Spark(四)【RDD编程算子】
测试准备
pom文件
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.2.0</version>
</dependency>
</dependencies>
<build>
<plugins>
<!-- 该插件用于将Scala代码编译成class文件 -->
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
<executions>
<execution>
<!-- 声明绑定到maven的compile阶段 -->
<goals>
<goal>compile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
测试类
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.{FileSystem, Path}
import org.apache.spark.{SparkConf, SparkContext}
import org.junit.{After, Before, Test}
/**
* 初始化SparkContext
*/
@Before
def innit {
val conf = new SparkConf().setAppName("RDDTest").setMaster("local[*]")
sc = new SparkContext(conf)
//删除上一次产生的output文件,不然报错
val fs = FileSystem.get(new Configuration())
val path = new Path("output")
if(fs.exists(path)){
fs.delete(path)
}
}
/**
* 关闭SparkContext
*/
def close()= {
sc.stop
}
一.Value类型转换算子
map(func)
作用:返回一个新的RDD,该RDD由每一个输入元素经过func函数转换后组成
函数签名
def map[U: ClassTag](f: T => U): RDD[U] = withScope {
// 检查函数中是否有闭包,如果有闭包确保闭包变量可以被序列化,才能发送给Task,否则报错
val cleanF = sc.clean(f)
// iter.map : 调用的就是scala集合中的map方法 集合(分区)中的每个元素,都调用一次函数!
new MapPartitionsRDD[U, T](this, (_, _, iter) => iter.map(cleanF))
}
特点: ①不会改变RDD的分区数
②对每个分区中的元素调用函数进行计算,计算的结果还在原先分区
练习:从服务器日志数据apache.log中获取用户请求URL资源路径
/**
* map
* 数据格式:"83.149.9.216 - - 17/05/2015:10:05:07 +0000 GET /presentations/logstash-monitorama-2013/plugin/notes/notes.js"
*/
@Test
def testMap {
val rdd = sc.textFile("input/apache.log").map(_.split(" ")(6))
rdd.saveAsTextFile("output")
}
mapPartitions(func)
作用:类似于map,但独立地在RDD的每一个分片上运行,因此在类型为T的RDD上运行时,func的函数类型必须是Iterator[T] => Iterator[U]。假设有N个元素,有M个分区,那么map的函数的将被调用N次,而mapPartitions被调用M次,一个函数一次处理所有分区。
函数签名
def mapPartitions[U: ClassTag](
f: Iterator[T] => Iterator[U],
preservesPartitioning: Boolean = false): RDD[U] = withScope {
val cleanedF = sc.clean(f)
// cleanedF(iter) 一个分区调用一次函数,批处理
new MapPartitionsRDD(
this,
(_: TaskContext, _: Int, iter: Iterator[T]) => cleanedF(iter),
preservesPartitioning)
}
练习:获取每个数据分区的最大值
/**
* mapPartitions
*/
@Test
def testMapPartition {
val rdd = sc.makeRDD(List(1,2,3,4,5,6,7,8),2).mapPartitions(iter => {
List(iter.max).toIterator
})
rdd.saveAsTextFile("output")
}
mapPartitions和map的区别
map():每次处理一条数据。
mapPartition():每次处理一个分区的数据,这个分区的数据处理完后,原RDD中分区的数据才能释放,可能导致OOM。
使用指导:当内存空间较大的时候建议使用mapPartition(),以提高处理效率。
mapPartitionsWithIndex(func)
作用:类似于mapPartitions,但func带有一个整数参数表示分片的索引值,因此在类型为T的RDD上运行时,func的函数类型必须是(Int, Interator[T]) => Iterator[U];
