CHARACTERIZING ADVERSARIAL SUBSPACES USING LOCAL INTRINSIC DIMENSIONALITY
@article{ma2018characterizing,
title={Characterizing Adversarial Subspaces Using Local Intrinsic Dimensionality},
author={Ma, Xingjun and Li, Bo and Wang, Yisen and Erfani, Sarah M and Wijewickrema, Sudanthi and Houle, Michael E and Schoenebeck, Grant and Song, Dawn and Bailey, James},
journal={arXiv: Learning},
year={2018}}
概
本文介绍了一种local intrinsic dimensionality(LID)的指标用以揭示普通样本和对抗样本的本质区别, 这个指标可以用用来进行防御(即在样本进来的时候, 提前预判其是否是对抗样本).
主要内容
已有的一些用来区分普通样本和对抗样本的方法, 诸如KD(核密度估计) 和 BU(贝叶斯不确定度, 这个不是很了解), 但是其效果不明显, 本文提出的LID指标能够在各方面胜过他们.
比如在下图中, KM(k均值距离: 取样本\(x\)到最近的k个样本的距离的平均), 以及核密度估计(KD), 在普通样本和对抗样本上的指标是一致的, 此时无法判断, 而本文的LID的方法却能够判断(LID越大越偏离普通样本).

LID
由一个点为中心, 向外以超距体的方式发散, 其体积\(V\)与边长\(r\)的关系可知
\]
其中\(m\)为维度.
于是有人就想出把这种思想推广到一般的数据(数据的分布可能是一个低维的流形)
定义(LID): 给定样本\(x \in \mathcal{X}\), 令\(R >0\)表示\(x\)到其它样本的距离的随机变量, 并用\(F(r)\)表示概率\(P(R\le r)\), 且假设其关于\(r>0\)连续可微, 则在\(x\)点的距离为\(r\)的LID定义为
\mathrm{LID}_F(r) := \lim_{\epsilon \rightarrow 0} \frac{\log (F((1+\epsilon)\cdot r) / F(r))}{\log (1+\epsilon)}=\frac{r\cdot F'(r)}{F(r)},
\]
若极限存在.
注: 最后一个等式成立, 只需中间式子上下同除以\(\epsilon\)再分别取极限即可(既然二者的极限都存在).
最后,
\mathrm{LID}_F := \lim_{r \rightarrow 0} \mathrm{LID}_F(r).
\]
此即位我们最后要的LID(\(r \rightarrow 0\)是因为我们关注的是局部信息).
LID估计
\widehat{\mathrm{LID}}(x)= - (\frac{1}{k} \sum_{i=1}^k \log \frac{r_i(x)}{r_k(x)})^{-1}.
\]
算法
作者为了利用LID区分对抗样本, 训练了一个分类器. 在预先训练好的网络\(H\)上, 对每一个样本, 第i层的输出为\(H^i(x)\), 对每一层的输出, 我们都计算其LID(这一步会用到别的训练数据)并保存下来. 利用这些提取出来的特征(LID), 训练二分类器(作者采用逻辑斯蒂回归).

实验
1
作者首先分析了, 普通样本(normal), 噪声样本(noisy), 对抗样本(adv)的LID指标, 可以发现,LID对对抗样本很敏感, 下面右图分析了在不同层中提取出来的LID值用于区分对抗样本的成功率.

2
比较了不同方法 KD, BU, KD+BU, LID在不同数据下, 对利用不同攻击方法生成的对抗样本进行区分的效果(途中的指标为AUC, AUC指标越大越好)

3
作者在FGM上计算LID并训练分类器, 再用别的方法生成对抗样本, 再测试效果.
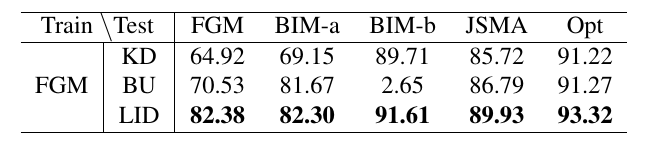
4
作者为了探究每一个batch的大小, 以及超参数\(k\)的影响, 做了实验, 显然batch size大一点比较好.

