Python爬虫学习笔记(一)
概念:
使用代码模拟用户,批量发送网络请求,批量获取数据。
分类:
通用爬虫:
通用爬虫是搜索引擎(Baidu、Google、Yahoo等)“抓取系统”的重要组成部分。
主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份。
简单来讲就是尽可能的把互联网上的所有的网页下载下来,放到本地服务器里形成备分,
在对这些网页做相关处理(提取关键字、去掉广告),最后提供一个用户检索接口。
聚焦爬虫:
聚焦爬虫是根据指定的需求抓取网络上指定的数据。
例如:获取豆瓣上电影的名称和影评,而不是获取整张页面中所有的数据值。
增量式爬虫:
增量式是用来检测网站数据更新的情况,且可以将网站更新的数据进行爬取。
Robots协议:
robots协议也叫robots.txt(统一小写)是一种存放于网站根目录下的ASCII编码的文本文件,它通常告诉网络搜索引擎的漫游器(又称网络蜘蛛),此网站中的哪些内容是不应被搜索引擎的漫游器获取的,哪些是可以被漫游器获取的。 因为一些系统中的URL是大小写敏感的,所以robots.txt的文件名应统一为小写。robots.txt应放置于网站的根目录下。
如果想单独定义搜索引擎的漫游器访问子目录时的行为,那么可以将自定的设置合并到根目录下的robots.txt,或者使用robots元数据(Metadata,又称元数据)。
robots协议并不是一个规范,而只是约定俗成的,所以并不能保证网站的隐私。
简单来说,robots决定是否允许爬虫(通用爬虫)抓取某些内容。
注:聚焦爬虫不遵守robots。
eg:

爬取流程:
大多数情况下的需求,我们都会指定去使用聚焦爬虫,也就是爬取页面中指定部分的数据值,而不是整个页面的数据。
- 指定url
- 发起请求
- 获取响应数据
- 数据解析
- 持久化存储
Test:
Test1:


import urllib.request def load_data():
url = "http://www.baidu.com/"
#GET请求
#http请求
#response:http响应对象
response = urllib.request.urlopen(url)
print(response) load_data()
urllib

Test2:
import urllib.request def load_data():
url = "http://www.baidu.com/"
#GET请求
#http请求
#response:http响应对象
response = urllib.request.urlopen(url)
print(response)
#读取内容 byte类型
data = response.read()
print(data)
load_data()
读取内容
Test3:
import urllib.request def load_data():
url = "http://www.baidu.com/"
#GET请求
#http请求
#response:http响应对象
response = urllib.request.urlopen(url)
#print(response)
#读取内容 byte类型
data = response.read()
#print(data)
#将文件获取的内容转换为字符串
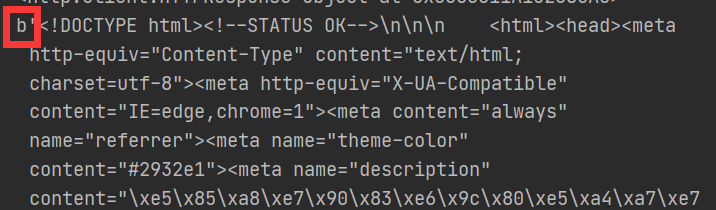
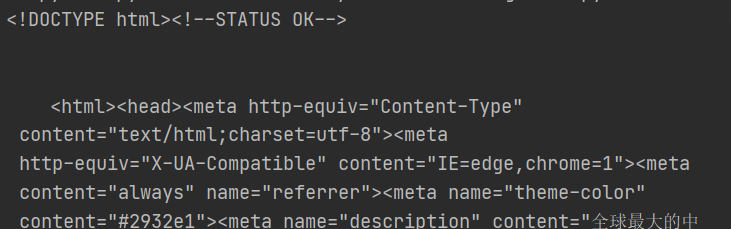
str_data = data.decode("UTF-8")
print(str_data)
load_data()
字符串方式读取内容
Test4:
import urllib.request def load_data():
url = "http://www.baidu.com/"
#GET请求
#http请求
#response:http响应对象
response = urllib.request.urlopen(url)
#print(response)
#读取内容 byte类型
data = response.read()
#print(data)
#将文件获取的内容转换为字符串
str_data = data.decode("UTF-8")
#print(str_data)
#将数据写入文件
with open("baidu.html", "w", encoding="utf-8") as f:
f.write(str_data)
load_data()
将数据写入文件
注:
出于安全性,https请求的话将无法打开,而http则可以打开。
Test5:
str_name = "baidu"
bytes_name = str_name.encode("utf-8")
print(str_name)
将字符串类型传唤为bytes

