Python爬虫学习笔记(一)
概念:
使用代码模拟用户,批量发送网络请求,批量获取数据。
分类:
通用爬虫:
通用爬虫是搜索引擎(Baidu、Google、Yahoo等)“抓取系统”的重要组成部分。
主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份。
简单来讲就是尽可能的把互联网上的所有的网页下载下来,放到本地服务器里形成备分,
在对这些网页做相关处理(提取关键字、去掉广告),最后提供一个用户检索接口。
聚焦爬虫:
聚焦爬虫是根据指定的需求抓取网络上指定的数据。
例如:获取豆瓣上电影的名称和影评,而不是获取整张页面中所有的数据值。
增量式爬虫:
增量式是用来检测网站数据更新的情况,且可以将网站更新的数据进行爬取。
Robots协议:
robots协议也叫robots.txt(统一小写)是一种存放于网站根目录下的ASCII编码的文本文件,它通常告诉网络搜索引擎的漫游器(又称网络蜘蛛),此网站中的哪些内容是不应被搜索引擎的漫游器获取的,哪些是可以被漫游器获取的。 因为一些系统中的URL是大小写敏感的,所以robots.txt的文件名应统一为小写。robots.txt应放置于网站的根目录下。
如果想单独定义搜索引擎的漫游器访问子目录时的行为,那么可以将自定的设置合并到根目录下的robots.txt,或者使用robots元数据(Metadata,又称元数据)。
robots协议并不是一个规范,而只是约定俗成的,所以并不能保证网站的隐私。
简单来说,robots决定是否允许爬虫(通用爬虫)抓取某些内容。
注:聚焦爬虫不遵守robots。
eg:

爬取流程:
大多数情况下的需求,我们都会指定去使用聚焦爬虫,也就是爬取页面中指定部分的数据值,而不是整个页面的数据。
- 指定url
- 发起请求
- 获取响应数据
- 数据解析
- 持久化存储
Test:
Test1:


import urllib.request def load_data():
url = "http://www.baidu.com/"
#GET请求
#http请求
#response:http响应对象
response = urllib.request.urlopen(url)
print(response) load_data()
urllib

Test2:
import urllib.request def load_data():
url = "http://www.baidu.com/"
#GET请求
#http请求
#response:http响应对象
response = urllib.request.urlopen(url)
print(response)
#读取内容 byte类型
data = response.read()
print(data)
load_data()
读取内容
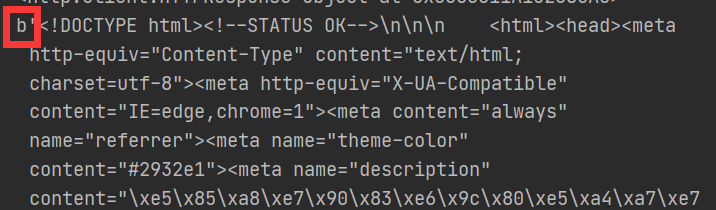
Test3:
import urllib.request def load_data():
url = "http://www.baidu.com/"
#GET请求
#http请求
#response:http响应对象
response = urllib.request.urlopen(url)
#print(response)
#读取内容 byte类型
data = response.read()
#print(data)
#将文件获取的内容转换为字符串
str_data = data.decode("UTF-8")
print(str_data)
load_data()
字符串方式读取内容
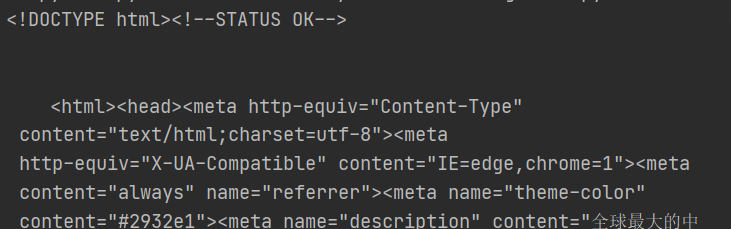
Test4:
import urllib.request def load_data():
url = "http://www.baidu.com/"
#GET请求
#http请求
#response:http响应对象
response = urllib.request.urlopen(url)
#print(response)
#读取内容 byte类型
data = response.read()
#print(data)
#将文件获取的内容转换为字符串
str_data = data.decode("UTF-8")
#print(str_data)
#将数据写入文件
with open("baidu.html", "w", encoding="utf-8") as f:
f.write(str_data)
load_data()
将数据写入文件
注:
出于安全性,https请求的话将无法打开,而http则可以打开。
Test5:
str_name = "baidu"
bytes_name = str_name.encode("utf-8")
print(str_name)
将字符串类型传唤为bytes

