Adversarial Examples Are Not Bugs, They Are Features
@article{ilyas2019adversarial,
title={Adversarial Examples Are Not Bugs, They Are Features},
author={Ilyas, Andrew and Santurkar, Shibani and Tsipras, Dimitris and Engstrom, Logan and Tran, Brandon and Madry, Aleksander},
pages={125--136},
year={2019}}
概
作者认为, 标准训练方法, 由于既能学到稳定的特征和不稳定的特征, 而导致模型不稳定. 作者通过将数据集分解成稳定和非稳定数据来验证其猜想, 并利用高斯分布作为一特例举例.
主要内容
本文从二分类模型入手.
符号说明及部分定义
\((x,y) \in \mathcal{X} \times \{\pm 1\}\): 样本和标签;
\(C:\mathcal{X} \rightarrow \{\pm 1\}\): 分类器;
\(f:\mathcal{X} \rightarrow \mathbb{R}\) : 特征;
\(\mathcal{F}=\{f\}\): 特征集合;
注: 假设\(\mathbb{E}_{(x,y) \sim \mathcal{D}}[f(x)]=0\), \(\mathbb{E}_{(x,y) \sim \mathcal{D}}[f(x)^2]=1\).
注: 在深度学习中, \(C\)可以理解为
\]
\(\rho\)可用特征
满足
\mathbb{E}_{(x,y) \sim \mathcal{D}}[y \cdot f(x)] \ge \rho >0,
\]
并记\(\rho_{\mathcal{D}}(f)\)为最大的\(\rho\).
\(\gamma\)稳定可用特征
若\(f\) \(\rho\)可用, 且对于给定的摄动集合\(\Delta\)
\mathbb{E}_{(x, y) \sim \mathcal{D}} [\inf_{\delta \in \Delta(x)} y \cdot f(x+ \delta)] \ge \gamma > 0,
\]
则\(f\) 为\(\gamma\)稳定可用特征.
可用不稳定特征
即对于\(f\), \(\rho_{\mathcal{D}}(f) >0\), 但是不存在\(\gamma >0\)使得(2)式满足.
标准(standard)训练
即最小化期望损失(在实际中为经验风险):
\mathbb{E}_{(x,y) \sim \mathcal{D}} [\mathcal{L}_{\theta} (x, y)],
\]
\(\mathcal{L}_{\theta}\)的取法多样, 比如
\]
稳定(robust)训练
\mathbb{E}_{(x, y) \sim \mathcal{D}} [\max_{\delta \in \Delta(x)} \mathcal{L}_{\theta} (x+\delta, y)].
\]
分离出稳定数据
何为稳定数据? 即在此数据上, 利用标准的训练方式训练得到的模型能够在一定程度上免疫攻击. 如果能从普通的数据中分离出稳定数据和不稳定数据, 说明上面定义的稳定和非稳特征的存在性.
首先假设\(C\)是一个稳定模型(可通过PGD训练近似生成), 则\(\hat{D}_{R}\)应当满足
\mathbb{E}_{(x, y) \sim \hat{D}_{R}}[f(x) \cdot y] =
\left \{
\begin{array}{ll}
\mathbb{E}_{(x, y) \sim D}[f(x) \cdot y] & if \: f \in F_C, \\
0 & otherwise.
\end{array} \right.
\]
为了满足第一条, 需要
\min_{x_r} \quad \|g(x_r) - g(x)\|_2,
\]
其中\(g\)为将\(x\)映射到表示层(representation layer)的映射?
为了满足第二条, 在选择\(x_r\)的初始值的时候, 从\(\mathcal{D}\)中随机采样\(x'\), 以保证\(x'\)和\(y\)没有关系, 则\(\mathbb{E}_{(x, y) \sim D}[f(x') \cdot y] = \mathbb{E}_{(x, y) \sim D}[f(x')] \cdot \mathbb{E}_{(x, y) \sim D}[y] = 0\).

