大数据学习(19)—— Flume环境搭建
系统要求
- Java1.8或以上
- 内存要足够大
- 硬盘足够大
- Agent对源和目的要有读写权限
Flume部署
我这8G内存的电脑之前搭建Hadoop、Hive和HBase已经苟延残喘了,怀疑会卡死,硬着头皮上吧。先解压缩,大数据的这些产品都是一个部署套路。
我准备在server01上部署flume,单节点就可以了。在公司生产环境部署要考虑高可用。
[root@server01 home]# tar -xvf apache-flume-1.9.0-bin.tar.gz -C /usr
[root@server01 home]# cd /usr
[root@server01 usr]# chown -R hadoop:hadoop apache-flume-1.9.0-bin/
[root@server01 usr]# mv apache-flume-1.9.0-bin/ apache-flume-1.9.0
在profile文件中添加配置
FLUME_HOME=/usr/apache-flume-1.9.0/
PATH=$PATH:$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin:$HBASE_HOME/bin:$FLUME_HOME/bin
刷新配置文件
[root@server01 bin]# source /etc/profile
修改flume配置文件
[hadoop@server01 conf]$ pwd
/usr/apache-flume-1.9.0/conf
[hadoop@server01 conf]$ mv flume-env.sh.template flume-env.sh
[hadoop@server01 conf]$ vi flume-env.sh
把flume-env.sh里的JAVA_HOME修改为绝对路径
export JAVA_HOME=/usr/java/jdk1.8.0
Flume启动
我们试一下通过网络端口写入数据。新建一个配置文件。
[hadoop@server01 conf]$ vi config1
数据流向:telent -> source -> channel -> sink -> logger
具体配置内容如下。
[hadoop@server01 conf]$ cat config1
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = server01
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
启动flume。注意flume1.0以后叫ng(next generation),之前叫og(original generation)。
[hadoop@server01 apache-flume-1.9.0]$ flume-ng agent --conf conf --conf-file conf/config1 --name a1 -Dflume.root.logger=INFO,console
启动之后,另开server02对44444端口发送数据。
[hadoop@server02 ~]$ telnet server01 44444
Trying 182.182.0.8...
Connected to server01.
Escape character is '^]'.
hello
OK
thank you
OK
thank you very much
OK
how are you everyone
OK
看看server01控制台输出了啥。
2021-01-07 11:17:14,198 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 0D hello. }
2021-01-07 11:18:24,209 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 74 68 61 6E 6B 20 79 6F 75 0D thank you. }
2021-01-07 11:18:34,088 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 74 68 61 6E 6B 20 79 6F 75 20 76 65 72 79 20 6D thank you very m }