函数签名
def mapPartitionsWithIndex[U: ClassTag](
f: (Int, Iterator[T]) => Iterator[U],
preservesPartitioning: Boolean = false): RDD[U] = withScope {
val cleanedF = sc.clean(f)
new MapPartitionsRDD(
this,
// cleanedF(index, iter) : 批处理,提供了分区的索引
(_: TaskContext, index: Int, iter: Iterator[T]) => cleanedF(index, iter),
preservesPartitioning)
}
练习:获取第二个数据分区的数据
/**
* mapPartitionsWithIndex
*/
@Test
def testMapPartitionIndex {
val rdd = sc.makeRDD(List(1, 2, 3, 4, 5, 6, 7), 3).mapPartitionsWithIndex {
case (2, iter) => iter
case _ => Nil.toIterator
}
println(rdd.collect().mkString(","))
}
flatMap(func)
作用:类似于map,但是每一个输入元素可以被映射为0或多个输出元素(所以func应该返回一个序列,而不是单一元素)
练习:将List(List(1,2),3,List(4,5))进行扁平化操作
/**
* flatMap
*/
@Test
def testflatMap {
val rdd= sc.makeRDD(List(List(1, 2), 3, List(4, 5)))
val rdd1 =rdd.flatMap{
case x:Int => List(x)
case list: List[_] =>list
}
rdd1.collect().foreach(println)
}
glom
作用:将每一个分区形成一个数组,形成新的RDD类型时RDD[Array[T]]
函数签名
def glom(): RDD[Array[T]] = withScope {
new MapPartitionsRDD[Array[T], T](this, (_, _, iter) => Iterator(iter.toArray))
}
练习:计算所有分区最大值求和(分区内取最大值,分区间最大值求和)
/**
* glom
*/
@Test
def testglom {
val rdd = sc.makeRDD(List(1, 2, 3, 4, 5, 6, 7), 3).glom()
rdd.collect().foreach(x=>println(x.toBuffer))
println(rdd.map(_.max).sum())
}
groupBy(func)
作用:分组,按照传入函数的返回值进行分组。将相同的key对应的值放入一个迭代器。
数据根据指定的规则进行分组, 分区默认不变,也可以指定分组后的分区数
一个组的数据在一个分区中,但是并不是说一个分区中只有一个组
函数签名
// 根据f函数的返回值作为key,对T类型进行分组
def groupBy[K](f: T => K)(implicit kt: ClassTag[K]): RDD[(K, Iterable[T])] = withScope {
groupBy[K](f, defaultPartitioner(this))
}
filter(func)
作用:过滤。返回一个新的RDD,该RDD由经过func函数计算后返回值为true数据保留。
注意:当数据进行筛选过滤后,分区不变,但是分区内的数据可能不均衡,生产环境下,可能会出现数据倾斜。可以通过coalesce改变分区。
sample(withReplacement, fraction, seed):抽样
作用:以指定的随机种子随机抽样出数量为fraction的数据,withReplacement表示是抽出的数据是否放回,true为有放回的抽样,false为无放回的抽样,seed用于指定随机数生成器种子。
val dataRDD = sparkContext.makeRDD(List(
1,2,3,4
),1)
// 抽取数据不放回(伯努利算法)
// 伯努利算法:又叫0、1分布。例如扔硬币,要么正面,要么反面。
// 具体实现:根据种子和随机算法算出一个数和第二个参数设置几率比较,小于第二个参数要,大于不要
// 第一个参数:抽取的数据是否放回,false:不放回
// 第二个参数:抽取的几率,范围在[0,1]之间,0:全不取;1:全取;
// 第三个参数:随机数种子
val dataRDD1 = dataRDD.sample(false, 0.5)
// 抽取数据放回(泊松算法)
// 第一个参数:抽取的数据是否放回,true:放回;false:不放回
// 第二个参数:重复数据的几率,范围大于等于0.表示每一个元素被期望抽取到的次数
// 第三个参数:随机数种子
val dataRDD2 = dataRDD.sample(true, 2)
distinct([numTasks]))去重
作用:对源RDD进行去重后返回一个新的RDD。默认情况下,只有8个并行任务来操作,但是可以传入一个可选的numTasks参数改变它。
去重,去重后会有shuffle! 会对去重后的数据重新分区!
