spark streaming基于Kafka的开发
spark streaming使用Kafka数据源进行数据处理,本文侧重讲述实践使用。
一、基于receiver的方式
在使用receiver的时候,如果receiver和partition分配不当,很容易造成数据倾斜,使个别executor工作繁重,拖累整体处理速度。
receiver线程分配和partition的关系:
假如topic A,分配了3个receiver,topic A有5个partition,一个receiver会对应一个线程,partition 0,1,2,3,4会这样分配
1. partition和receiver的分配计算
1.1.partition 5/receiver 3 = 1;
1.2.partition 5%receiver 3 = 2;2. receiver分配到的partition
2.1.receiver 1,分配的partition编号为:0,1
2.2.receiver 2,分配的partition编号为:2,3
2.3.receiver 3,分配的partition编号为:4
⚠️由此可见,要想达到数据较均衡处理,设计好receiver线程数很重要,当然还要注意,每个topic消息处理的速度。
要想数据能更好的均衡处理,还要使每个executor分配的receiver线程数尽量均等。最好是receiver的总个数与executor的个数相同。不过在调度资源的时候,如果只是分配到一部分资源,那么等receiver分配好executor后,后期再申请到的资源,也不会有receiver重新分配。
JavaPairReceiverInputDStream<String,byte> messages =
KafkaUtils.createStream(
jssc,
String.class,byte.class,
kafka.serializer.DefaultDecoder.class,
kafka.serializer.DefaultDecoder.class,
kafkaParams,
topicMap,
StorageLevel.MEMORY_AND_DISK());
参数解析:
1.jssc:JavaStreamingContext
2.DStream的key类型
3.DStream的值类型
4.Kafka key 解析类型
5.Kafka value 解析类型
6.Kafka参数配置,map类型
1)zookeeper的配置信息
kafkaParams.put("zookeeper.connect", "192.168.1.1:2181");2)groupID
kafkaParams.put("group.id", "group");3)超时设置
kafkaParams.put("zookeeper.connection.timeout.ms", "1000");7.topic信息为map类型,如:topicMap.put(ga,2),其中ga为topic名称,2 表示为这个topic创建的线程数
8.RDD存储级别
二、基于direct的方式
Note that the typecast to HasOffsetRanges will only succeed if it is done in the first method called on the directKafkaStream, not later down a chain of methods. You can use transform() instead of foreachRDD() as your first method call in order to access offsets, then call further Spark methods. However, be aware that the one-to-one mappingbetween RDD partition and Kafka partition does not remain after any methods that shuffle or repartition, e.g. reduceByKey() or window().
需要注意的是:spark.streaming.kafka.maxRatePerPartition它是配置每个topic所有partition的最大速率,就是说不分topic,所有的消费的partition的最大速率都是一样。在有消息延迟时,我们需要设置这个参数,不然会一上来就冲很大的消息量,导致系统崩溃(这里重点讲述有延迟的处理)。
1.使用direct API可以保证每个topic的所有partition均衡的处理数据(如:topic A的所有partition的offset范围是相同的)。但需要注意的是,它会均衡每个topic的所有partition的offset范围,当有个别partition处理速度慢,它会重新均衡offset范围
2.在延迟消费时,当消费的topic的partition分区相同,但是生产速率不同,会导致消费的消息时间有很大差异
在资源分配不合理情况下:
如:topic A,topic B分别有30个partition,当分配的num-executor 3,executor-cores 5时,同时并行处理的task为15个(或分配cores总数为30),taskID小的那个topic会优先调度,由于spark的任务调度是默认是FIFO,会导致后面处理的topic时间延迟,进而下一批处理的offset偏移范围会相对调小,一直这样循环下去,会使后处理的topic消息量越来越少。