2021-01-07 11:18:51,602 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 6F 77 20 61 72 65 20 79 6F 75 20 65 76 65 72 how are you ever }
我们可以看到,控制台只会输出前面几个字节的内容,但是信息已经获取到了。
再来一个例子
上面是一个最简单的例子,从网络端口获取数据,输出到控制台。再来一个复杂一点的,从日志文件获取增量数据,写入HDFS。
做过开发的都清楚用tail -f filename来查看最新的请求日志,配置文件新建config2,内容如下。
[hadoop@server01 conf]$ cat config2
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1 # Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/log.txt # Describe the sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://mycluster/flume
a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.rollInterval = 10
a1.sinks.k1.hdfs.rollSize = 0
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.filePrefix = %Y-%m-%d
a1.sinks.k1.hdfs.useLocalTimeStamp = true # Use a channel which buffers events in file
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
启动hdfs,用上面的配置文件启动flume。
[hadoop@server01 apache-flume-1.9.0]$ flume-ng agent --name a1 --conf conf --conf-file conf/config2 -Dflume.root.logger=INFO,console
启动报错。
2021-01-07 19:19:51,905 (SinkRunner-PollingRunner-DefaultSinkProcessor) [ERROR - org.apache.flume.sink.hdfs.HDFSEventSink.process(HDFSEventSink.java:459)] process failed
java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)V
at org.apache.hadoop.conf.Configuration.set(Configuration.java:1380)
at org.apache.hadoop.conf.Configuration.set(Configuration.java:1361)
at org.apache.hadoop.conf.Configuration.setBoolean(Configuration.java:1703)
at org.apache.flume.sink.hdfs.BucketWriter.open(BucketWriter.java:221)
at org.apache.flume.sink.hdfs.BucketWriter.append(BucketWriter.java:572)
at org.apache.flume.sink.hdfs.HDFSEventSink.process(HDFSEventSink.java:412)
at org.apache.flume.sink.DefaultSinkProcessor.process(DefaultSinkProcessor.java:67)
at org.apache.flume.SinkRunner$PollingRunner.run(SinkRunner.java:145)
at java.lang.Thread.run(Thread.java:748)
Exception in thread "SinkRunner-PollingRunner-DefaultSinkProcessor" java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)V