默认使用HashPartitoner对去重后的数据进行分区!
map(x => (x, null)).reduceByKey((x, _) => x, numPartitions).map(_._1)
coalesce(numPartitions)重分区
Coalesce的作用是将当前RDD的数据重新分区到指定分区数的新RDD中。
①使用Coalesce从父RDD的多个分区 核减(合并) 到 少的分区,不会产生shuffle
②使用Coalesce 从少的分区 合并到多的分区,指定shuffle才会增加分区,否则分区数不变也不会shuffle。
③默认,如果要合并的分区比当前的分区数大,还会采用当前的分区数替换要合并的分区数
可以传入shuffle=true,完成从 少的分区合并到大的分区。
将会产生shuffle。默认使用HashPatitioner将数据重新分区!
repartition(numPartitions)重分区
repartition用于增加分区,本质调用了可以shuffle的coalesce!
使用场景:减少分区使用coalesce ,增加分区使用repartition
sortBy(func,[ascending], [numTasks])排序
作用;使用func先对数据进行处理,按照处理后的数据比较结果排序,默认为正序。
顶层调用了sortByKey,有shuffle
pipe 调用脚本
Shell脚本
Shell脚本
#!/bin/sh
echo "AA"
while read LINE; do
echo ">>>"${LINE}
done
(2)创建一个只有一个分区的RDD
scala> val rdd = sc.parallelize(List("hi","Hello","how","are","you"),1)
rdd: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[50] at parallelize at <console>:24
(3)将脚本作用该RDD并打印
scala> rdd.pipe("/opt/module/spark/pipe.sh").collect()
res18: Array[String] = Array(AA, >>>hi, >>>Hello, >>>how, >>>are, >>>you)
(4)创建一个有两个分区的RDD
scala> val rdd = sc.parallelize(List("hi","Hello","how","are","you"),2)
rdd: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[52] at parallelize at <console>:24
(5)将脚本作用该RDD并打印
scala> rdd.pipe("/opt/module/spark/pipe.sh").collect()
res19: Array[String] = Array(AA, >>>hi, >>>Hello, AA, >>>how, >>>are, >>>you)
二.双Value类型转换算子
就是两个单值RDD之间的操作
intersect 交集
结果分区数=上游RDD最大的分区数
有shuffle,取上游最大的分区数的RDD的分区器,,默认使用HashPartitioner
两个RDD类型需要一致
union 并集
结果分区数=上游所有RDD的分区数之和
没有shuffle,就是简单的合并。要想实现数学意义的并集,需要去重
两个RDD类型需要一致
substract 差集
结果分区数=调用substract算子的RDD的分区数
有shuffle
两个RDD类型需要一致
cartesian 笛卡尔积
结果分区数=上游RDD的分区数之乘积
没有shuffle
zip 拉链
两个RDD的分区数和每个分区内的元素数需要一致,不然抛异常。
两个RDD数据类型可以不同。
val rdd = sc.makeRDD(List(1, 2, 3, 4, 5, 6, 7), 4)
val rdd1 = sc.makeRDD(List(1, 2, 3, 4, 5, 6, 7), 4)
rdd.zip(rdd1).saveAsTextFile("output")
三.Key-Value类型转换算子
partitionBy(自定义分区)
使用HashPartitioern
val rdd = sc.makeRDD(List(("a", 1), ("b", 2), ("a", 1), ("a", 4), ("c", 1), ("b", 5)),3)
rdd.partitionBy(new HashPartitioner(3)).saveAsTextFile("output")
