FlinkSQL写入Kafka/ES/MySQL示例-JAVA
一、背景说明
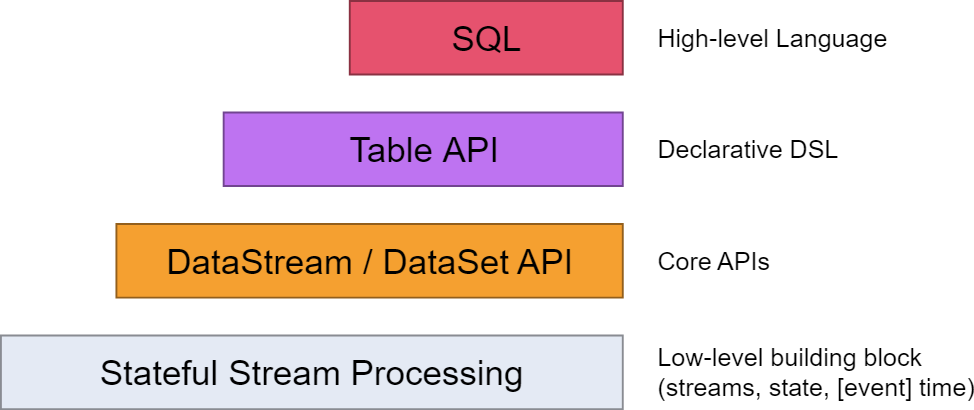
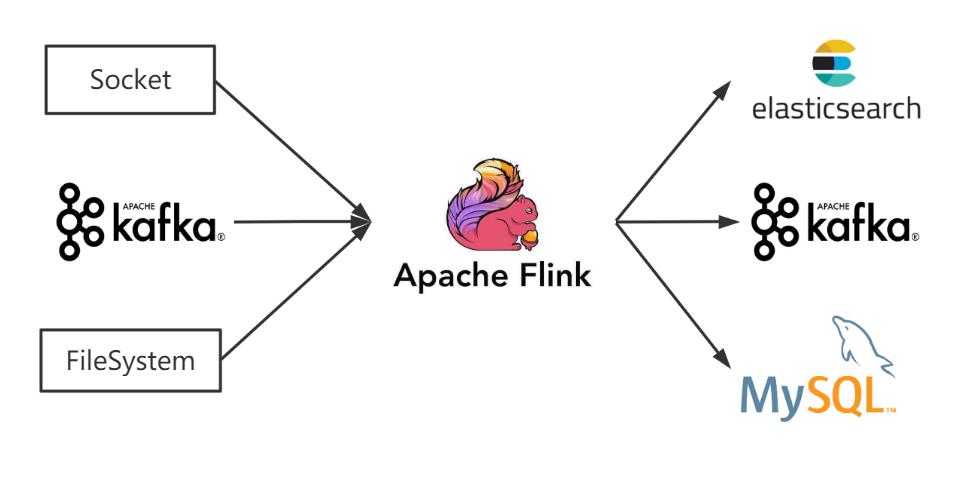
Flink的API做了4层的封装,上两层TableAPI、SQL语法相对简单便于编写,面对小需求可以快速上手解决,本文参考官网及部分线上教程编写source端、sink端代码,分别读取socket、kafka及文本作为source,并将流数据输出写入Kafka、ES及MySQL,方便后续查看使用。
二、代码部分
说明:这里使用connect及DDL两种写法,connect满足Flink1.10及以前版本使用,目前官方文档均是以DDL写法作为介绍,建议1.10以后的版本使用DDL写法操作,通用性更强。
1.读取(Source)端写法
1.1 基础环境建立,方便演示并行度为1且不设置CK
//建立Stream环境,设置并行度为1
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1);
//建立Table环境
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
1.2 读取Socket端口数据,并使用TableAPI及SQL两种方式查询
//读取服务器9999端口数据,并转换为对应JavaBean
SingleOutputStreamOperator<WaterSensor> mapDS = env.socketTextStream("hadoop102", 9999)
.map(value -> {
String[] split = value.split(",");
return new WaterSensor(split[0]
, Long.parseLong(split[1])
, Integer.parseInt(split[2]));});
//创建表:将流转换成动态表。
Table table = tableEnv.fromDataStream(mapDS);
//对动态表进行查询,TableAPI方式
Table selectResult = table.where($("id").isEqual("ws_001")).select($("id"), $("ts"), $("vc"));
//对动态表镜像查询,SQL方式-未注册表
Table selectResult = tableEnv.sqlQuery("select * from " + table);
1.3 读取文本(FileSystem)数据,并使用TableAPI进行查询
//Flink1.10写法使用connect方式,读取txt文件并建立临时表
tableEnv.connect(new FileSystem().path("input/sensor.txt"))
.withFormat(new Csv().fieldDelimiter(',').lineDelimiter("\n"))
.withSchema(new Schema().field("id", DataTypes.STRING())
.field("ts", DataTypes.BIGINT())
.field("vc",DataTypes.INT()))
.createTemporaryTable("sensor");
//转换成表对象,对表进行查询。SQL写法参考Socket段写法
Table table = tableEnv.from("sensor");
Table selectResult = table.groupBy($("id")).aggregate($("id").count().as("id_count"))select($("id"), $("id_count"));
1.4 消费Kafka数据,并使用TableAPI进行查询,分别用conncet及DDL写法
//Flink1.10写法使用connect方式,消费kafka对应主题并建立临时表
tableEnv.connect(new Kafka().version("universal")
.topic("sensor")
.startFromLatest()
.property(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092")
.property(ConsumerConfig.GROUP_ID_CONFIG,"BD"))//消费者组
.withSchema(new Schema().field("id", DataTypes.STRING())
.field("ts", DataTypes.BIGINT())
.field("vc",DataTypes.INT()))
.withFormat(new Csv())
.createTemporaryTable("sensor");
//Flink1.10以后使用DDL写法
tableEnv.executeSql("CREATE TABLE sensor (" +