at org.apache.hadoop.conf.Configuration.set(Configuration.java:1380)
at org.apache.hadoop.conf.Configuration.set(Configuration.java:1361)
at org.apache.hadoop.conf.Configuration.setBoolean(Configuration.java:1703)
at org.apache.flume.sink.hdfs.BucketWriter.open(BucketWriter.java:221)
at org.apache.flume.sink.hdfs.BucketWriter.append(BucketWriter.java:572)
at org.apache.flume.sink.hdfs.HDFSEventSink.process(HDFSEventSink.java:412)
at org.apache.flume.sink.DefaultSinkProcessor.process(DefaultSinkProcessor.java:67)
at org.apache.flume.SinkRunner$PollingRunner.run(SinkRunner.java:145)
at java.lang.Thread.run(Thread.java:748)
这跟Hive启动错误是一样的,原因就是与Hadoop的guava包版本不一致。把Hadoop的jar包拷到Flume路径下,删除老的jar包。在Flume的lib目录执行如下命令。
[hadoop@server01 lib]$ cp /usr/hadoop-3.3.0/share/hadoop/common/lib/guava-27.0-jre.jar .
[hadoop@server01 lib]$ ll|grep guava
-rw-rw-r--. 1 hadoop hadoop 1648200 9月 13 2018 guava-11.0.2.jar
-rw-r--r--. 1 hadoop hadoop 2747878 1月 12 11:42 guava-27.0-jre.jar
[hadoop@server01 lib]$ rm guava-11.0.2.jar
[hadoop@server01 lib]$ ll|grep guava
-rw-r--r--. 1 hadoop hadoop 2747878 1月 12 11:42 guava-27.0-jre.jar
再次启动Flume。启动完毕后,模拟向/home/log.txt写入数据,中间间隔一段时间。
[root@server01 home]# echo "hello,thank you,thank you very much" >> log.txt
[root@server01 home]# echo "How are you Indian Mi fans?" >> log.txt
再去看看HDFS生成的文件里有什么内容。
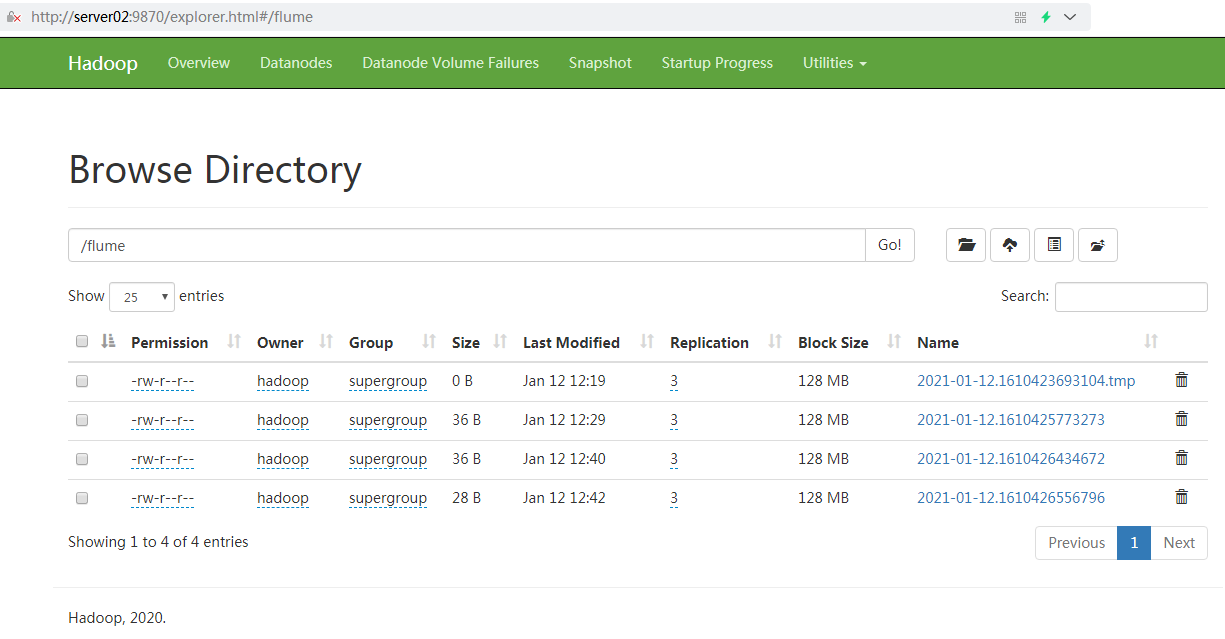
打开下面的两个文件,看看内容。原谅我不厚道地用了雷总歌词。
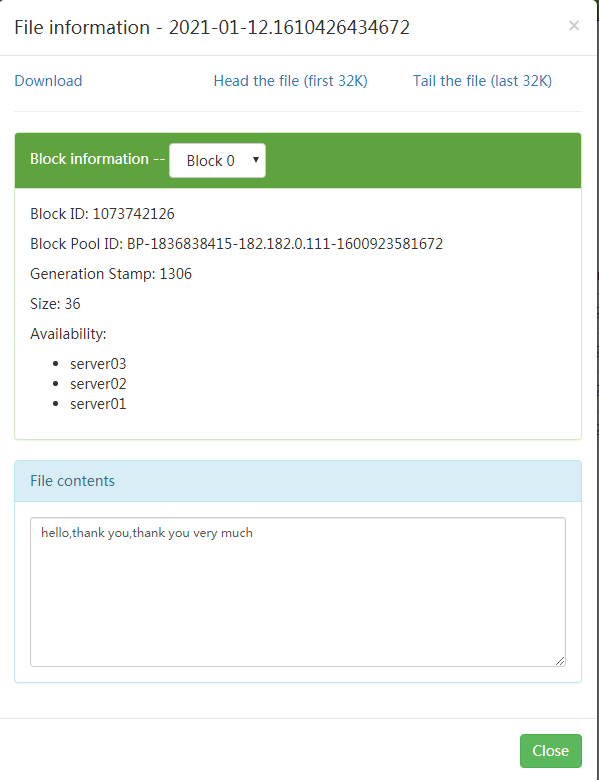
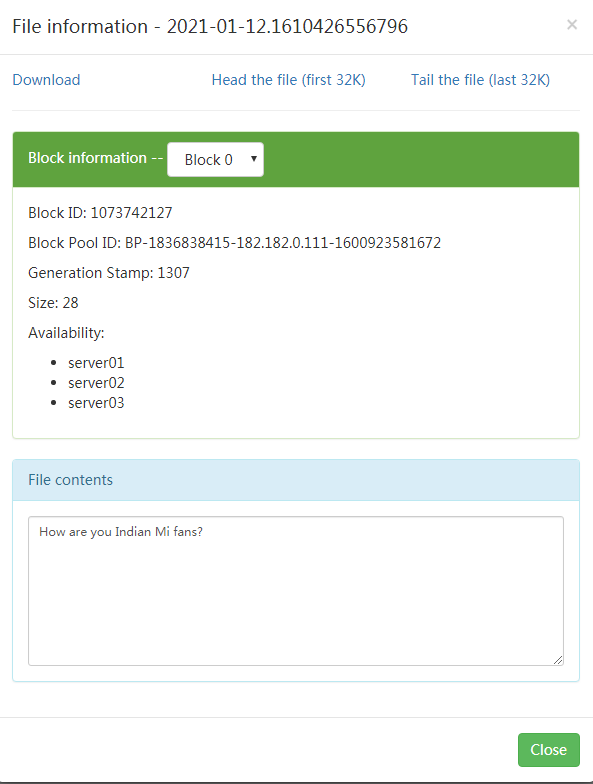
这样就把日志收集到HDFS了,后续可以通过MR任务来处理HDFS文件,提取需要的内容。
大数据学习(19)—— Flume环境搭建的更多相关文章
- 大数据学习之Hadoop环境搭建
一.Hadoop的优势 1)高可靠性:因为Hadoop假设计算元素和存储会出现故障,因为它维护多个工作数据副本,在出现故障时可以对失败的节点重新分布处理. 2)高扩展性:在集群间分配任务数据,可方便的 ...
- 《OD大数据实战》Flume环境搭建
一.CentOS 6.4安装Nginx http://shiyanjun.cn/archives/72.html 二.安装Flume 1. 下载flume-ng-1.5.0-cdh5.3.6.tar. ...
- 分享知识-快乐自己:大数据(hadoop)环境搭建
大数据 hadoop 环境搭建: 一):大数据(hadoop)初始化环境搭建 二):大数据(hadoop)环境搭建 三):运行wordcount案例 四):揭秘HDFS 五):揭秘MapReduce ...