Spark默认使用的就是HashPartitioner如果重分区的分区器和当前RDD的分区器一样, 不进行任何的处理, 不会再次重分区。如下
hashrdd的分区器为HashPartition,result使用HashPartition分区,不会进行处理,不会报错。
val rdd = sc.makeRDD(List(("a", 1), ("b", 2), ("a", 1), ("a", 4), ("c", 1), ("b", 5)),3)
val hashrdd = rdd.partitionBy(new HashPartitioner(3))
val result = rdd.partitionBy(new HashPartitioner(4))
使用RangePartitioner,一般sorrBy中使用的是这个分区器
自定义分区器
需求:有以下数据,希望年龄相同的进入同一个区。
User("tom", 12), User("kobe", 12), User("mick", 22), User("jack", 23)
import org.apache.spark.{Partitioner, SparkConf, SparkContext}
/**
* @description: TODO
* @author: HaoWu
* @create: 2020年08月03日
*/
object MyPartitionerTest {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("RDDTest").setMaster("local[*]")
val sc = new SparkContext(conf)
val list = List(User("tom", 12), User("kobe", 12), User("mick", 22), User("jack", 23))
val result = sc.makeRDD(list).map {
case User(name, age) => (age, name)
}.partitionBy(new MyPartitioner(3))
result.saveAsTextFile("output")
}
}
/**
* User样例类
*/
case class User(name: String, age: Int)
/**
* 自定义分区器
*/
class MyPartitioner(num: Int) extends Partitioner {
//设置分区数
override def numPartitions: Int = num
//分区规则
override def getPartition(key: Any): Int = {
//判断是否为Int类型
if (!key.isInstanceOf[Int]) {
0
} else {
//Hash分区具有聚类的作用,相同age的会被分如同一个区
key.asInstanceOf[Int] % numPartitions
}
}
}
groupByKey
作用:groupByKey也是对每个key进行操作,但只生成一个sequence。
函数签名
def groupByKey(): RDD[(K, Iterable[V])] = self.withScope {
groupByKey(defaultPartitioner(self))
}
示例
val rdd = sc.makeRDD(List((1,2),(2,4),(3,2),(1,1),(2,2),(3,1)), 2)
val result = rdd.groupByKey()
//result结果
//{(1,Array(2,1)), (2,Array(4,2)), (3,Array(2,1))}
分组的结果
mapValues
针对于(K,V)形式的类型只对V进行操作。返回新的K-V类型的RDD
场景:求TOP3 {(省份1,List(12,21,12,23,1221)), (省份2,List(12,21,12,23,1221))....}
这种groupBy后的结果可以采用mapValues对Value取TOP3.
示例
//求TOP1
val rdd2 = sc.makeRDD(List(("a", 88), ("b", 95), ("a", 91), ("b", 93), ("a", 95), ("b", 98))
val rddg: RDD[(String, Iterable[Int])] = rdd2.groupByKey()
val result10 = rddg.mapValues(iter => {
