scrapy快速入门
1. 什么是scrapy?
其官网是这样简述的,“A Fast & Powerful Scraping &Crawling Framework ”, 并且其底层以twisted作为网络架构( Python实现的基于事件驱动的网络引擎框架),所以爬取效率及性能出色。
定义·:Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中。其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试
2. scrapy模块执行与通信流程
2.1 流程图:
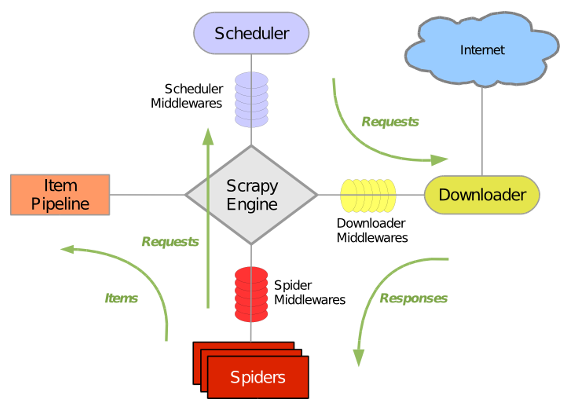
2.2 各大组件的作用:
引擎 (Scrapy Engine):用来处理整个系统的数据流,触发事物(框架核心)
调度器 (Scheduler):用来接收引擎发送的请求,压入请求队列中,并在引擎再次请求的时候返回,可以想象成一个url(待爬取网页的url)的优先队列,由他决定下一个要抓取的网址是什么,同时去除重复的网址
下载器 (Downloader):顾名思义,用于下载网页代码,并将结果返回给spider
爬虫 (Spiders): 蜘蛛呢,就是执行者,用于解析网页中的信息,即实体(Item)
项目管 道(Pipeline): 负责处理爬虫从网页中抽取的实体,主要功能是持久化实体,验证实体的有效性,清除不需要的信息。当爬虫被解析后,将被发送至项目管道,并经过几个特定次序来处理数据
下载中间件 (Downloader Middlewares): 位于Engine及Spider之间的框架,主要工作是处理scrapy engine与Downloader之间的请求及响应
爬虫中间件 (Spider Middlewares): 位于Engine及Spider之间的框架,主要工作是处理scrapy engine与spider之间的响应输入及请求输出
调度中间件 (Schedule Middlewares): 介于scrapy engine及scheduler之间的中间件,处理从scrapy engine发送到scheduler的请求响应
2.3 是不是感觉一头雾水,那我们直接上过程就很清楚啦
3. scrapy的基本使用
3.1 安装
# 这里我们用conda创建一个名为rawling_py36的虚拟环境
conda create --name crawling_py36 python=3.6 # 进入环境
activate crawling_py36 # 安装scrapy
conda install scrapy # 退出当前环境(windows)
deactivate
说明:也可以使用pip install scrapy命令进行安装, 但是在windows平台下, scrapy依赖pypiwin32模块,在执行pip install scrapy命令前,请先执行pip install pypiwin32
3.2 开始(这里以爬取糗事百科段子为例)
a. 新建项目
# 新建一个文件夹 并进入文件夹
mkdir spider_projects
cd ./spider_projects # 进入虚拟环境
activate crawling_py36 # 新建爬虫项目,
scrapy startproject qsbk #提示成功
b.新建爬虫

其域名为qiushibaike.com,我们这里根据域名新建一个spider
# 一定要在项目文件夹下
cd qsbk scrapy genspider qsbk_spider qiushibaike.com
成功之后,其文件树结构为:

c. 分析网页结构(https://www.qiushibaike.com/text/)
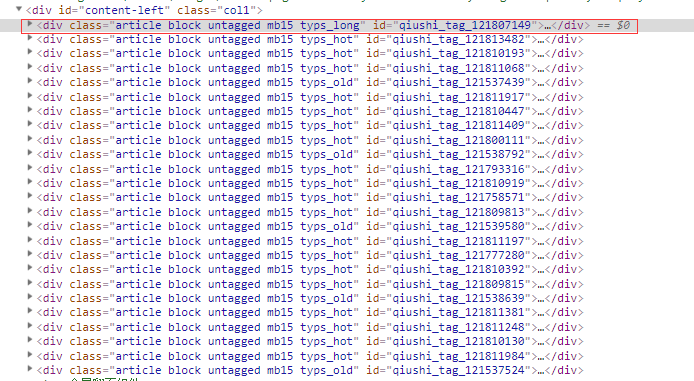
那么红圈里的div就是当前页的所有段子信息,我们使用xpath进行解析,那么每一个段子的xpath语法为 //div[@id='content-left']/div[contains(@class,'article')]

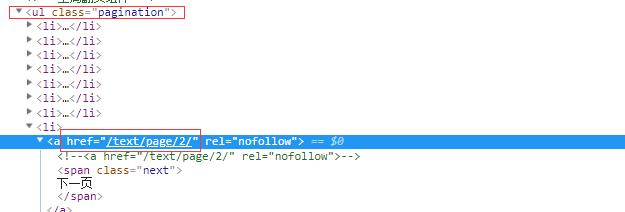
提取下一页的地址的xpath语法为 //ul[@class='pagination']/li[last()]/a/@href
d. 开始
爬虫配置 (settings.py):
# Obey robots.txt rules
ROBOTSTXT_OBEY = False # Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36',
} # Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'qsbk.pipelines.QsbkPipeline': 300,
}
解析数据(qsbk_spider.py):
# -*- coding: utf-8 -*-
import scrapy
from ..items import QsbkItem class QsbkSpiderSpider(scrapy.Spider):
name = 'qsbk_spider'
allowed_domains = ['qiushibaike.com']
start_urls = ['https://www.qiushibaike.com/text/page/1/']
base_domain = "https://www.qiushibaike.com" def parse(self, response):
# 获取所有段子信息
texts = response.xpath("//div[@id='content-left']/div[contains(@class, 'article')]")
# 提取单个段子信息
for text in texts:
author_info = text.xpath("./div[contains(@class,'author')]")
head_img = 'http:' + author_info.xpath(".//img/@src").get().strip()