" `id` STRING," +
" `ts` BIGINT," +
" `vc` INT" +
") WITH (" +
" 'connector' = 'kafka'," +
" 'topic' = 'sensor'," +
" 'properties.bootstrap.servers' = 'hadoop102:9092'," +
" 'properties.group.id' = 'BD'," +
" 'scan.startup.mode' = 'latest-offset'," +
" 'format' = 'csv'" +
")");
//转换成表对象,对表进行查询。SQL写法参考Socket段写法
Table table = tableEnv.from("sensor");
Table selectResult = table.groupBy($("id")).aggregate($("id").count().as("id_count"))
.select($("id"), $("id_count"));
2.写入(Sink)端部分写法
2.1 写入文本文件
//创建表:创建输出表,connect写法
tableEnv.connect(new FileSystem().path("out/sensor.txt"))
.withFormat(new Csv())
.withSchema(new Schema().field("id", DataTypes.STRING())
.field("ts", DataTypes.BIGINT())
.field("vc",DataTypes.INT()))
.createTemporaryTable("sensor");
//将数据写入到输出表中即实现sink写入,selectResult则是上面source侧查询出来的结果表
selectResult.executeInsert("sensor");
2.2 写入Kafka
//connect写法
tableEnv.connect(new Kafka().version("universal")
.topic("sensor")
.sinkPartitionerRoundRobin() //轮询写入
.property(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092"))
.withSchema(new Schema().field("id", DataTypes.STRING())
.field("ts", DataTypes.BIGINT())
.field("vc",DataTypes.INT()))
.withFormat(new Json())
.createTemporaryTable("sensor");
//DDL写法
tableEnv.executeSql("CREATE TABLE sensor (" +
" `id` STRING," +
" `ts` BIGINT," +
" `vc` INT" +
") WITH (" +
" 'connector' = 'kafka'," +
" 'topic' = 'sensor'," +
" 'properties.bootstrap.servers' = 'hadoop102:9092'," +
" 'format' = 'json'" +
")");
//将数据写入到输出表中即实现sink写入,selectResult则是上面source侧查询出来的结果表
selectResult.executeInsert("sensor");
2.3 写入MySQL(JDBC方式,这里手动导入了mysql-connector-java-5.1.9.jar)
//DDL
tableEnv.executeSql("CREATE TABLE sink_sensor (" +
" id STRING," +
" ts BIGINT," +
" vc INT," +
" PRIMARY KEY (id) NOT ENFORCED" +
") WITH (" +
" 'connector' = 'jdbc'," +
" 'url' = 'jdbc:mysql://hadoop102:3306/test?useSSL=false'," +
" 'table-name' = 'sink_test'," +
" 'username' = 'root'," +
" 'password' = '123456'" +
")");
//将数据写入到输出表中即实现sink写入,selectResult则是上面source侧查询出来的结果表
selectResult.executeInsert("sensor");
2.4 写入ES
//connect写法
tableEnv.connect(new Elasticsearch()
.index("sensor")
.documentType("_doc")
.version("7")
.host("localhost",9200,"http")
//设置为1,每行数据都写入是方便客户端输出展示,生产勿使用