val i =iter.toList
i.sortBy(x=>x).reverse.take(1)
})
result10.coalesce(1).saveAsTextFile("output")
reduceByKey(func, [numTasks])
产生shuffle,先区内聚合=>分区间聚合()
结果RDD默认是Hash分区器
函数签名
def reduceByKey(func: (V, V) => V): RDD[(K, V)] = self.withScope {
reduceByKey(defaultPartitioner(self), func)
}
示例:
val rdd = sc.makeRDD(List((1,2),(2,4),(3,2),(1,1),(2,2),(3,1)), 2)
val result = rdd.reduceByKey(_+_)
//result结果
//(1,3),(2,6),(3,3)
注意:reduceByKey算子和groupByKey在实现相同的业务功能时,reduceByKey存在预聚和(combiner)功能,所以性能比较高,推荐使用。前提是不影响业务逻辑,比如求平均值就不能区内求平均值
aggregateByKey
参数:(zeroValue:U,[partitioner: Partitioner]) (seqOp: (U, V) => U,combOp: (U, U) => U)
作用:在kv对的RDD中,,按key将value进行分组合并,合并时,将每个value和初始值作为seq函数的参数,进行计算,返回的结果作为一个新的kv对,然后再将结果按照key进行合并,最后将每个分组的value传递给combine函数进行计算(先将前两个value进行计算,将返回结果和下一个value传给combine函数,以此类推),将key与计算结果作为一个新的kv对输出。
参数描述:
(1)zeroValue:给每一个分区中的每一个key一个初始值;
(2)seqOp:函数用于在每一个分区中用初始值逐步迭代value;
(3)combOp:函数用于合并每个分区中的结果。
将数据根据不同的规则进行分区内计算和分区间计算
可以设置输出分区数,和自定义分区器
函数签名
//这是个柯理化函数。zeroValue:传入的初始值,
//(U,V)=>U:分区内计算,U就是zeroVlaue的类型,对区内每个相同key的Value就进行操作,然后再重新赋值给zeroValue
//(U,U)=>U:分区间计算,分区间相同key的value进行操作。
def aggregateByKey[U: ClassTag](zeroValue: U)(seqOp: (U, V) => U,
combOp: (U, U) => U): RDD[(K, U)] = self.withScope {
aggregateByKey(zeroValue, defaultPartitioner(self))(seqOp, combOp)
}
示例1:达到和reduceByKey的相同的效果
val result3 = rdd.aggregateByKey(0)((zeroValue, value) => zeroValue + value, _+_)
result3.saveAsTextFile("output")
//result结果
//(1,3),(2,6),(3,3)
示例2:取出每个分区内相同key的最大值然后分区间相加
解析:用Int.minValue做初始值,在区内找出每个key的最大的value然后分区间相加。
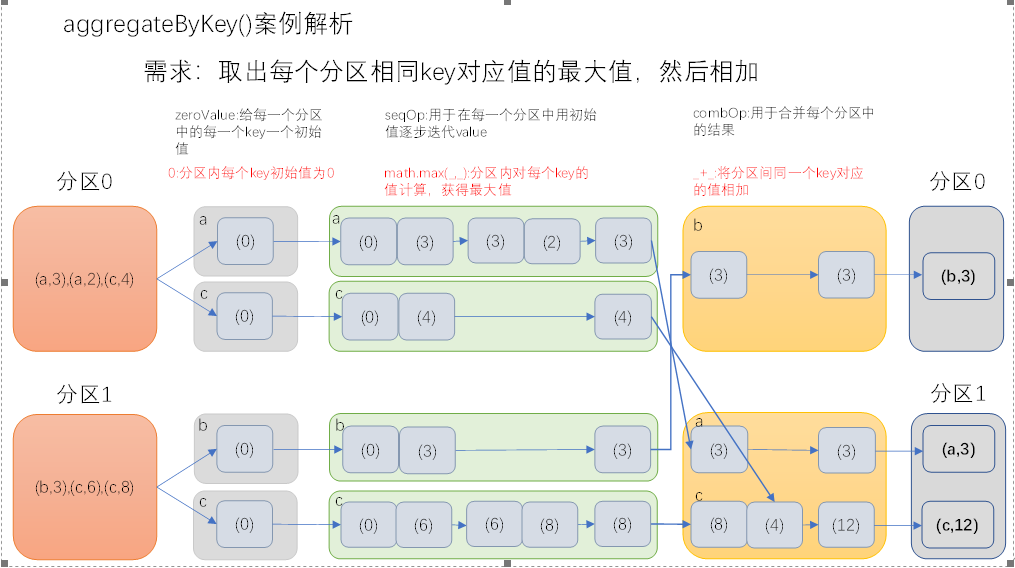
val rdd = sc.makeRDD(List((1, 2), (2, 4),(2,5), (3, 2), (1,4),(1, 1), (2, 2), (3, 1)), 2)
val result4 = rdd.aggregateByKey(Int.MinValue)((zeroValue, value) => zeroValue.max(value), (_ + _))
result4.saveAsTextFile("output")
//result结果
//(1,6),(3,3),(2,7)
示例3:分区内同时求出每个key的最大值和最小值,分区间合并
//取出每个分区内相同key的最大值和最小值,然后分区间相加 用模式匹配
val result7 = rdd.aggregateByKey((Int.MinValue, Int.MaxValue))({