author_name = author_info.xpath(".//h2/text()").get().strip()
content_list = text.xpath(".//div[@class='content']/span/text()").getall()
content = ''.join(content_list).strip() article_item = QsbkItem(author_name=author_name, head_img=head_img, content=content) yield article_item # 下一页的地址
next_page_url = response.xpath("//ul[@class='pagination']/li[last()]/a/@href").get() if next_page_url:
yield scrapy.Request(url=self.base_domain+next_page_url, callback=self.parse)
else:
return
结构化实体(items.py):
# -*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html import scrapy class QsbkItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
author_name = scrapy.Field()
head_img = scrapy.Field()
content = scrapy.Field()
持久化数据(pipelines.py):
# -*- coding: utf-8 -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html # import json
# class QsbkPipeline(object):
#
# def open_spider(self, spider):
# print('start crawling....')
# self.file = open('qsbk.json','w' , encoding='utf-8')
#
# def process_item(self, item, spider):
# item_json = json.dumps(dict(item), ensure_ascii=False)
# self.file.write(item_json+'\n')
# return item
#
# def close_spider(self, spider):
# self.file.close()
# print('stop crawling.....') # 一次性写入
# from scrapy.exporters import JsonItemExporter, JsonLinesItemExporter
# class QsbkPipeline(object):
#
# def open_spider(self, spider):
# print('start crawling....')
# self.file = open('qsbk.json', 'wb')
# self.exporter = JsonItemExporter(self.file, ensure_ascii=False)
# self.exporter.start_exporting()
#
# def process_item(self, item, spider):
# self.exporter.export_item(item)
#
# def close_spider(self, spider):
# self.exporter.finish_exporting()
# self.file.close()
# print('stop crawling.....') # 分行写入,(在数据量很大的时候推荐使用)
from scrapy.exporters import JsonLinesItemExporter
class QsbkPipeline(object): def open_spider(self, spider):
print('start crawling....')
self.file = open('qsbk.json', 'wb')
self.exporter = JsonLinesItemExporter(self.file, ensure_ascii=False) def process_item(self, item, spider):
self.exporter.export_item(item)
return item def close_spider(self, spider):
self.file.close()
print('stop crawling.....')
说明: 为了避免每次爬取使用命令行,可以在项目根目录下新建 run.py 代替命令行执行, 而scrapy也同样提供了执行cmd命令这一模块
启动爬虫(run.py)
from scrapy import cmdline
cmdline.execute("scrapy crawl qsbk_spider".split())
e.爬取结束(qsbk.json)

scrapy快速入门的更多相关文章
- scrapy 快速入门
https://blog.csdn.net/u011054333/article/details/70165401
- Scrapy框架-scrapy框架快速入门
1.安装和文档 安装:通过pip install scrapy即可安装. Scrapy官方文档:http://doc.scrapy.org/en/latest Scrapy中文文档:http://sc ...
- Scrapy爬虫快速入门
安装Scrapy Scrapy是一个高级的Python爬虫框架,它不仅包含了爬虫的特性,还可以方便的将爬虫数据保存到csv.json等文件中. 首先我们安装Scrapy. pip install sc ...
