HashTable原理和底层实现
1. 概述
上次讨论了HashMap的结构,原理和实现,本文来对Map家族的另外一个常用集合HashTable进行介绍。HashTable和HashMap两种集合非常相似,经常被各种面试官问到两者的区别。
对于两者的区别,主要有以下几点:
- HashMap是非同步的,没有对读写等操作进行锁保护,所以是线程不安全的,在多线程场景下会出现数据不一致的问题。而HashTable是同步的,所有的读写等操作都进行了锁(
synchronized)保护,在多线程环境下没有安全问题。但是锁保护也是有代价的,会对读写的效率产生较大影响。 - HashMap结构中,是允许保存
null的,Entry.key和Entry.value均可以为null。但是HashTable中是不允许保存null的。 - HashMap的迭代器(
Iterator)是fail-fast迭代器,但是Hashtable的迭代器(enumerator)不是fail-fast的。如果有其它线程对HashMap进行的添加/删除元素,将会抛出ConcurrentModificationException,但迭代器本身的remove方法移除元素则不会抛出异常。这条同样也是Enumeration和Iterator的区别。2. 原理
HashTable类中,保存实际数据的,依然是
Entry对象。其数据结构与HashMap是相同的。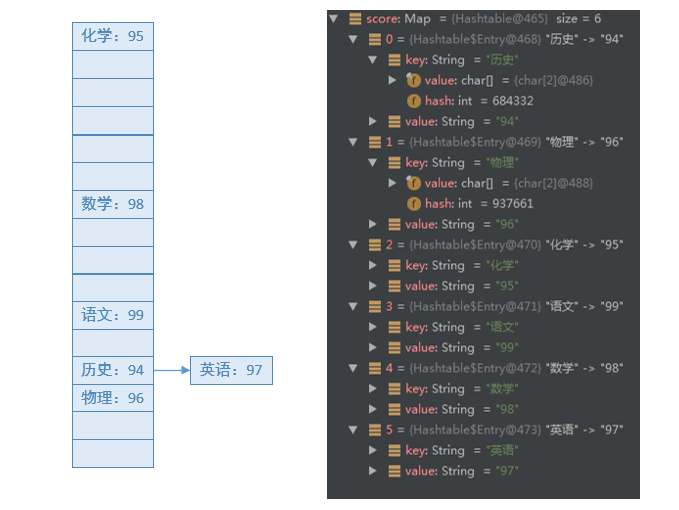
HashTable类继承自Dictionary类,实现了三个接口,分别是Map,Cloneable和java.io.Serializable,如下图所示。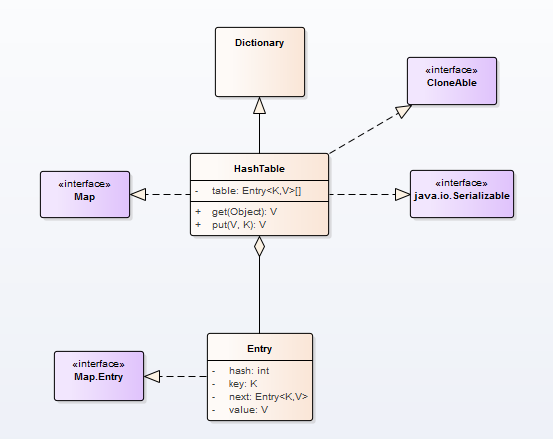
HashTable中的主要方法,如put,get,remove和rehash等,与HashMap中的功能相同,这里不作赘述,可以参考另外一篇文章HashMap原理和底层实现
3. 源码分析
HashTable的主要方法的源码实现逻辑,与HashMap中非常相似,有一点重大区别就是所有的操作都是通过synchronized锁保护的。只有获得了对应的锁,才能进行后续的读写等操作。
1. put方法
put方法的主要逻辑如下:
- 先获取
synchronized锁。 - put方法不允许
null值,如果发现是null,则直接抛出异常。 - 计算
key的哈希值和index - 遍历对应位置的链表,如果发现已经存在相同的hash和key,则更新value,并返回旧值。
- 如果不存在相同的key的Entry节点,则调用
addEntry方法增加节点。 addEntry方法中,如果需要则进行扩容,之后添加新节点到链表头部。
public synchronized V put(K key, V value) {
// Make sure the value is not null
if (value == null) {
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
Entry<K,V> entry = (Entry<K,V>)tab[index];
for(; entry != null ; entry = entry.next) {
if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
entry.value = value;
return old;
}
}
addEntry(hash, key, value, index);
return null;
} private void addEntry(int hash, K key, V value, int index) {
modCount++;
Entry<?,?> tab[] = table;
if (count >= threshold) {
// Rehash the table if the threshold is exceeded
rehash();
tab = table;
hash = key.hashCode();
index = (hash & 0x7FFFFFFF) % tab.length;
}
// Creates the new entry.