//分区内,参数:zeroValue=(MinInt,MaxInt) ,区内相同key的vlaue和zeroValue迭代计算 ,返回值:(key,(最大值,最小值))
case (zeroValue, value) => (zeroValue._1.max(value), zeroValue._2.min(value))
}, {
//分区间,参数:相同key的value,zero1=(max1,min1),zero2=(max2,min2)
case (zero1, zero2) => (zero1._1+zero2._1,zero1._2+zero2._2)
})
foldByKey
参数:(zeroValue: V)(func: (V, V) => V): RDD[(K, V)]
作用:aggregateByKey的简化操作,seqop和combop相同
当分区内计算规则和分区间计算规则相同时,aggregateByKey就可以简化为foldByKey
示例:达到和reduceByKey的相同的效果
val rdd = sc.makeRDD(List((1, 2), (2, 4), (2, 5), (3, 2), (1, 4), (1, 1), (2, 2), (3, 1)), 2)
val result5 = rdd.foldByKey(0)(_ + _)
//result5结果
//(2,11),(1,7),(3,3)
combineByKey
def combineByKey[C](
createCombiner: V => C, //就是zeroValue初始值
mergeValue: (C, V) => C, //分区内计算规则
mergeCombiners: (C, C) => C): RDD[(K, C)] //分区间计算规则
aggregateByKey的增强版,aggregateByKey的zeroValue必须指定固定值,但是combineByKey的zeroValue可以通过key-value的第一个value获取。
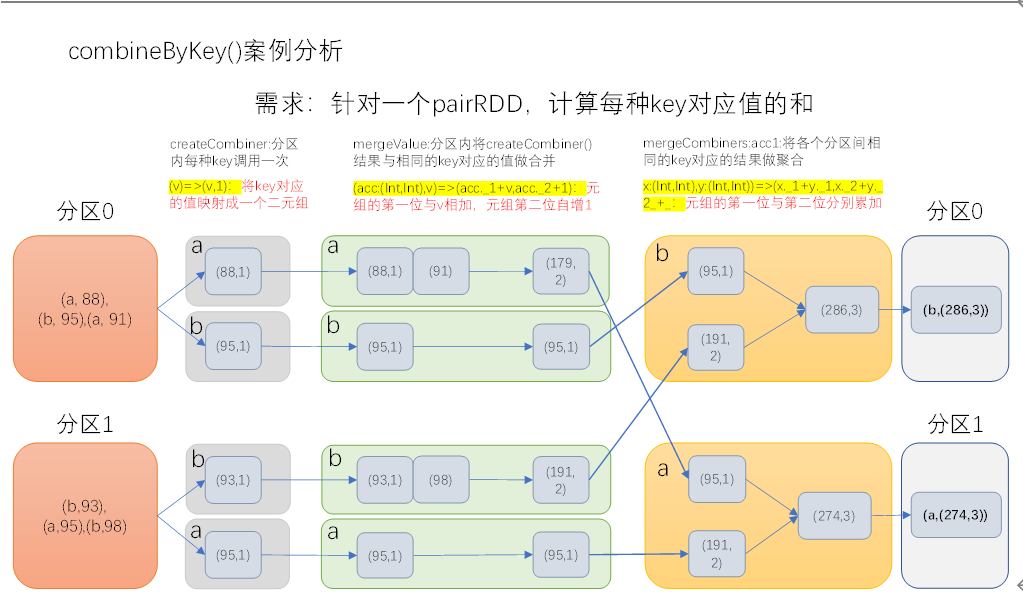
示例:将数据List(("a", 88), ("b", 95), ("a", 91), ("b", 93), ("a", 95), ("b", 98))求每个key的平均值
val rdd2 = sc.makeRDD(List(("a", 88), ("b", 95), ("a", 91), ("b", 93), ("a", 95), ("b", 98)), 2)
val result8 = rdd2.combineByKey(
//1.初始值为第一个value构建出来,后续的计算从第二个value开始 ,V=>C
value => (value, 1),
//2.分区内计算,(C,V)=>C 分区内累加
(zeroValue: Tuple2[Int, Int], value: Int) => (zeroValue._1 + value, zeroValue._2 + 1),
//3.分区间计算,(C,C)=>C ,分区间累加
(zero1: Tuple2[Int, Int], zero2: Tuple2[Int, Int]) => (zero1._1 + zero2._1, zero1._2 + zero2._2)
)
val result9 = result8.map {
case (key, value) => (key, value._1.toDouble / value._2)
}
result9.saveAsTextFile("output")
//result结果:(a,91.33333333333333),(b,95.33333333333333)
sortByKey
作用:在一个(K,V)的RDD上调用,K必须实现Ordered接口,返回一个按照key进行排序的(K,V)的RDD
函数签名
//升序:true,降序:false
def sortByKey(ascending: Boolean = true, numPartitions: Int = self.partitions.length)
: RDD[(K, V)]
join
作用:在类型为(K,V)和(K,W)的RDD上调用,返回一个相同key对应的所有元素对在一起的(K,(V,W))的RDD
inner join、left join、right join、full join
cogroup
有shuffle,RDD内先分组成(key,Iterator<T>),RDD间按照key相同聚合成Tuple2。
示例
val rdd2 = sc.makeRDD(List(("a", 88), ("b", 95), ("a", 91), ("b", 93), ("a", 95), ("b", 98)), 2)