5
作者最小化下式生成对抗样本,
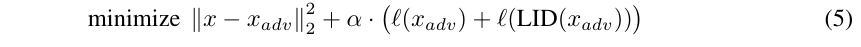
结果这些样本不能够欺骗过LID.
注: 已经别的文章指出, 其成功的原因在于破坏了梯度, 更改一下损失函数就能攻破.
CHARACTERIZING ADVERSARIAL SUBSPACES USING LOCAL INTRINSIC DIMENSIONALITY的更多相关文章
- Adversarial Detection methods
目录 Kernel Density (KD) Local Intrinsic Dimensionality (LID) Gaussian Discriminant Analysis (GDA) Gau ...
- KDD2015,Accepted Papers
Accepted Papers by Session Research Session RT01: Social and Graphs 1Tuesday 10:20 am–12:00 pm | Lev ...
- 壁虎书8 Dimensionality Reduction
many Machine Learning problems involve thousands or even millions of features for each training inst ...
- 降维工具箱drtool
工具箱下载:http://leelab.googlecode.com/svn/trunk/apps/drtoolbox/ ——————————————————————————————————————— ...
- matlab 降维工具 转载【https://blog.csdn.net/tarim/article/details/51253536】
降维工具箱drtool 这个工具箱的主页如下,现在的最新版本是2013.3.21更新,版本v0.8.1b http://homepage.tudelft.nl/19j49/Matlab_Toolb ...
- t-SNE完整笔记
http://www.datakit.cn/blog/2017/02/05/t_sne_full.html t-SNE(t-distributed stochastic neighbor embedd ...
- Context Encoder论文及代码解读
经过秋招和毕业论文的折磨,提交完论文終稿的那一刻总算觉得有多余的时间来搞自己的事情. 研究论文做的是图像修复相关,这里对基于深度学习的图像修复方面的论文和代码进行整理,也算是研究生方向有一个比较好的结 ...
- 100 Most Popular Machine Learning Video Talks
100 Most Popular Machine Learning Video Talks 26971 views, 1:00:45, Gaussian Process Basics, David ...
- 理解 t-SNE (Python)
t-SNE(t-distribution Stochastic Neighbor Embedding)是目前最为流行的高维数据的降维算法. t-SNE 成立的前提基于这样的一个假设:我们现实世界观察到 ...
随机推荐
- day02 MySQL基本操作
day02 MySQL基本操作 昨日内容回顾 数据库演变史 1.纯文件阶段 2.目录规范 3.单机游戏 4.联网游戏 # 数据库就是一款帮助我们管理数据的程序 软件开发架构及数据库本质 cs架构与bs ...
- hadoop基本命令(转)
在这篇文章中,我们默认认为Hadoop环境已经由运维人员配置好直接可以使用. 假设Hadoop的安装目录HADOOP_HOME为/home/admin/hadoop. 启动与关闭 启动HADOOP 进 ...
- spring整合mybatis和springmvc的配置概图
- 【C/C++】例题5-4 反片语/算法竞赛入门经典/C++与STL入门/映射:map
本题是映射:map的例题. map:键值对. [题目] 输入一些单词,找出所有满足如下条件的单词:该单词不能通过字母重排,得到输入文本中的另外一个单词. 在判断是否满足条件时,字母不分大小写,但在输出 ...
- Solon 1.6.6 发布,细节打磨
Solon 已有120个生态扩展插件,此次更新主要为细节打磨: 增加 @Inject("ds1") BeanWrap bw 模式注入 @Configuration public c ...
- ES6解构赋值的简单使用
相较于常规的赋值方式,解构赋值最主要的是'解构'两个字,在赋值的过程中要清晰的知道等号右边的结构. 先简单地看一下原来的赋值方式. var a=[1,2] 分析一下这句代码的几个点: (1)变量申明和 ...
- Firebug: Net Panel 使用详解
Introduction to Firebug: Net Panel Since there is not much user documentation related to Firebug fea ...
- Spring中基于注解方式管理bean
操作步骤 第一步:导入相关jar包 spring IoC的基本包 Spring支持注解的Jar包 第二步:创建Spring配置文件,ApplicationContext.xml 引入约束和开启注解扫描 ...
- PLSQL Developer 13安装教程
1:双击安装包进行安装.点击"next".2:点击"w accept the termis..."同意条款,并点击"next",进行下一步. ...
- Spring5 AOP编程:关于org.springframework.beans.factory.BeanNotOfRequiredTypeException报错
Spring5 AOP编程:关于org.springframework.beans.factory.BeanNotOfRequiredTypeException报错 先上错误详细信息: org.spr ...