但当整体都有消息延迟,或突然降低处理量时(或sleep一段时间),两个topic的消息处理量达到一个很低的值后,当重新得到资源时,两个topic的offset范围会重新恢复到均衡的范围。
如图所示:

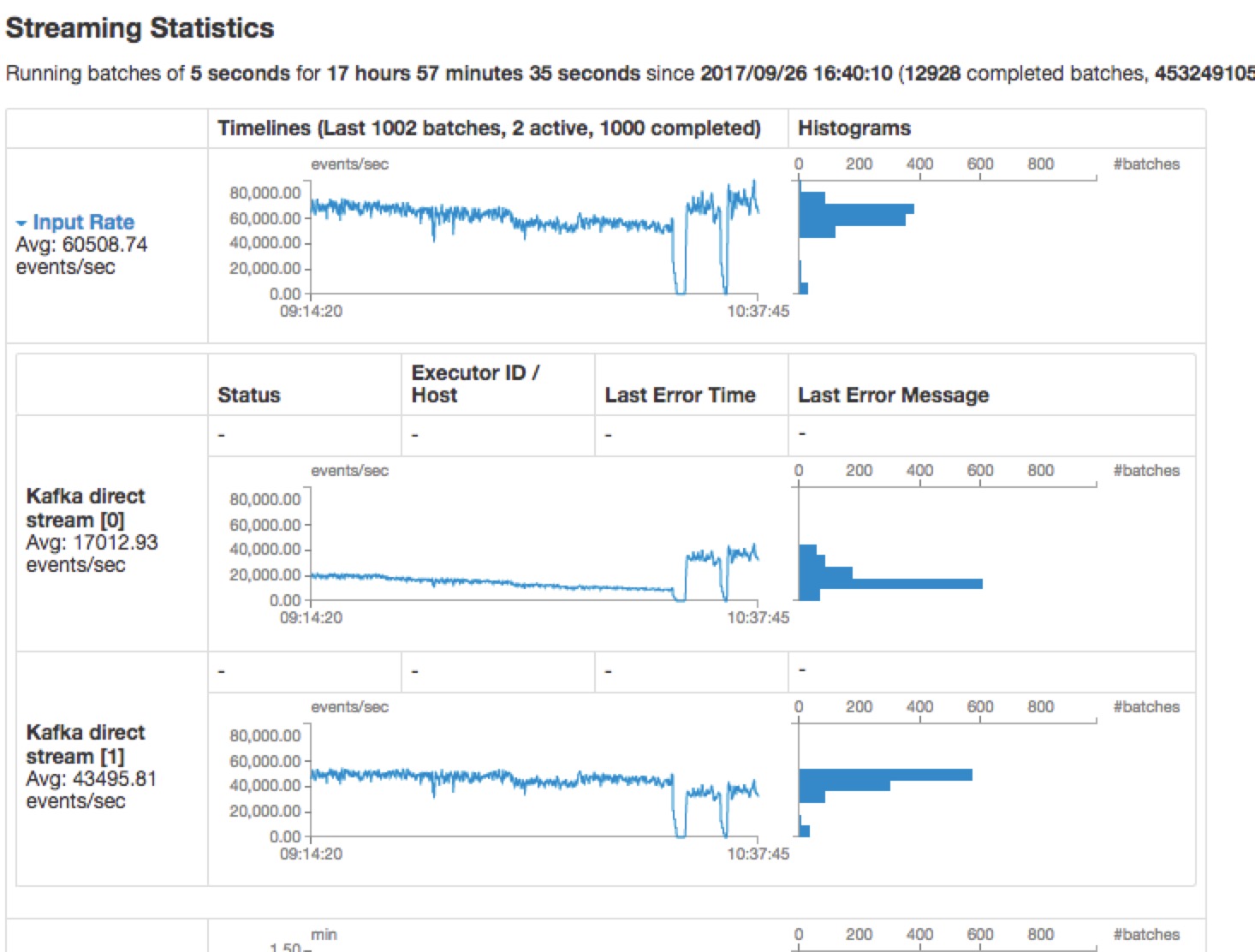
所以建议,在分配资源的时候,尽量不要被每个topic的partition个数整除,以免发生有的topic处理慢,导致消息处理量一直下降。(列表待整理:待验证)
创建directStream
JavaInputDStream<byte> message = KafkaUtils.createDirectStream(
jssc,
String.class,
byte.class,
StringDecoder.class,
DefaultDecoder.class,
byte.class,
kafkaParams,
fromOffsets,
new Function<MessageAndMetadata<String, byte>, byte>() {
@Override
public byte call(MessageAndMetadata<String, byte> v1) throws Exception {
return v1.message();
}
}
);
参数解析:
1.jssc:JavaStreamingContext
2.Kafka记录中的key的类型
3.Kafka记录中的value的类型
4.key解析类型
5.value解析类型
6.Dstream中的记录类型:定义的DStrem需要返回的类型
7.Kafka参数配置,map类型
1)broker配置信息
kafkaParams.put("metadata.broker.list", "192.168.1.1:9092,192.168.1.2:9092");2)groupID
kafkaParams.put("group.id", "group");8.fromOffsets
9.messageHandler
从Kafka读取offset信息:
final static int TIMEOUT = 100000;
final static int BUFFERSIZE = 64 * 1024;
public static Map<TopicAndPartition, Long> getLastOffsetsOrEarlist(
String brokers,
List<String> topic,
String groupId,
boolean isLastOffset) {
Map<TopicAndPartition, Long> topicOffsets = new HashMap<TopicAndPartition, Long>();
Map<TopicAndPartition, Broker> topicBroker = findLeaders(brokers, topic);
for (Map.Entry<TopicAndPartition, Broker> tp : topicBroker.entrySet()) {
Broker leader = tp.getValue();
SimpleConsumer sim_consumer = new SimpleConsumer(
leader.host(),
leader.port(),
TIMEOUT, BUFFERSIZE, groupId);
long offset;
if (isLastOffset) {
offset = getLastOffset(sim_consumer, tp.getKey(), groupId);
} else {
offset = getEarliestOffset(sim_consumer, tp.getKey(), groupId);
}
topicOffsets.put(tp.getKey(), offset);
}
return topicOffsets;
}
1.getBrokerMap
private static Map<String, Integer> getBrokderMap(String brokers) {
Map<String, Integer> brokMap = new HashMap<>();
if (brokers != null) {
String brokList = brokers.split(",");
for (String b : brokList) {
String ip_port = b.split(":");
brokMap.put(ip_port[0], Integer.parseInt(ip_port[1]));
}
}
return brokMap;
}
2.findleader
// 根据topic查找leader
public static Map<TopicAndPartition, Broker> findLeaders(String brokers, List<String> topic) {
Map<String, Integer> brokMap = getBrokderMap(brokers);
Map<TopicAndPartition, Broker> topicBroker = new HashMap<>();