val rdd5 = sc.makeRDD(List(("a", 18), ("b", 15), ("a", 71), ("b", 53), ("a", 45), ("b", 78)))
rdd2.cogroup(rdd5).coalesce(1).saveAsTextFile("output")
结果
(a,(CompactBuffer(88, 91, 95),CompactBuffer(18, 71, 45)))
(b,(CompactBuffer(95, 93, 98),CompactBuffer(15, 53, 78)))
四.行动算子
reduce(func)
作用:通过func函数聚集RDD中的所有元素,先聚合分区内数据,再聚合分区间数据。
scala> val rdd2 = sc.makeRDD(Array(("a",1),("a",3),("c",3),("d",5)))
rdd2: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[86] at makeRDD at <console>:24
scala> rdd2.reduce((x,y)=>(x._1 + y._1,x._2 + y._2))
res51: (String, Int) = (adca,12)
collect()
作用:在Driver中,以数组的形式返回数据集的所有元素。
需求:创建一个RDD,并将RDD内容收集到Driver端打印
scala> val rdd = sc.parallelize(1 to 10)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:24
scala> rdd.collect
res0: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
count、max、min、avg、sum
作用:返回RDD中元素的个数
first()
作用:返回RDD中的第一个元素
需求:创建一个RDD,返回该RDD中的第一个元素
scala> val rdd = sc.parallelize(1 to 10)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:24
scala> rdd.first
res2: Int = 1
take(n)
作用:返回一个由RDD的前n个元素组成的数组
takeOrdered(n)
作用:返回该RDD排序后的前n个元素组成的数组
aggregate
参数:(zeroValue: U)(seqOp: (U, T) ⇒ U, combOp: (U, U) ⇒ U)
作用:aggregate函数将每个分区里面的元素通过seqOp和初始值进行聚合,然后用combine函数将每个分区的结果和初始值(zeroValue)进行combine操作。这个函数最终返回的类型不需要和RDD中元素类型一致。
fold(num)(func)
作用:折叠操作,aggregate的简化操作,seqop和combop一样。
需求:创建一个RDD,将所有元素相加得到结果
saveAsTextFile(path)
作用:将数据集的元素以textfile的形式保存到HDFS文件系统或者其他支持的文件系统,对于每个元素,Spark将会调用toString方法,将它装换为文件中的文本
countByKey()
作用:针对(K,V)类型的RDD,返回一个(K,Int)的map,表示每一个key对应的元素个数。
需求:创建一个PairRDD,统计每种key的个数
foreach(func)
作用:在数据集的每一个元素上,运行函数func进行更新。
Spark(四)【RDD编程算子】的更多相关文章
- spark实验(四)--RDD编程(1)
一.实验目的 (1)熟悉 Spark 的 RDD 基本操作及键值对操作: (2)熟悉使用 RDD 编程解决实际具体问题的方法. 二.实验平台 操作系统:centos6.4 Spark 版本:1.5.0 ...
- [Spark] Spark的RDD编程
本篇博客中的操作都在 ./bin/pyspark 中执行. RDD,即弹性分布式数据集(Resilient Distributed Dataset),是Spark对数据的核心抽象.RDD是分布式元素的 ...
- Spark的RDD编程(二)公众号undefined110
创建RDD有两种方式:①读取外部数据集,lines=sc.textFile("README.md").②对一个集合进行并行化,lines=sc.parallelize([" ...