注:
python爬取的类型:str,bytes
如果爬取返回的是bytes类型:但写入的时候需要字符串 => decode(“utf-8”);
如果爬取返回的是str类型:但写入的时候需要bytes类型 => encode(“utf-8”).
Test1 ~ Test4代码:
import urllib.request def load_data():
url = "http://www.baidu.com/"
#GET请求
#http请求
#response:http响应对象
response = urllib.request.urlopen(url)
#print(response)
#读取内容 byte类型
data = response.read()
#print(data)
#将文件获取的内容转换为字符串
str_data = data.decode("UTF-8")
#print(str_data)
#将数据写入文件
with open("baidu.html", "w", encoding="utf-8") as f:
f.write(str_data)
#将字符串类型传唤为bytes
str_name = "baidu"
bytes_name = str_name.encode("utf-8")
print(str_name) load_data()
Test5:
import urllib.request
import urllib.parse
import string def get_method_params():
url = "http://www.baidu.com/?wd="
#拼接字符串(汉字)
name = "爬虫"
final_url = url + name
#print(final_url)
#代码发送了请求
#网址里面包含了汉字;ascii是没有汉字的;URL转义
#使用代码发送网络请求
#将包含汉字的网址进行转义
encode_new_url = urllib.parse.quote(final_url, safe=string.printable)
#response = urllib.request.urlopen(final_url)
print(encode_new_url)
#UnicodeEncodeError: 'ascii' codec can't encode characters in position 15-16: ordinal not in range(128)
#针对报错结合上一条注释的解释:
#python是解释性语言;解释器只支持 ascii 0 - 127,即不支持中文!!! get_method_params()
GET - params
import urllib.request
import urllib.parse
import string def get_method_params():
url = "http://www.baidu.com/?wd="
#拼接字符串(汉字)
name = "爬虫"
final_url = url + name
#print(final_url)
#代码发送了请求
#网址里面包含了汉字;ascii是没有汉字的;URL转义
#将包含汉字的网址进行转义
encode_new_url = urllib.parse.quote(final_url, safe=string.printable)
response = urllib.request.urlopen(encode_new_url)
print(response)
#UnicodeEncodeError: 'ascii' codec can't encode characters in position 15-16: ordinal not in range(128)
#针对报错结合上一条注释的解释:
#python是解释性语言;解释器只支持 ascii 0 - 127,即不支持中文!!! get_method_params()
直接运行

import urllib.request
import urllib.parse
import string def get_method_params():
url = "http://www.baidu.com/?wd="
#拼接字符串(汉字)
name = "爬虫"
final_url = url + name
#print(final_url)
#代码发送了请求
#网址里面包含了汉字;ascii是没有汉字的;URL转义
#将包含汉字的网址进行转义
encode_new_url = urllib.parse.quote(final_url, safe=string.printable)
response = urllib.request.urlopen(encode_new_url)
print(response)
#读取内容
data = response.read().decode()
print(data)
#UnicodeEncodeError: 'ascii' codec can't encode characters in position 15-16: ordinal not in range(128)
#针对报错结合上一条注释的解释:
#python是解释性语言;解释器只支持 ascii 0 - 127,即不支持中文!!! get_method_params()
读取内容
import urllib.request
import urllib.parse
import string def get_method_params():
url = "http://www.baidu.com/?wd="
#拼接字符串(汉字)
name = "爬虫"
final_url = url + name
#print(final_url)
#代码发送了请求
#网址里面包含了汉字;ascii是没有汉字的;URL转义
#将包含汉字的网址进行转义
encode_new_url = urllib.parse.quote(final_url, safe=string.printable)
response = urllib.request.urlopen(encode_new_url)
print(response)
#读取内容
data = response.read().decode()
print(data)
#保存到本地
with open("encode_test.html", "w", encoding="utf-8")as f:
f.write(data)
#UnicodeEncodeError: 'ascii' codec can't encode characters in position 15-16: ordinal not in range(128)
#针对报错结合上一条注释的解释:
#python是解释性语言;解释器只支持 ascii 0 - 127,即不支持中文!!! get_method_params()
保存到本地