分离出不稳定数据
分离出不稳定数据所需要的是标准的模型\(C\), 且
x_{adv} = \arg \min_{\|x'-x\| \le \epsilon} L_C(x', t),
\]
其中\(L_C\)是认为给定的损失函数(比如:交叉熵), 而\(t\)是通过某种方式给定的标签, 且\(C(x) = y\), \(C(x')=t\).
既然摄动很小, 且\(x_{adv}\)的标签为\(t\), 所以此时\(F_C\)中既有稳定特征, 又有不稳定特征.
\(t\)随机选取
此时稳定性特征和\(t\)不相关, 故其可用度应当为0, 而不稳定特征可用度大于0, 故
\mathbb{E}_{(x, y) \sim \hat{D}_{rand}}[f(x) \cdot y]
\left \{
\begin{array}{ll}
.> 0 & if \: f \: non-robustly \: useful, \\
\approx 0 & otherwise.
\end{array} \right.
\]
\(t\)选取依赖于\(y\)
\mathbb{E}_{(x, y) \sim \hat{D}_{det}}[f(x) \cdot y] =
\left \{
\begin{array}{ll}
.> 0 & if \: f \: non-robustly \: useful \\
< 0 & if \: f\: robustly \: useful \\
\in \mathbb{R} & otherwise.
\end{array} \right.
\]

比较重要的实验
1
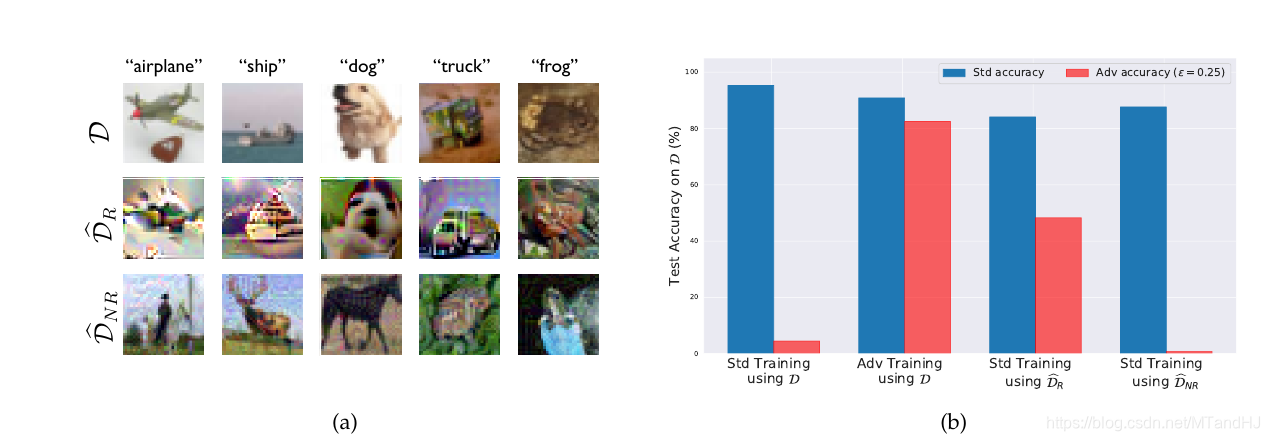
上面左图从上到下分别是标准数据, 稳定数据和不稳定数据, 右图进行了四组不同的实验:
- 在标准数据上标准训练并对其攻击
- 在标准数据上稳定训练并对其攻击
- 在稳定数据上标准训练并对其攻击
- 在不稳定数据上标准训练并对其攻击
不难发现, 在稳定数据上标准训练能够一定程度上免疫攻击, 而在不稳定数据上标准训练, 能够逼近在标准数据上标准训练的结果, 而其对攻击的免疫程度也正如我们所想的一塌糊涂.
这些实验可以说明, 稳定特征和不稳定特征是存在的, 标准训练由于最大限度地追求准确度, 所以其对二类特征一视同仁, 全盘接受, 这导致了不稳定.
