目标检测的评价指标(TP、TN、FP、FN、Precision、Recall、IoU、mIoU、AP、mAP)
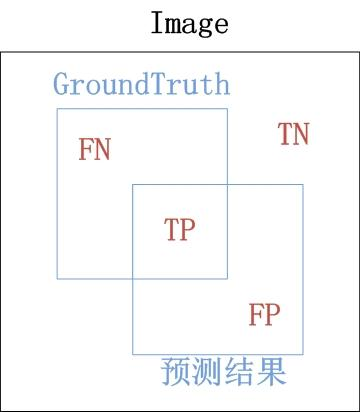
1. TP TN FP FN
GroundTruth 预测结果
TP(True Positives): 真的正样本 = 【正样本 被正确分为 正样本】
TN(True Negatives): 真的负样本 = 【负样本 被正确分为 负样本】
FP(False Positives): 假的正样本 = 【负样本 被错误分为 正样本】
FN(False Negatives):假的负样本 = 【正样本 被错误分为 负样本】
2. Precision(精度)和 Recall(召回率)
\(Precision=\frac {TP} {TP+FP} \text{ }\) 即 预测正确的部分 占 预测结果 的比例
\(Recall=\frac {TP} {TP+FN} \text{ }\) 即 预测正确的部分 占 GroundTruth 的比例
3. IoU(Intersection over Union)
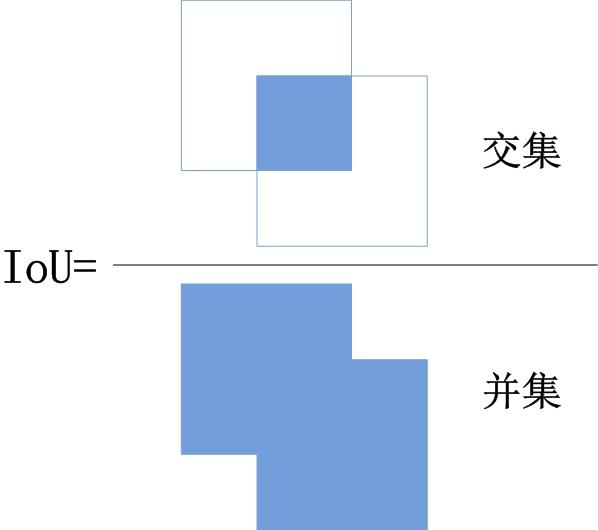
\]
4. AP
(1) 找出 预测结果 中 TP(正确的正样本) 和 FP(误分为正样本) 的检测框
设置IoU的阈值,如IoU=0.5
IoU值大于0.5 预测结果 正确;否则, 预测结果 错误,如下图所示

- \(IoU=\frac {TP} {TP+FP+FN} \gt 0.5\) 预测结果:TP
- \(IoU=\frac {TP} {TP+FP+FN} \lt 0.5\) 预测结果:FP
注意:这里的TP、FP与图示中的TP、FP在理解上略有不同
(2) 计算 不同置信度阈值 的 Precision、Recall
a. 设置不同的置信度阈值,会得到不同数量的检测框:
阈值高,得到检测框数量少;
阈值低,得到检测框数量多。
b. 对于 步骤a 中不同的置信度阈值得到 检测框(数量)=TP(数量)+FP(数量)