- 大数据 -- Hadoop集群环境搭建
首先我们来认识一下HDFS, HDFS(Hadoop Distributed File System )Hadoop分布式文件系统.它其实是将一个大文件分成若干块保存在不同服务器的多个节点中.通过联网 ...
- 《OD大数据实战》Hive环境搭建
一.搭建hadoop环境 <OD大数据实战>hadoop伪分布式环境搭建 二.Hive环境搭建 1. 准备安装文件 下载地址: http://archive.cloudera.com/cd ...
- 【原创干货】大数据Hadoop/Spark开发环境搭建
已经自学了好几个月的大数据了,第一个月里自己通过看书.看视频.网上查资料也把hadoop(1.x.2.x).spark单机.伪分布式.集群都部署了一遍,但经历短暂的兴奋后,还是觉得不得门而入. 只有深 ...
- 《OD大数据实战》MongoDB环境搭建
一.MongonDB环境搭建 1. 下载 https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-3.0.6.tgz 2. 解压 tar -zxvf ...
- 《OD大数据实战》Hue环境搭建
官网: http://archive.cloudera.com/cdh5/cdh/5/hue-3.7.0-cdh5.3.6/ 一.Hue环境搭建 1. 下载 http://archive.cloude ...
- 大数据学习之路—环境配置——IP设置(虚拟机修改Ip的内在原因及实现)
一.IP原理 关于IP我的理解, (1)主要去理解IP地址的作用,IP地址包括网络相关部分和主机的相关部分.即:用一段特殊的数据,来标识网络特征和主机的特征. 至于具体的技术实现,日后可以慢慢体会和了 ...
- 《OD大数据实战》Storm环境搭建
一.环境搭建 1. 下载 http://www.apache.org/dyn/closer.lua/storm/apache-storm-0.9.6/apache-storm-0.9.6.tar.gz ...
随机推荐
- 树的计数(prufer序列 或 purfer序列)
题解 首先我们要知道一条性质,prufer序列中的某个点出现次数为该点在树中度数-1 感性理解一下,其实按照prufer序列求法自己推一下就出来了 设题目里给的度为$d[]$ 先将所有的d-- 然后按 ...
- CMD批处理(3)——批处理选择语句结构
if 的用法详解 命令格式1:if [NOT] ERRORLEVEL number command 命令格式2:if [NOT] string1==string2 command 命令格式3:if [ ...
- 精尽Spring Boot源码分析 - 内嵌Tomcat容器的实现
该系列文章是笔者在学习 Spring Boot 过程中总结下来的,里面涉及到相关源码,可能对读者不太友好,请结合我的源码注释 Spring Boot 源码分析 GitHub 地址 进行阅读 Sprin ...
- uniapp 打包IOS 更新AppStore版本
Hello 你好,我是大粽子. 最近随着新版本UI的发布APP也随之更新,随之而来的也就是IOS程序提审步骤,这次我详细的截图了每一个步骤,如果你正好也需要那么跟着我的节奏一步步来肯定是没问题的. 提 ...
- 重新整理 .net core 实践篇————网关[三十六]
前言 简单整理一下网关. 正文 在介绍网关之前,介绍一下BFF,BFF全称是Backend For Frontend,它负责认证授权,服务聚合,目标是为前端提供服务. 说的通透一点,就是有没有见过这种 ...
- 二QT中使用QTimer定时器
QT中的定时器类叫QTimer(5.8以上版本才有),构造函数只需要提供父对象的指针 使用的话,需要调用QTImer的start方法,该方法以毫秒单位,每过指定毫秒时间,该类对象就会发出一个timeo ...
- GPU 高性能计算
背景 近日忽然想到,在CPU类型的服务器即使给到足够的运算资源,与GPU类型的服务器做运算来讲仍然是相差甚远,而本人有一台闲置的AMD vega8集显的电脑.想要用来做计算,来探究其与CPU运算的差别 ...
- CRM企业管理系统对于企业的价值
对于企业来说,一个完整的工作流程可以概括为三个阶段:售前.售中.售后.每个阶段都需要不同的管理.此外,客户关系管理客户关系管理系统可以帮助企业在这三个阶段进行业务管理和客户管理,帮助企业更好地运作,增 ...
- CentOS-Docker搭建Kafka(单点,含:zookeeper、kafka-manager)
Docker搭建Kafka(单点,含:zookeeper.kafka-manager) 下载相关容器 $ docker pull wurstmeister/zookeeper $ docker pul ...
- Docker:Linux离线安装docker-compose
1)首先访问 docker-compose 的 GitHub 版本发布页面 https://github.com/docker/compose/releases 2)由于服务器是 CentOS 系统, ...