迁移性
adversarial attacks的一个很明显的特征便是迁移性, 稳定特征和不稳定特征能够解释这一点, 既然数据相同, 不同结构的网络会从中提取出类似的不稳定特征.
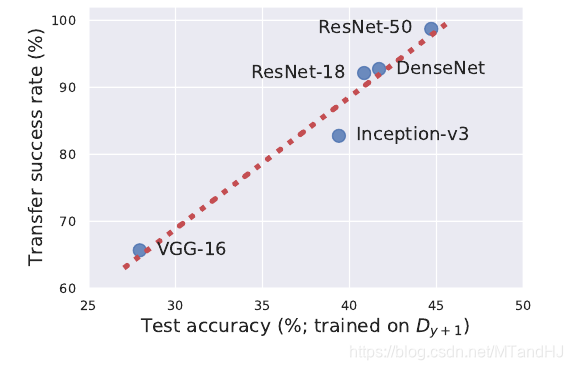
利用从ResNet-50中提取的不稳定数据, 提供给别的模型训练, 可以验证迁移性.
理论分析
作者通过一个正态分布的例子来告诉我们稳定特征和不稳定特征的存在和作用.
注: 下面涉及到的\(\Sigma, \Sigma_*\)均为对角阵.
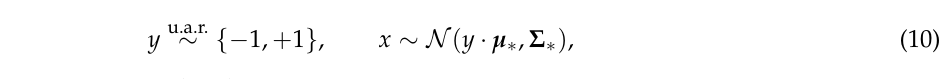
标准训练的目标是通过极大似然估计\(\Theta=(\mu, \Sigma)\),
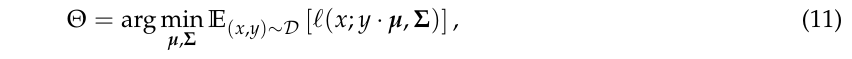
其中\(\ell\)为密度函数的\(-\log\).
于是,
\]
注: 无特别约束(11)的最优解即位\(\mu_*, \Sigma_*\).
稳定训练的目标是
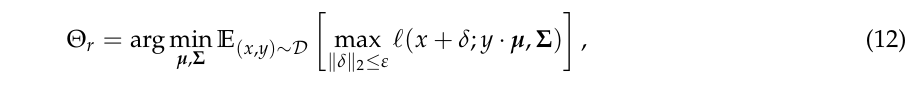
则有以下结论
定理1

注: \(\mathcal{L}(\Theta)=\mathbb{E}_{(x, y) \sim \mathcal{D}}[\ell(x, y,\mu, \Sigma)]\), \(\mathcal{L}_{adv}(\Theta)\)的定义是类似的.
定理2
注意, 此时考虑的问题与上面的不同(定理3同定理2), 为
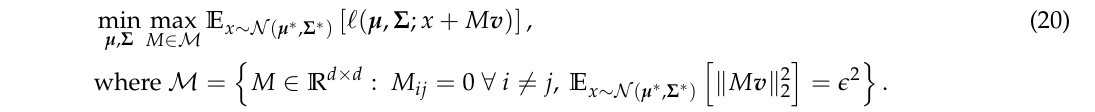

定理3

定理的证明, 这里不贴了, 其中有一个引理的证明很有趣.
Adversarial Examples Are Not Bugs, They Are Features的更多相关文章
- Adversarial Examples for Semantic Segmentation and Object Detection 阅读笔记
Adversarial Examples for Semantic Segmentation and Object Detection (语义分割和目标检测中的对抗样本) 作者:Cihang Xie, ...
- 文本adversarial examples
对文本对抗性样本的研究极少,近期论文归纳如下: 文本对抗三个难点: text data是离散数据,multimedia data是连续数据,样本空间不一样: 对text data的改动可能导致数据不合 ...
- 论文阅读 | Generating Fluent Adversarial Examples for Natural Languages
Generating Fluent Adversarial Examples for Natural Languages ACL 2019 为自然语言生成流畅的对抗样本 摘要 有效地构建自然语言处 ...
