替换全部。
举例:
import re
#以一位或者多位数字作为替换条件
pattern1 = re.compile(r'(\d+)')
#用“python”替换数字(一位或者多位),最后返回替换结果和替换次数
print(re.subn(pattern1, 'python', 'My number is 123 and my favorite number is 9'))
pattern2 = re.compile(r'(\d+)')
print(re.subn(pattern2, 'python', 'My number is 123 and my favorite number is 9',1))
"""
结果:
('My number is python and my favorite number is python', 2)
('My number is python and my favorite number is 9', 1)
"""
实战
需求:提取小说章节正文和标题
本节通过实战案例来讲解正则表达式的应用。案例目的是:提取小说章节内容。步骤是先采集到每一章小说正文内容网页源码,然后通过正则表达式将里面的正文提取出来。
这里爬取小说 第一章 北灵院,用正则表达式提取小说章节正文和标题
目标链接:http://book.chenlove.cn/book/12242/39a44ff6dd27f.html
页面如下:
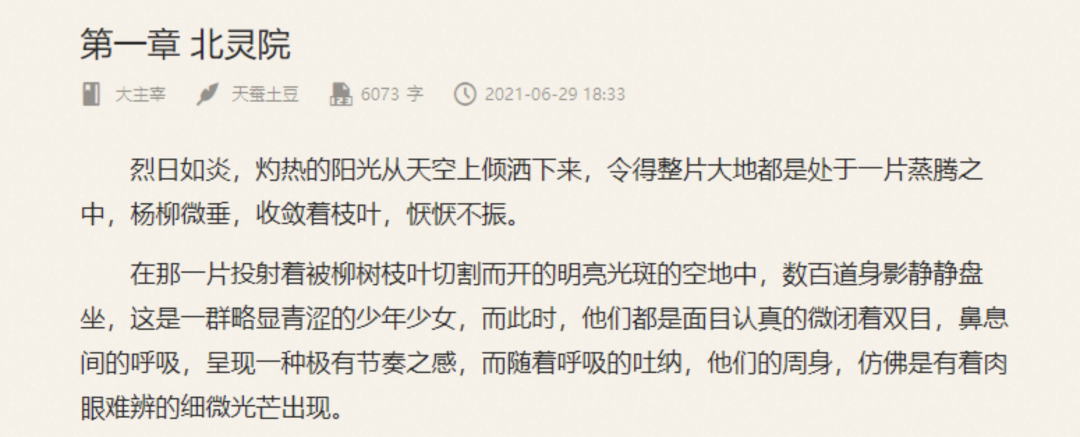
分析网页源码:

可以看到章节标题在h3标签中,其class为j_chapterName;正文内容在p标签中,清楚这些之后,下面开始编写代码请求网页源码,并编写正则表达式去提取标题和正文。
完整代码如下:
import requests
import re
import json
# 设置代理服务器
headers = {
'User_Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36'
}
#请求连接
url = "http://book.chenlove.cn/book/12242/39a44ff6dd27f.html"
response = requests.get(url, headers=headers)
if response.status_code == 200:
# 转化为utf-8格式,不加这条语句,输出爬取的信息为乱码
response.encoding = 'utf8'
#获取到源码
html = response.text
# 正则表达式解析小说章节标题
pattern1 = re.compile('<h3>(.+)</h3>')
title = re.findall(pattern1, html)[0]
#正则表达式解析小说章节正文内容
text = re.findall(r"<p>(.*?)</p>", html,re.S)[2:-1][0].split("</div>")[0]
# 打印输出
print(title)
print(text)
"""
结果:
第一章 北灵院
烈日如炎,灼热的阳光从天空上倾洒下来,令得整片大地都是处于一片蒸腾之中,杨柳微垂,......
"""
可以看到第一章的标题和正文已经成功提取出来了,因为正文内容很长,这里仅展示部分。
最后
本文汇总正则表达式常用的基本语法,并结合Python进行举例演示
最后实战讲解正则表达式在爬虫中的应用。
常用正则表达式最强汇总(含Python代码举例讲解+爬虫实战)的更多相关文章
- 一文看懂Stacking!(含Python代码)
一文看懂Stacking!(含Python代码) https://mp.weixin.qq.com/s/faQNTGgBZdZyyZscdhjwUQ
- 智普教育Python培训之Python开发视频教程网络爬虫实战项目
网络爬虫项目实训:看我如何下载韩寒博客文章Python视频 01.mp4 网络爬虫项目实训:看我如何下载韩寒博客文章Python视频 02.mp4 网络爬虫项目实训:看我如何下载韩寒博客文章Pytho ...