参考:
https://www.bilibili.com/video/BV1XZ4y1u7Kv
Python爬虫学习笔记(一)的更多相关文章
- python爬虫学习笔记(一)——环境配置(windows系统)
在进行python爬虫学习前,需要进行如下准备工作: python3+pip官方配置 1.Anaconda(推荐,包括python和相关库) [推荐地址:清华镜像] https://mirrors ...
- Python爬虫学习笔记(三)
Cookies: 以抓取https://www.yaozh.com/为例 Test1(不使用cookies): 代码: import urllib.request # 1.添加URL url = &q ...
- python爬虫学习笔记
爬虫的分类 1.通用爬虫:通用爬虫是搜索引擎(Baidu.Google.Yahoo等)“抓取系统”的重要组成部分.主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份. 简单来讲就是尽可 ...
- Python、pip和scrapy的安装——Python爬虫学习笔记1
Python作为爬虫语言非常受欢迎,近期项目需要,很是学习了一番Python,在此记录学习过程:首先因为是初学,而且当时要求很快速的出demo,所以首先想到的是框架,一番查找选用了Python界大名鼎 ...
- 一入爬虫深似海,从此游戏是路人!总结我的python爬虫学习笔记!
前言 还记得是大学2年级的时候,偶然之间看到了学长在学习python:我就坐在旁边看他敲着代码,感觉很好奇.感觉很酷,从那之后,我就想和学长一样的厉害,就想让学长教我,请他吃了一周的饭,他答应了.从此 ...
- Python爬虫学习笔记——豆瓣登陆(一)
#-*- coding:utf-8 -*- import requests from bs4 import BeautifulSoup import html5lib import re import ...
- Python爬虫学习笔记-1.Urllib库
urllib 是python内置的基本库,提供了一系列用于操作URL的功能,我们可以通过它来做一个简单的爬虫. 0X01 基本使用 简单的爬取一个页面: import urllib2 request ...
- 【Python爬虫学习笔记(3)】Beautiful Soup库相关知识点总结
1. Beautiful Soup简介 Beautiful Soup是将数据从HTML和XML文件中解析出来的一个python库,它能够提供一种符合习惯的方法去遍历搜索和修改解析树,这将大大减 ...
- 【Python爬虫学习笔记(1)】urllib2库相关知识点总结
1. urllib2的opener和handler概念 1.1 Openers: 当你获取一个URL你使用一个opener(一个urllib2.OpenerDirector的实例).正常情况下,我们使 ...
随机推荐
- matplotlib的学习15-次坐标轴
import matplotlib.pyplot as plt import numpy as np x = np.arange(0, 10, 0.1) y1 = 0.05 * x**2 y2 = - ...
- 多年总结IDEA 使用技巧 (建议收藏!)
很长一段时间没有更新了,前段时间转测试了,浪费了一些时间,终于可以写文章了,今天来写一下之前自己开发的一些习惯,因为自己本身自己是一个极简主义所以 开发喜欢这样:. 全屏显示 我们可以使用[Prese ...
- robotframework中的参数展开
robot调用关键字传参的方式是用分隔符分开不同参数,如 keyword arg1 arg2 arg3 arg4 当参数中传入了使用@符号的列表变量时,@符号会将列表展开: @{list1}= Cre ...
- Python写一个对象,让它自己能够迭代
仿写range()对象,对象是可迭代的: 1 #!usr/bin/env python3 2 # -*- coding=utf-8 -*- 3 4 class myRange(): 5 #初始化,也叫 ...
- 二、LINUX文本处理三剑客之grep
1. grep一般格式:grep [选项] 基本正则表达式 [文件],其中基本正则表达式需要用引号引起来 引号引起来的作用:a.防止被误解为shell命令,b.可以用来查找多个单词组成的字符串 gre ...
- python初学者-从键盘输入两个数判断大小
a = int(input("a:")) b = int(input("b:")) if a > b : print(a) else : print(b)
- vue 导入.md文件(markdown转HTML)
前言 刚接到这个需求的时候,觉得很简单(的确很简单)但是这玩意的坑真的也让人无奈. 网上找了很多的资料,都没有写出痛点(这就很难过了).通过实践并且在我们项目中平稳运行,想分享给后面的人 我的博客上也 ...
- STM32串口中断的一些资料
在研究STM32串口接收发送中断的时候找到不少不错的资料,现在备份在这里.以供自己查阅,以及方便其他人. TC ====TXE 顺便预告下最近会写个有关串口处理数据的帖子,从查询和中断方面以及数据处理 ...
- java零基础之--JDK安装篇
---恢复内容开始--- 很多零基础学习者在开始学习java中很难理解JDK的安装和配置,以下是基于Windows 7 的安装配置流程(Windows 10类似) 1. 在安装之前我们先了解几个名词: ...
- 整合.NET WebAPI和 Vuejs——在.NET单体应用中使用 Vuejs 和 ElementUI
.NET简介 .NET 是一种用于构建多种应用的免费开源开发平台,例如: Web 应用.Web API 和微服务 云中的无服务器函数 云原生应用 移动应用 桌面应用 1). Windows WPF 2 ...