- 《Explaining and harnessing adversarial examples》 论文学习报告
<Explaining and harnessing adversarial examples> 论文学习报告 组员:裴建新 赖妍菱 周子玉 2020-03-27 1 背景 Sz ...
- Limitations of the Lipschitz constant as a defense against adversarial examples
目录 概 主要内容 Huster T., Chiang C. J. and Chadha R. Limitations of the lipschitz constant as a defense a ...
- Uncovering the Limits of Adversarial Training against Norm-Bounded Adversarial Examples
Uncovering the Limits of Adversarial Training against Norm-Bounded Adversarial Examples 目录 概 主要内容 实验 ...
- Certified Robustness to Adversarial Examples with Differential Privacy
目录 概 主要内容 Differential Privacy insensitivity Lemma1 Proposition1 如何令网络为-DP in practice Lecuyer M, At ...
- Generating Adversarial Examples with Adversarial Networks
目录 概 主要内容 black-box 拓展 Xiao C, Li B, Zhu J, et al. Generating Adversarial Examples with Adversarial ...
- Obfuscated Gradients Give a False Sense of Security: Circumventing Defenses to Adversarial Examples
目录 概 主要内容 Obfuscated Gradients BPDA 特例 一般情形 EOT Reparameterization 具体的案例 Thermometer encoding Input ...
随机推荐
- 日常Java 2021/11/13
Java Applet基础 Applet是一种Java程序.它一般运行在支持Java的Web浏览器内.因为它有完整的Java API支持,所以Applet是一个全功能的Java应用程序.如下所示是独立 ...
- 日常Java 2021/11/3
java网络编程 网络编程是指编写运行在多个设备(计算机)的程序,这些设备都通过网络连接起来.java.net包中J2SE的APl包含有类和接口,它们提供低层次的通信细节.你可以直接使用这些类和接口, ...
- A Child's History of England.26
CHAPTER 9 ENGLAND UNDER WILLIAM THE SECOND, CALLED RUFUS William the Red, in breathless haste, secur ...
- Spark的shuffle和MapReduce的shuffle对比
目录 MapperReduce的shuffle Spark的shuffle 总结 MapperReduce的shuffle shuffle阶段划分 Map阶段和Reduce阶段 任务 MapTask和 ...
- 安全相关,关于https
什么是 HTTPS HTTPS(全称:Hyper Text Transfer Protocol over Secure Socket Layer),是以安全为目标的HTTP通道,简单讲是HTTP的安全 ...
- Spring Boot 和 Spring Cloud Feign调用服务及传递参数踩坑记录
背景 :在Spring Cloud Netflix栈中,各个微服务都是以HTTP接口的形式暴露自身服务的,因此在调用远程服务时就必须使用HTTP客户端.我们可以使用JDK原生的URLConnectio ...
- 如何用CodeBlocks调试?
一.简介 这篇文章我主要会介绍CodeBlocks的调试功能,并简单讲述如何使用它. 二.前言 大家好,最近和小伙伴们讨论修改程序的时候,我突然想到,授人以鱼不如授人以渔(指调试),于是这篇文章应运而 ...
- apt和apt-get的区别
目录 一.简介 二.apt vs apt-get 为什么apt首先被引入? apt和apt-get之间的区别 apt和apt-get命令之间的区别 我应该使用apt还是apt-get? 三.结论 一. ...
- thinkphp引入PHPExcel类---thinkPHP类库扩展-----引入没有采用命名空间的类库
最近项目中遇到引入PHPExcel第三方类库 但是下载的phpExcel类没有命名空间,而且所有接口文件的命名都是以.php结尾 而不是tp中的.class.php 解决办法很简单:在引入没有采用命 ...
- Python学习问题汇总
个人Python学习过程中遇到问题汇总,不断更新. 一.读取文件是报FileNotFoundError: 前期了解:python是在当前执行文件所在的目录中查找文件. 解决方法: 1.查看输入文件名是 ...