注:
python爬取的类型:str,bytes
如果爬取返回的是bytes类型:但写入的时候需要字符串 => decode(“utf-8”);
如果爬取返回的是str类型:但写入的时候需要bytes类型 => encode(“utf-8”).
Test1 ~ Test4代码:
import urllib.request def load_data():
url = "http://www.baidu.com/"
#GET请求
#http请求
#response:http响应对象
response = urllib.request.urlopen(url)
#print(response)
#读取内容 byte类型
data = response.read()
#print(data)
#将文件获取的内容转换为字符串
str_data = data.decode("UTF-8")
#print(str_data)
#将数据写入文件
with open("baidu.html", "w", encoding="utf-8") as f:
f.write(str_data)
#将字符串类型传唤为bytes
str_name = "baidu"
bytes_name = str_name.encode("utf-8")
print(str_name) load_data()
Test5:
import urllib.request
import urllib.parse
import string def get_method_params():
url = "http://www.baidu.com/?wd="
#拼接字符串(汉字)
name = "爬虫"
final_url = url + name
#print(final_url)
#代码发送了请求
#网址里面包含了汉字;ascii是没有汉字的;URL转义
#使用代码发送网络请求
#将包含汉字的网址进行转义
encode_new_url = urllib.parse.quote(final_url, safe=string.printable)
#response = urllib.request.urlopen(final_url)
print(encode_new_url)
#UnicodeEncodeError: 'ascii' codec can't encode characters in position 15-16: ordinal not in range(128)
#针对报错结合上一条注释的解释:
#python是解释性语言;解释器只支持 ascii 0 - 127,即不支持中文!!! get_method_params()
GET - params
import urllib.request
import urllib.parse
import string def get_method_params():
url = "http://www.baidu.com/?wd="
#拼接字符串(汉字)
name = "爬虫"
final_url = url + name
#print(final_url)
#代码发送了请求
#网址里面包含了汉字;ascii是没有汉字的;URL转义
#将包含汉字的网址进行转义
encode_new_url = urllib.parse.quote(final_url, safe=string.printable)
response = urllib.request.urlopen(encode_new_url)
print(response)
#UnicodeEncodeError: 'ascii' codec can't encode characters in position 15-16: ordinal not in range(128)
#针对报错结合上一条注释的解释:
#python是解释性语言;解释器只支持 ascii 0 - 127,即不支持中文!!! get_method_params()
直接运行

import urllib.request
import urllib.parse
import string def get_method_params():
url = "http://www.baidu.com/?wd="
#拼接字符串(汉字)
name = "爬虫"
final_url = url + name
#print(final_url)
#代码发送了请求
#网址里面包含了汉字;ascii是没有汉字的;URL转义
#将包含汉字的网址进行转义
encode_new_url = urllib.parse.quote(final_url, safe=string.printable)
response = urllib.request.urlopen(encode_new_url)
print(response)
#读取内容
data = response.read().decode()
print(data)
#UnicodeEncodeError: 'ascii' codec can't encode characters in position 15-16: ordinal not in range(128)
#针对报错结合上一条注释的解释:
#python是解释性语言;解释器只支持 ascii 0 - 127,即不支持中文!!! get_method_params()
读取内容
import urllib.request
import urllib.parse
import string def get_method_params():
url = "http://www.baidu.com/?wd="
#拼接字符串(汉字)
name = "爬虫"
final_url = url + name
#print(final_url)
#代码发送了请求
#网址里面包含了汉字;ascii是没有汉字的;URL转义
#将包含汉字的网址进行转义
encode_new_url = urllib.parse.quote(final_url, safe=string.printable)
response = urllib.request.urlopen(encode_new_url)
print(response)
#读取内容
data = response.read().decode()
print(data)
#保存到本地
with open("encode_test.html", "w", encoding="utf-8")as f:
f.write(data)
#UnicodeEncodeError: 'ascii' codec can't encode characters in position 15-16: ordinal not in range(128)
#针对报错结合上一条注释的解释:
#python是解释性语言;解释器只支持 ascii 0 - 127,即不支持中文!!! get_method_params()
保存到本地