@SuppressWarnings("unchecked")
Entry<K,V> e = (Entry<K,V>) tab[index];
tab[index] = new Entry<>(hash, key, value, e);
count++;
}2. get方法
get方法的主要逻辑如下
- 先获取
synchronized锁。 - 计算key的哈希值和index。
- 在对应位置的链表中寻找具有相同hash和key的节点,返回节点的value。
- 如果遍历结束都没有找到节点,则返回
null。
public synchronized V get(Object key) {
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<?,?> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return (V)e.value;
}
}
return null;
}3.rehash扩容方法
rehash扩容方法主要逻辑如下:
- 数组长度增加一倍(如果超过上限,则设置成上限值)。
- 更新哈希表的扩容门限值。
- 遍历旧表中的节点,计算在新表中的index,插入到对应位置链表的头部。
protected void rehash() {
int oldCapacity = table.length;
Entry<?,?>[] oldMap = table;
// overflow-conscious code
int newCapacity = (oldCapacity << 1) + 1;
if (newCapacity - MAX_ARRAY_SIZE > 0) {
if (oldCapacity == MAX_ARRAY_SIZE)
// Keep running with MAX_ARRAY_SIZE buckets
return;
newCapacity = MAX_ARRAY_SIZE;
}
Entry<?,?>[] newMap = new Entry<?,?>[newCapacity];
modCount++;
threshold = (int)Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
table = newMap;
for (int i = oldCapacity ; i-- > 0 ;) {
for (Entry<K,V> old = (Entry<K,V>)oldMap[i] ; old != null ; ) {
Entry<K,V> e = old;
old = old.next;
int index = (e.hash & 0x7FFFFFFF) % newCapacity;
e.next = (Entry<K,V>)newMap[index];
newMap[index] = e;
}
}
}4.remove方法
remove方法主要逻辑如下:
- 先获取synchronized锁。
- 计算key的哈希值和index。
- 遍历对应位置的链表,寻找待删除节点,如果存在,用
e表示待删除节点,pre表示前驱节点。如果不存在,返回null。 - 更新前驱节点的
next,指向e的next。返回待删除节点的value值。
4. 总结
HashTable相对于HashMap的最大特点就是线程安全,所有的操作都是被synchronized锁保护的
作者:道可
链接:https://www.imooc.com/article/details/id/23015
来源:慕课网
本文原创发布于慕课网 ,转载请注明出处,谢谢合作
HashTable原理和底层实现的更多相关文章
- Android摄像头:只拍摄SurfaceView预览界面特定区域内容(矩形框)---完整(原理:底层SurfaceView+上层绘制ImageView)
Android摄像头:只拍摄SurfaceView预览界面特定区域内容(矩形框)---完整实现(原理:底层SurfaceView+上层绘制ImageView) 分类: Android开发 Androi ...
- HashMap与HashTable原理及数据结构
HashMap与HashTable原理及数据结构 hash表结构个人理解 hash表结构,以计算出的hashcode或者在hashcode基础上加工一个hash值,再通过一个散列算法 获取到对应的数组 ...
- java8 HashTable 原理
HashTable原理 Hashtable是基于陈旧的Dictionary类的,HashMap是Java 1.2引进的Map接口的一个实现.Hashtable中的方法是同步的,而HashMap方法(在 ...
- HashMap的实现原理和底层数据结构
看了下Java里面有HashMap.Hashtable.HashSet三种hash集合的实现源码,这里总结下,理解错误的地方还望指正 HashMap和Hashtable的区别 HashSet和Hash ...