c. 计算Precision,按照上面步骤(1)中使用IoU计算TP、FP的方法,将步骤b中的检测框(数量)划分为TP(数量)、FP(数量)
\]
d. 计算Recall,由于TP+FN是GroundTruth(即已知的检测框的数量),则可以得到:
\]
e. 计算AP,不同置信度阈值会得到多组(Precision,Recall)
假设我们得到了三组(Precision,Recall):
(0.9, 0.2),(0.5, 0.2),(0.7, 0.6),如下图中所示
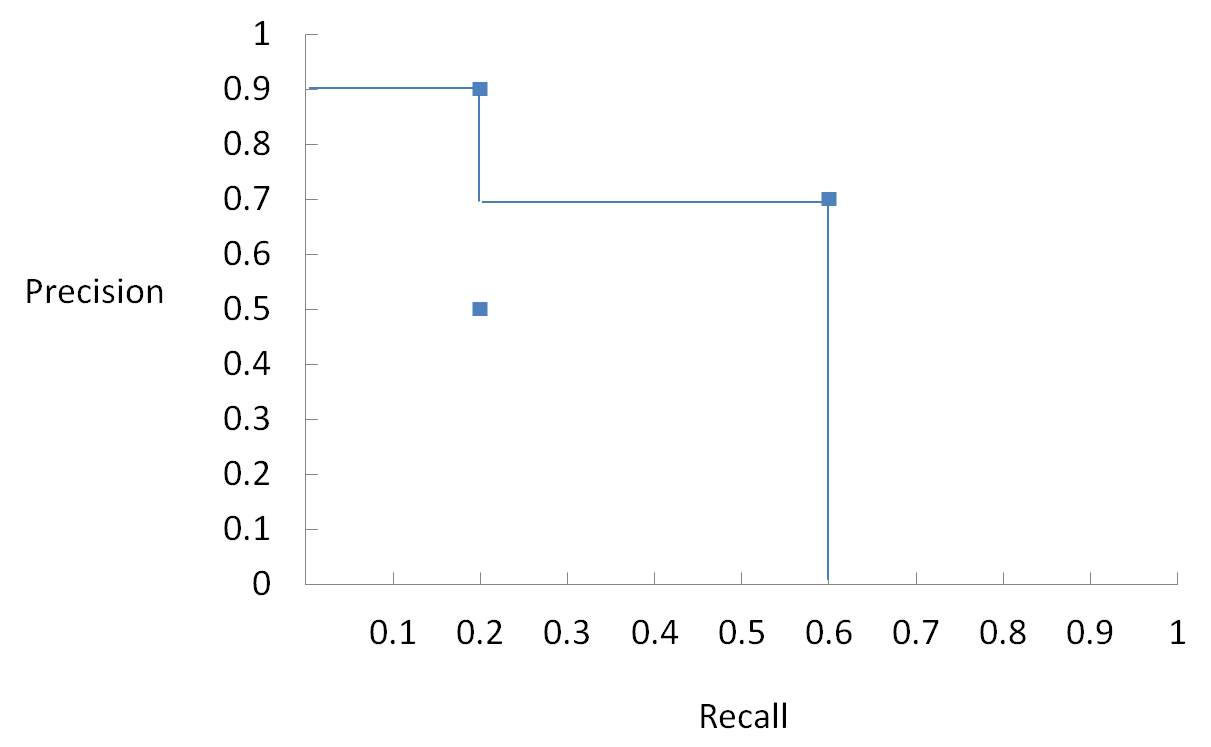
AP=上图中所围成的面积,即 AP = 0.9 x 0.2 + 0.7 x 0.4 = 0.46
5. mIoU、mAP
IoU和AP是对一个类别所计算的结果,mIoU和mAP是所有类结果的平均值。
原文:https://www.pianshen.com/article/20801175613/
目标检测的评价指标(TP、TN、FP、FN、Precision、Recall、IoU、mIoU、AP、mAP)的更多相关文章
- TP Rate ,FP Rate, Precision, Recall, F-Measure, ROC Area,
TP Rate ,FP Rate, Precision, Recall, F-Measure, ROC Area, https://www.zhihu.com/question/30643044 T/ ...
- TP 真阳性 TN FP FN
TP.True Positive 真阳性:预测为正,实际也为正 FP.False Positive 假阳性:预测为正,实际为负 FN.False Negative 假阴性:预测与负.实际为正 T ...
- 目标检测coco数据集点滴介绍
目标检测coco数据集点滴介绍 1. COCO数据集介绍 MS COCO 是google 开源的大型数据集, 分为目标检测.分割.关键点检测三大任务, 数据集主要由图片和json 标签文件组成. c ...