.bulkFlushMaxActions(1))
.withSchema(new Schema()
.field("id", DataTypes.STRING())
.field("ts", DataTypes.BIGINT())
.field("vc",DataTypes.INT()))
.withFormat(new Json())
.inAppendMode()
.createTemporaryTable("sensor");
//DDL写法
tableEnv.executeSql("CREATE TABLE sensor (" +
" id STRING," +
" ts BIGINT," +
" vc INT," +
" PRIMARY KEY (id) NOT ENFORCED" +
") WITH (" +
" 'connector' = 'elasticsearch-7'," +
" 'hosts' = 'http://localhost:9200'," +
" 'index' = 'users'," +
" 'sink.bulk-flush.max-actions' = '1')";)
//将数据写入到输出表中即实现sink写入,selectResult则是上面source侧查询出来的结果表
selectResult.executeInsert("sensor");
三、补充说明
依赖部分pom.xml
<properties>
<java.version>1.8</java.version>
<maven.compiler.source>${java.version}</maven.compiler.source>
<maven.compiler.target>${java.version}</maven.compiler.target>
<flink.version>1.12.0</flink.version>
<scala.version>2.12</scala.version>
<hadoop.version>3.1.3</hadoop.version>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.8.0</version>
</dependency>
<!-- elasticsearch 的客户端 -->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.8.0</version>
</dependency>
<!-- elasticsearch 依赖 2.x 的 log4j -->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>2.8.2</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.8.2</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.9.9</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-elasticsearch7_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.16</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-csv</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-json</artifactId>
<version>${flink.version}</version>
</dependency>
</dependencies>
</project>
学习交流,有任何问题还请随时评论指出交流。
FlinkSQL写入Kafka/ES/MySQL示例-JAVA的更多相关文章
- Java读文件写入kafka
目录 Java读文件写入kafka 文件格式 pom依赖 java代码 Java读文件写入kafka 文件格式 840271 103208 0 0.0 insert 84e66588-8875-441 ...
- 大数据学习day33----spark13-----1.两种方式管理偏移量并将偏移量写入redis 2. MySQL事务的测试 3.利用MySQL事务实现数据统计的ExactlyOnce(sql语句中出现相同key时如何进行累加(此处时出现相同的单词))4 将数据写入kafka
1.两种方式管理偏移量并将偏移量写入redis (1)第一种:rdd的形式 一般是使用这种直连的方式,但其缺点是没法调用一些更加高级的api,如窗口操作.如果想更加精确的控制偏移量,就使用这种方式 代 ...
- java实时监听日志写入kafka(转)
原文链接:http://www.sjsjw.com/kf_cloud/article/020376ABA013802.asp 目的 实时监听某目录下的日志文件,如有新文件切换到新文件,并同步写入kaf ...