- JAVA十大经典排序算法最强总结(含JAVA代码实现)
0.排序算法说明 0.1 排序的定义 对一序列对象根据某个关键字进行排序. 0.2 术语说明 稳定:如果a原本在b前面,而a=b,排序之后a仍然在b的前面: 不稳定:如果a原本在b的前面,而a=b,排 ...
- python动态网站爬虫实战(requests+xpath+demjson+redis)
目录 前言 一.主要思路 1.观察网站 2.编写爬虫代码 二.爬虫实战 1.登陆获取cookie 2.请求资源列表页面,定位获得左侧目录每一章的跳转url(难点) 3.请求每个跳转url,定位右侧下载 ...
- [python] 常用正则表达式爬取网页信息及分析HTML标签总结【转】
[python] 常用正则表达式爬取网页信息及分析HTML标签总结 转http://blog.csdn.net/Eastmount/article/details/51082253 标签: pytho ...
- 十大经典排序算法最强总结(含JAVA代码实现)(转)
十大经典排序算法最强总结(含JAVA代码实现) 最近几天在研究排序算法,看了很多博客,发现网上有的文章中对排序算法解释的并不是很透彻,而且有很多代码都是错误的,例如有的文章中在“桶排序”算法中对每 ...
- 正则表达式入门-python代码
题记 本文介绍了Python对于正则表达式的支持,包括正则表达式基础以及Python正则表达式标准库的完整介绍及使用示例. 正则表达式在很多的应用中都有使用到,特别是在网络爬虫中格式化html后取出自 ...
- PHP常用正则表达式汇总 [复制链接]
PHP常用正则表达式汇总 [复制链接] 上一主题下一主题 离线我是小猪头 法师 发帖 539 加关注 发消息 只看楼主 倒序阅读 使用道具楼主 发表于: 2011-06-22 更多 ...
- PDB调试python代码常用命令
常用命令 where(w) 找出当前代码运行位置 list(l) 显示当前代码的部分上下文 list n(line number) 显示指定行的上下文 list m, n(line number) 显 ...
随机推荐
- ARTS第十一周
受辞职考研和新冠肺炎疫情影响,一直没更.遗憾,数学和专业课再高点就有戏了.继续. 1.Algorithm:每周至少做一个 leetcode 的算法题2.Review:阅读并点评至少一篇英文技术文章3. ...
- RWLock——一种细粒度的Mutex互斥锁
RWMutex -- 细粒度的读写锁 我们之前有讲过 Mutex 互斥锁.这是在任何时刻下只允许一个 goroutine 执行的串行化的锁.而现在这个 RWMutex 就是在 Mutex 的基础上进行 ...
- C语言:fopen
fopen,传递文件名参数,w+选项读取用fread或fgets,其中fread是按字节读取,fgets每次读取一个字符串写入用fwrite或fputs或fprintf,fwrite按字节写入,fpu ...
- BiPredicate的test()方法
/** * BiPredicate的test()方法接受两个参数,x和y,具体实现为x.equals(y), * 满足Lambda参数列表中的第一个参数是实例方法的参数调用者,而第二个参数是实例方法的 ...
- 9Java基础总结
1.psvm定义的意义 public:保证了方法的访问权限 static:保证在类未被实例化的时候就能调用(加载的时机) void:不需要返回值 main:约定俗成的名字 String[] args: ...
- 【Lucas组合数定理】组合-FZU 2020
组合 FZU-2020 题目描述 给出组合数C(n,m), 表示从n个元素中选出m个元素的方案数.例如C(5,2) = 10, C(4,2) = 6.可是当n,m比较大的时候,C(n,m)很大!于是x ...
- Table类
Interpreter类, class Interpreter: public CC_INTERP_ONLY(CppInterpreter) NOT_CC_INTERP(TemplateInterpr ...
- vscode安装ESlint配置
先安装插件ESLint,后面在设置setting.json中配置加入代码: { "files.autoSave": "afterDelay", "ed ...
- Resnet网络详细结构(针对Cifar10)
Resnet网络详细结构(针对Cifar10) 结构 具体结构(Pytorch) conv1 (conv1): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, ...
- Mysql命令语句
常用的管理命令 SHOW DATABASES; //显示当前服务器下所有的数据库 USE 数据库名称; //进入指定的数据 show tables; ...