- 快速入门 Python 数据分析实用指南
Python 现如今已成为数据分析和数据科学使用上的标准语言和标准平台之一.那么作为一个新手小白,该如何快速入门 Python 数据分析呢? 下面根据数据分析的一般工作流程,梳理了相关知识技能以及学习 ...
- Web Api 入门实战 (快速入门+工具使用+不依赖IIS)
平台之大势何人能挡? 带着你的Net飞奔吧!:http://www.cnblogs.com/dunitian/p/4822808.html 屁话我也就不多说了,什么简介的也省了,直接简单概括+demo ...
- SignalR快速入门 ~ 仿QQ即时聊天,消息推送,单聊,群聊,多群公聊(基础=》提升)
SignalR快速入门 ~ 仿QQ即时聊天,消息推送,单聊,群聊,多群公聊(基础=>提升,5个Demo贯彻全篇,感兴趣的玩才是真的学) 官方demo:http://www.asp.net/si ...
- 前端开发小白必学技能—非关系数据库又像关系数据库的MongoDB快速入门命令(2)
今天给大家道个歉,没有及时更新MongoDB快速入门的下篇,最近有点小忙,在此向博友们致歉.下面我将简单地说一下mongdb的一些基本命令以及我们日常开发过程中的一些问题.mongodb可以为我们提供 ...
- 【第三篇】ASP.NET MVC快速入门之安全策略(MVC5+EF6)
目录 [第一篇]ASP.NET MVC快速入门之数据库操作(MVC5+EF6) [第二篇]ASP.NET MVC快速入门之数据注解(MVC5+EF6) [第三篇]ASP.NET MVC快速入门之安全策 ...
- 【番外篇】ASP.NET MVC快速入门之免费jQuery控件库(MVC5+EF6)
目录 [第一篇]ASP.NET MVC快速入门之数据库操作(MVC5+EF6) [第二篇]ASP.NET MVC快速入门之数据注解(MVC5+EF6) [第三篇]ASP.NET MVC快速入门之安全策 ...
随机推荐
- mysql 安装命令
mysqld install MySQL --defaults-file="D:\worksoft\mysql-5.7.17-winx64\my-default.ini" D:\w ...
- SpringBoot使用MongoDB
一.什么是MongoDB MongoDB是一个基于分布式文件存储的数据库,由C++语言编写.旨在为WEB应用提供可扩展的高性能数据存储解决方案. MongoDB是一个介于关系数据库和非关系数据库之间的 ...
- 1.1.1最短路(Floyd、Dijstra、BellmanFord)
转载自hr_whisper大佬的博客 [ 一.Dijkstra 比较详细的迪杰斯特拉算法讲解传送门 Dijkstra单源最短路算法,即计算从起点出发到每个点的最短路.所以Dijkstra常常作为其他算 ...
- 【转】【开源下载】基于TCP网络通信的即时聊天系统(IM系统)(c#源码)
原文链接 强烈关注,学习!
- 017:COM1无法打开
重新安装系统以后,COM1无法正常打开,重启以后也是如此.到设备管理器下,禁用COM1然后重启可以正常使用.修改COM1为别的COM号,重启以后可以正常使用.用Pcomm控件,打开该串口,错误号是-8 ...
- E. Comments dfs模拟
http://codeforces.com/contest/747/problem/E 首先,把字符串变成这个样子. hello,2,ok,0,bye,0,test,0,one,1,two,2,a,0 ...
- snort + barnyard2如何正确读取snort.unified2格式的数据集并且入库MySQL(图文详解)
不多说,直接上干货! 为什么,要写这篇论文? 是因为,目前科研的我,正值研三,致力于网络安全.大数据.机器学习研究领域! 论文方向的需要,同时不局限于真实物理环境机器实验室的攻防环境.也不局限于真实物 ...
- 转】RDD与DataFrame的转换
原博文出自于: http://www.cnblogs.com/namhwik/p/5967910.html RDD与DataFrame转换1. 通过反射的方式来推断RDD元素中的元数据.因为RDD本身 ...
- node入门(一)——安装
node可以让我们用js写服务器.此外还可以用来前端自动化开发,它找到特定服务要使用的包,然后下载.安装.管理. 首先安装node,进入官网下载需要的node版本,然后一键式傻瓜安装.(我的环境是wi ...
- poj2991 Crane
思路: 线段树每个节点维护第一条线段起点指向最后一条线段终点的向量,于是每一个操作都是一次区间更新.使用成段更新的线段树即可.实现: #include <cstdio> #include ...