- java实现Kafka的消费者示例
使用java实现Kafka的消费者 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 3 ...
- java实时监听日志写入kafka(多目录)
目的 实时监听多个目录下的日志文件,如有新文件切换到新文件,并同步写入kafka,同时记录日志文件的行位置,以应对进程异常退出,能从上次的文件位置开始读取(考虑到效率,这里是每100条记一次,可调整) ...
- java实时监听日志写入kafka
目的 实时监听某目录下的日志文件,如有新文件切换到新文件,并同步写入kafka,同时记录日志文件的行位置,以应对进程异常退出,能从上次的文件位置开始读取(考虑到效率,这里是每100条记一次,可调整) ...
- Flink RichSourceFunction应用,读关系型数据(mysql)数据写入关系型数据库(mysql)
1. 写在前面 Flink被誉为第四代大数据计算引擎组件,即可以用作基于离线分布式计算,也可以应用于实时计算.Flink的核心是转化为流进行计算.Flink三个核心:Source,Transforma ...
- storm集成kafka的应用,从kafka读取,写入kafka
storm集成kafka的应用,从kafka读取,写入kafka by 小闪电 0前言 storm的主要作用是进行流式的实时计算,对于一直产生的数据流处理是非常迅速的,然而大部分数据并不是均匀的数据流 ...
- Spark(二十一)【SparkSQL读取Kudu,写入Kafka】
目录 SparkSQL读取Kudu,写出到Kafka 1. pom.xml 依赖 2.将KafkaProducer利用lazy val的方式进行包装, 创建KafkaSink 3.利用广播变量,将Ka ...
随机推荐
- JSON数据显示在jsp页面上中文乱码的解决办法
在@RequestMapping属性添加属性produces = "text/html;charset=utf-8",设置字符集为utf-8即可 代码如下: @RequestMap ...
- 浅谈自动特征构造工具Featuretools
简介 特征工程在机器学习中具有重要意义,但是通过手动创造特征是一个缓慢且艰巨的过程.Python的特征工程库featuretools可以帮助我们简化这一过程.Featuretools是执行自动化特征工 ...
- raft协议
一.Raft一致性算法 Eureka:Peer To Peer,每个节点的地位都是均等的,每个节点都可以接收写入请求,每个节点接收请求之后,进行请求打包处理,异步化延迟一点时间,将数据同步给 Eure ...
- 事后分析$\beta$
项目 内容 课程:北航-2020-春-软件工程 博客园班级博客 要求 事后分析 我们在这个课程的目标是 提升团队管理及合作能力,开发一项满意的工程项目 这个作业在哪个具体方面帮助我们实现目标 组织组员 ...
- laravel 伪静态实现
Route::get('show{id}.html',['as'=>'products.detail','uses'=>'companyController@show']) ->wh ...
- [bug] org.yaml.snakeyaml.error.YAMLException: java.nio.charset.MalformedInputException: Input length = 2
原因 SpringBoot启动加载yml配置文件出现编码格式错误 参考 https://www.pianshen.com/article/2431144034/
- [DB] Memcache
什么是Memcache Redis的前身 严格来说只能叫缓存,不支持持久化,停电后数据丢失 Strom.Spark Streaming实时计算的结果一般会保存在Redis中 JDBC是性能瓶颈 关系型 ...
- openshift 3.11 安装部署
openshift 3.11 安装部署 openshift安装部署 1 环境准备(所有节点) openshift 版本 v3.11 1.1 机器环境 ip cpu mem hostname OSsys ...
- 使用chrony安装chrony
yum install chrony -y 使用chrony安装chrony 使用root用户登录~]# yum install chrony 默认的chrony进程位置/usr/sbin/c ...
- k8s用 ConfigMap 管理配置(13)
一.ConfigMap介绍 Secret 可以为 Pod 提供密码.Token.私钥等敏感数据:对于一些非敏感数据,比如应用的配置信息,则可以用 ConfigMap ConfigMap 的创建和使用方 ...