- 深度学习中目标检测Object Detection的基础概念及常用方法
目录 关键术语 方法 two stage one stage 共同存在问题 多尺度 平移不变性 样本不均衡 各个步骤可能出现的问题 输入: 网络: 输出: 参考资料 What is detection ...
- 目标检测的评价标准mAP, Precision, Recall, Accuracy
目录 metrics 评价方法 TP , FP , TN , FN 概念 计算流程 Accuracy , Precision ,Recall Average Precision PR曲线 AP计算 A ...
- 目标检测论文解读1——Rich feature hierarchies for accurate object detection and semantic segmentation
背景 在2012 Imagenet LSVRC比赛中,Alexnet以15.3%的top-5 错误率轻松拔得头筹(第二名top-5错误率为26.2%).由此,ConvNet的潜力受到广泛认可,一炮而红 ...
- CVPR2019目标检测方法进展综述
CVPR2019目标检测方法进展综述 置顶 2019年03月20日 14:14:04 SIGAI_csdn 阅读数 5869更多 分类专栏: 机器学习 人工智能 AI SIGAI 版权声明:本文为 ...
- CVPR2020论文介绍: 3D 目标检测高效算法
CVPR2020论文介绍: 3D 目标检测高效算法 CVPR 2020: Structure Aware Single-Stage 3D Object Detection from Point Clo ...
- 从TP、FP、TN、FN到ROC曲线、miss rate、行人检测评估
从TP.FP.TN.FN到ROC曲线.miss rate.行人检测评估 想要在行人检测的evaluation阶段要计算miss rate,就要从True Positive Rate讲起:miss ra ...
随机推荐
- Spark-5-如何定位导致数据倾斜的代码
数据倾斜只会发生在shuffle过程中.这里给大家罗列一些常用的并且可能会触发shuffle操作的算子:distinct.groupByKey.reduceByKey.aggregateByKey.j ...
- sqli-labs 20-22 --cookie注入
异常处理 一开始打开这个题目的时候找不到cookie... 登录成功就是没有cookie cookie注入没有cookie... 第二天重新做的时候,同学讲自己设置cookie可以用 用插件EditT ...
- APEX-数据导出/打印
前言: 由于公司使用了Oracle APEX构建应用,且在APEX新版本v20.2版本中增强了相关报表导出数据相关功能:正好现在做的事情也需要类似的功能,就先来学习一下Oracle的APEX相关功能及 ...
- Windows 64位下安装Redis 以及 可视化工具Redis Desktop Manager的安装和使用
二.下载Windows版本的Redis 由于现在官网上只提供Linux版本的下载,所以我们只能在Github上下载Windows版本的Redis Windows版本的Redis下载地址:https:/ ...
- .NET 5 源代码生成器——MediatR——CQRS
在这篇文章中,我们将探索如何使用.NET 5中的新source generator特性,使用MediatR库和CQRS模式自动为系统生成API. 中介者模式 中介模式是在应用程序中解耦模块的一种方式. ...
- python-使用python获取一段录音
需要安装pyaudio库. 直接上代码: import pyaudio import wave AUDIO_FILE = '录音文件.wav' def get_audio(filepath, audi ...
- Stata极简生存分析
1. 导入数据 webuse drugtr,clear *webuse -- Use dataset from Stata website stset,clear *上一行命令导入进来的数据是&quo ...
- linux系统修改不成功无法修改密码
一.问题描述 新上架的浪潮服务器使用装机平台进行统一安装,安装完成后修改用户密码时统一无法修改,使用root账户无法修改其他用户密码,自身根密码也无法修改成功,报错如下 Changing passwo ...
- #3使用html+css+js制作网页 番外篇 使用python flask 框架 (I)
#3使用html+css+js制作网页 番外篇 使用python flask 框架(I 第一部) 0. 本系列教程 1. 准备 a.python b. flask c. flask 环境安装 d. f ...
- #2使用html+css+js制作网站教程 测试
#2使用html+css+js制作网站教程 测试 本系列链接 1 测试 1.1 运行 1.2 审查 1.3 审查技巧 1.4 其他 引言: 编写完代码后就要上机测试代码,获得用户体验,筛选bug 笔者 ...