String client_name = "client_" + topic.get(0) + "_" + System.currentTimeMillis();
for (String b : brokMap.keySet()) {
SimpleConsumer sim_consumer = null;
try {
sim_consumer = new SimpleConsumer(b, brokMap.get(b), TIMEOUT, BUFFERSIZE, client_name);
TopicMetadataRequest request = new TopicMetadataRequest(topic);
TopicMetadataResponse response = sim_consumer.send(request);
List<TopicMetadata> metadata = response.topicsMetadata();
for (TopicMetadata t : metadata) {
for (PartitionMetadata p : t.partitionsMetadata()) {
TopicAndPartition topicAndPartition = new TopicAndPartition(t.topic(), p.partitionId());
topicBroker.put(topicAndPartition, p.leader());
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
if (sim_consumer != null) {
sim_consumer.close();
}
}
}
return topicBroker;
}
3.getLasetOffset或getEarliestOffset
// 根据topicAndPartition得到offset值
private static Long getLastOffset(
SimpleConsumer consumer, TopicAndPartition tp, String clientName) {
Map<TopicAndPartition, PartitionOffsetRequestInfo> requestInfo = new HashMap<>();
requestInfo.put(tp, new PartitionOffsetRequestInfo(kafka.api.OffsetRequest.LatestTime(), 1));
OffsetRequest request = new OffsetRequest(requestInfo, kafka.api.OffsetRequest.CurrentVersion(), clientName);
OffsetResponse response = consumer.getOffsetsBefore(request);
if (response.hasError()) {
System.out.println("Error fetching data Offset Data the Broker. Reason: "
+ response.errorCode(tp.topic(), tp.partition()));
}
long offsets = response.offsets(tp.topic(), tp.partition());
return offsets[0];
}
private static Long getEarliestOffset(
SimpleConsumer consumer,
TopicAndPartition tp,
String clientName) {
Map<TopicAndPartition, PartitionOffsetRequestInfo> requestInfo = new HashMap<>();
requestInfo.put(tp, new PartitionOffsetRequestInfo(kafka.api.OffsetRequest.EarliestTime(), 1));
OffsetRequest request = new OffsetRequest(requestInfo, kafka.api.OffsetRequest.CurrentVersion(), clientName);
OffsetResponse response = consumer.getOffsetsBefore(request);
if (response.hasError()) {
System.out.println("Error fetching data Offset Data the Broker. Reason: "
+ response.errorCode(tp.topic(), tp.partition()));
}
long offsets = response.offsets(tp.topic(), tp.partition());
return offsets[0];
}
spark streaming基于Kafka的开发的更多相关文章
- 【转】Spark Streaming和Kafka整合开发指南
基于Receivers的方法 这个方法使用了Receivers来接收数据.Receivers的实现使用到Kafka高层次的消费者API.对于所有的Receivers,接收到的数据将会保存在Spark ...