- Git 内部原理 - (1)底层命令和高层命令 (2Git 对象
文章摘选自git官网,这里复制下来表示我已阅读并学习过一次这些内容: 无论是从之前的章节直接跳到本章,还是读完了其余章节一直到这——你都将在本章见识到 Git 的内部工作原理和实现方式. 我们发现学习 ...
- Java集合详解(五):Hashtable原理解析
概述 本文是基于jdk8_271版本进行分析的. Hashtable与HashMap一样,是一个存储key-value的双列集合.底层是基于数组+链表实现的,没有红黑树结构.Hashtable默认初始 ...
- <TCP/IP原理> (三) 底层网络技术
传输介质 局域网(LAN) 交换(Switching) 广域网(WAN) 连接设备 第三章 底层网络技术 引言 1)Interne不是一种新的网络 建立在底层网络上的网际网 底层网络——“物理网”,网 ...
- HashTable原理与源码分析
本文版权归 远方的风lyh和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作,如有错误之处忘不吝批评指正! HashTable内部存储结构 HashTable内部存储结构为数组+单向链 ...
- 五.HashTable原理及实现学习总结
有两个类都提供了一个多种用途的hashTable机制,他们都可以将可以key和value结合起来构成键值对通过put(key,value)方法保存起来,然后通过get(key)方法获取相对应的valu ...
随机推荐
- Python爬取网易云热歌榜所有音乐及其热评
获取特定歌曲热评: 首先,我们打开网易云网页版,击排行榜,然后点击左侧云音乐热歌榜,如图: 关于如何抓取指定的歌曲的热评,参考这篇文章,很详细,对小白很友好: 手把手教你用Python爬取网易云40万 ...
- python3执行.sql文件
这个脚本主要是遍历执行文件夹下的sql文件,但是没有辨别文件的格式,所以文件夹下只能够放.sql文件,否则会报错哈. 我的sql文件夹与执行的文件平级,所以dir_path就是sql,大家依照自己的路 ...
- UBUNTU 16.04 LTS SERVER 手动升级 MariaDB 到最新版 10.2
UBUNTU 16.04 LTS SERVER 手动升级 MariaDB 到最新版 10.2 1. 起因 最近因为不同软件的数据问题本来只是一些小事弄着弄着就越弄越麻烦了,期间有这么个需求,没看到有中 ...
- Docker隔离技术
前言 Docker系列文章: 此篇是Docker系列的第九篇,之前的文章里面或多或少的提到Docker的隔离技术,但是没有很清楚的去聊这个技术,但是经过这么多文章大家一定对Docker使用和概念有了一 ...
- 🔥 LeetCode 热题 HOT 100(31-40)
75. 颜色分类 思路:将 2 往后放,0 往前放,剩余的1自然就放好了. 使用双指针:left.right 分别指向待插入的 0 和 2 的位置,初始 left 指向数组头,right 指向数组尾部 ...
- 数据结构——图的深度优先遍历(邻接矩阵表示+java版本)
1.深度优先遍历(DFS) 图的深度优先遍历本质上是一棵树的前序遍历(即先遍历自身,然后遍历其左子树,再遍历右子树),总之图的深度优先遍历是一个递归的过程. 如下图所示,左图是一个图,右图是图的深度 ...
- 查看Android 系统发送的广播
命令行输入如下命令 adb shell dumpsys |grep BroadcastRecord
- 小马哥的 Java 项目实战营学习笔记(1)
小马哥的 Java 项目实战营 小马哥的 Java 项目实战营 第二节:数据存储之 JDBC JDBC 核心 API 数据源 接口 - javax.sql.DataSource获取方式 1.普通对象初 ...
- [洛谷P3376题解]网络流(最大流)的实现算法讲解与代码
[洛谷P3376题解]网络流(最大流)的实现算法讲解与代码 更坏的阅读体验 定义 对于给定的一个网络,有向图中每个的边权表示可以通过的最大流量.假设出发点S水流无限大,求水流到终点T后的最大流量. 起 ...
- 流量加密-Kali使用Openssl反弹shell
Kali使用Openssl反弹shell 前言 之前在护网的时候,如果流量中有明文的敏感信息,譬如攻击特征,是很容易被IDS检测出来的,此时红队的攻击行为就会暴露.这是非常危险的一件事.今天我们通过本 ...