- Spark之 RDD
简介 RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素可并行计算的集合. Resilien ...
- Spark—RDD编程常用转换算子代码实例
Spark-RDD编程常用转换算子代码实例 Spark rdd 常用 Transformation 实例: 1.def map[U: ClassTag](f: T => U): RDD[U] ...
- Spark学习之路(四)—— RDD常用算子详解
一.Transformation spark常用的Transformation算子如下表: Transformation算子 Meaning(含义) map(func) 对原RDD中每个元素运用 fu ...
- Spark 系列(四)—— RDD常用算子详解
一.Transformation spark 常用的 Transformation 算子如下表: Transformation 算子 Meaning(含义) map(func) 对原 RDD 中每个元 ...
- Spark编程模型(RDD编程模型)
Spark编程模型(RDD编程模型) 下图给出了rdd 编程模型,并将下例中用 到的四个算子映射到四种算子类型.spark 程序工作在两个空间中:spark rdd空间和 scala原生数据空间.在原 ...
- Spark菜鸟学习营Day3 RDD编程进阶
Spark菜鸟学习营Day3 RDD编程进阶 RDD代码简化 对于昨天练习的代码,我们可以从几个方面来简化: 使用fluent风格写法,可以减少对于中间变量的定义. 使用lambda表示式来替换对象写 ...
随机推荐
- 这一篇 K8S(Kubernetes)集群部署 我觉得还可以!!!
点赞再看,养成习惯,微信搜索[牧小农]关注我获取更多资讯,风里雨里,小农等你,很高兴能够成为你的朋友. 国内安装K8S的四种途径 Kubernetes 的安装其实并不复杂,因为Kubernetes 属 ...
- HydroD:辅助脚本函数
HydroD:辅助函数 在HydroD中,使用JS脚本可以快速进行模拟参数设置,但是经过尝试,HydroD中的JS脚本语言并不支持现在JavaScript中的一些语法.所以考虑采用Matlab字符串拼 ...
- k3s单机版安装部署 附一键安装脚本
作者:SRE运维博客 博客地址: https://www.cnsre.cn/ 文章地址:https://www.cnsre.cn/posts/211109907029/ 相关话题:https://ww ...
- 关于 better-scroll 设置了以后无法滚动或不生效的问题
首先在mounted里面注册组件 例:let scroll = new BScroll("#commondityLeftList") 然后打印实例化对象,例:console. ...
- 写给初学者的Linux errno 错误码机制
不同于Java的异常处理机制, 当你使用C更多的接触到是基于错误码的异常机制, 简单来说就是当调用的函数发生异常时, 程序不会跳转到一个统一处理异常的地方, 取而代之的是返回一个整型错误码. 可能会有 ...
- SpringBoot 居然有 44 种应用启动器
啥是应用启动器?SpringBoot集成了spring的很多模块,比如tomcat.redis等等.你用SpringBoot搭建项目,只需要在pom.xml引入相关的依赖,和在配置文件中简单的配置就可 ...
- [源码解析] PyTorch 分布式(4)------分布式应用基础概念
[源码解析] PyTorch 分布式(4)------分布式应用基础概念 目录 [源码解析] PyTorch 分布式(4)------分布式应用基础概念 0x00 摘要 0x01 基本概念 0x02 ...
- Part 31 AngularJS page refresh problem
What is the issue : When you navigate to http://localhost/students, you will see list of students as ...
- OPA-Gatekeeper实验:对特定用户的更新时间窗口做限制
实验目的 OPA-Gatekeeper可以在Kubernetes 中,通过策略来实现一些额外的管理.安全方面的限制,例如:限制特定用户在 Namespace 中的行为权限 本次实验将在test命名空间 ...
- 如何在C#中使用Google.Protobuf工具
protobuf是一个语言无关.平台无关的序列化协议,由谷歌开源提供.再加上其高性能.存储占用更小等特点,在云原生的应用中越来越广泛. 在C#中主要有两种方法来使用protobuf协议,nuget包分 ...