- Spark Streaming和Kafka整合开发指南(二)
在本博客的<Spark Streaming和Kafka整合开发指南(一)>文章中介绍了如何使用基于Receiver的方法使用Spark Streaming从Kafka中接收数据.本文将介绍 ...
- Spark Streaming和Kafka整合开发指南(一)
Apache Kafka是一个分布式的消息发布-订阅系统.可以说,任何实时大数据处理工具缺少与Kafka整合都是不完整的.本文将介绍如何使用Spark Streaming从Kafka中接收数据,这里将 ...
- Spark Streaming on Kafka解析和安装实战
本课分2部分讲解: 第一部分,讲解Kafka的概念.架构和用例场景: 第二部分,讲解Kafka的安装和实战. 由于时间关系,今天的课程只讲到如何用官网的例子验证Kafka的安装是否成功.后续课程会接着 ...
- spark streaming 对接kafka记录
spark streaming 对接kafka 有两种方式: 参考: http://group.jobbole.com/15559/ http://blog.csdn.net/kwu_ganymede ...
- Spark streaming消费Kafka的正确姿势
前言 在游戏项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端,我们利用了spark streaming从kafka中不 ...
- spark streaming集成kafka
Kakfa起初是由LinkedIn公司开发的一个分布式的消息系统,后成为Apache的一部分,它使用Scala编写,以可水平扩展和高吞吐率而被广泛使用.目前越来越多的开源分布式处理系统如Clouder ...
- spark streaming 整合 kafka(一)
转载:https://www.iteblog.com/archives/1322.html Apache Kafka是一个分布式的消息发布-订阅系统.可以说,任何实时大数据处理工具缺少与Kafka整合 ...
- spark streaming 接收kafka消息之五 -- spark streaming 和 kafka 的对接总结
Spark streaming 和kafka 处理确保消息不丢失的总结 接入kafka 我们前面的1到4 都在说 spark streaming 接入 kafka 消息的事情.讲了两种接入方式,以及s ...
随机推荐
- 51nod 1154 回文串划分
1154 回文串划分 基准时间限制:1 秒 空间限制:131072 KB 分值: 40 难度:4级算法题 收藏 关注 有一个字符串S,求S最少可以被划分为多少个回文串. 例如:abbaabaa,有 ...
- 递推DP UVA 607 Scheduling Lectures
题目传送门 题意:教授给学生上课,有n个主题,每个主题有ti时间,上课有两个限制:1. 每个主题只能在一节课内讲完,不能分开在多节课:2. 必须按主题顺序讲,不能打乱.一节课L时间,如果提前下课了,按 ...
- 题解报告:hdu 2094 产生冠军
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=2094 Problem Description 有一群人,打乒乓球比赛,两两捉对撕杀,每两个人之间最多打 ...
- Person p = new Person("zhangsan",20);该句话都做了什么事情?
1,因为new用到了Person.class.所以会先找到Person.class文件并加载到内存中.2,执行该类中的static代码块,如果有的话,给Person.class类进行初始化.3,在堆内 ...
- AngularJs调用NET MVC 控制器中的函数进行后台操作
题目中提到的控制器指的是.NET MVC的控制器,不是angularjs的控制器. 首先看主页面的代码: <!DOCTYPE html> <html> <head> ...
- 【先定一个小目标】Asp.net Core 在IIS上的托管运行
1.安装 .NET Core Framework 下载.net core地址:官网地址 2.Install IIS 在控制面板->程序与功能->Internet Infomation Se ...
- Objective-C Foundation 框架 Example :Looking for Files 查找文件
Objective-C Foundation 框架 Example :Looking for Files 查找文件 NSFileManager. The NSFileManager class ...
- VS2015 update3 安装 asp.net core 失败
CMD 命令下执行: C:\DotNetCore\DotNetCore.1.0.0-VS2015Tools.Preview2.exe SKIP_VSU_CHECK=1
- codeforces_1065_D.three pieces_思维
题意:一个正方形棋盘,三种棋子,knight:像中国象棋中的马一样走:bishop:斜着走:rook:中国象棋中的车.棋盘中每个格子中标着1--n*n的互不相同的数字,从1开始任选一种棋子开始走,在每 ...
- JAVA——不简单的fianl关键字
protected用来修饰 域,代表域的访问权限是:包权限 或者 不同包,但是是子类 : final 修饰常量只要是该常量代入的计算式,在编译时期,就会被执行计算,以减轻运行时的负担.(只对基本数据类 ...