参考:
https://www.bilibili.com/video/BV1XZ4y1u7Kv
Python爬虫学习笔记(一)的更多相关文章
- python爬虫学习笔记(一)——环境配置(windows系统)
在进行python爬虫学习前,需要进行如下准备工作: python3+pip官方配置 1.Anaconda(推荐,包括python和相关库) [推荐地址:清华镜像] https://mirrors ...
- Python爬虫学习笔记(三)
Cookies: 以抓取https://www.yaozh.com/为例 Test1(不使用cookies): 代码: import urllib.request # 1.添加URL url = &q ...
- python爬虫学习笔记
爬虫的分类 1.通用爬虫:通用爬虫是搜索引擎(Baidu.Google.Yahoo等)“抓取系统”的重要组成部分.主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份. 简单来讲就是尽可 ...
- Python、pip和scrapy的安装——Python爬虫学习笔记1
Python作为爬虫语言非常受欢迎,近期项目需要,很是学习了一番Python,在此记录学习过程:首先因为是初学,而且当时要求很快速的出demo,所以首先想到的是框架,一番查找选用了Python界大名鼎 ...
- 一入爬虫深似海,从此游戏是路人!总结我的python爬虫学习笔记!
前言 还记得是大学2年级的时候,偶然之间看到了学长在学习python:我就坐在旁边看他敲着代码,感觉很好奇.感觉很酷,从那之后,我就想和学长一样的厉害,就想让学长教我,请他吃了一周的饭,他答应了.从此 ...
- Python爬虫学习笔记——豆瓣登陆(一)
#-*- coding:utf-8 -*- import requests from bs4 import BeautifulSoup import html5lib import re import ...
- Python爬虫学习笔记-1.Urllib库
urllib 是python内置的基本库,提供了一系列用于操作URL的功能,我们可以通过它来做一个简单的爬虫. 0X01 基本使用 简单的爬取一个页面: import urllib2 request ...
- 【Python爬虫学习笔记(3)】Beautiful Soup库相关知识点总结
1. Beautiful Soup简介 Beautiful Soup是将数据从HTML和XML文件中解析出来的一个python库,它能够提供一种符合习惯的方法去遍历搜索和修改解析树,这将大大减 ...
- 【Python爬虫学习笔记(1)】urllib2库相关知识点总结
1. urllib2的opener和handler概念 1.1 Openers: 当你获取一个URL你使用一个opener(一个urllib2.OpenerDirector的实例).正常情况下,我们使 ...
随机推荐
- python SQLAlchemy反射生成models
1.安装SQLAcodegen pip install sqlacodegen 2.使用sqlacodegen生成案列 sqlacodegen mysql://root:123456@127.0.0. ...
- Java 面试知识点【背诵版 240题 约7w字】
-- 转载自牛客网 是瑶瑶公主吖 Java 基础 40 语言特性 12 Q1:Java 语言的优点? ① 平台无关性,摆脱硬件束缚,"一次编写,到处运行". ② 相对安全的内存管理 ...
- 用Python实现童年小游戏贪吃蛇
贪吃蛇作为一款经典小游戏,早在 1976 年就面世了,我最早接触它还是在家长的诺基亚手机中.
- NET 5 收发邮件之 MailKit
大家都用过SmtpClient来处理发送邮件的操作,不过这个类以及被标记已过时,所以介绍一个微软推荐的库MailKit来处理. MailKit开源地址:https://github.com/jsted ...
- 【升级版】如何使用阿里云云解析API实现动态域名解析,搭建私有服务器【含可执行文件和源码】
原文地址:http://www.yxxrui.cn/article/179.shtml 未经许可请勿转载,如有疑问,请联系作者:yxxrui@163.com 我遇到的问题:公司的网络没有固定的公网IP ...
- Java获取某年某月的第一天和最后一天
/** * 获取某年某月的第一天 * @Title:getFisrtDayOfMonth * @Description: * @param:@param year * @param:@param mo ...
- Springboot 源码解析-自定装配
面试官经常会问你知道springboot的自定装配吗?它是怎么实现的吗?今天我们就来通过源码一起分析下它吧.首先我们先搭建一个springboot的简单项目,找到启动类, 然后通过这个注解我们进入到@ ...
- 广告计价方式:CPM,CPC,CPA
转自知乎链接:https://www.zhihu.com/question/20416888/answer/15076251 1.CPM 收费最科学的办法是按照有多少人看到你的广告来收费.按访问人次收 ...
- Vue从零开发SPA项目
所谓SPA(single page web application),就是单页面项目的意思. vue的亮点就是我们只需要关注数据的变化,下面演示一下从零开始创建一个独立项目,并且能自定义路由,提交表单 ...
- 前端面试题归类-css
一.说下盒模型? 有两种盒模型,W3C盒模型和IE盒模型通常说的"IE盒子模型"指的是IE5.5,IE6及其以后,盒模型都为 content-box当浏览器未设置<!doct ...