elasticsearch基本概念和基本语法
Elasticsearch是基于Json的分布式搜索和分析引擎,是利用倒排索引实现的全文索引。
优势:
横向可扩展性:增加服务器可直接配置在集群中
分片机制提供更好的分布性:分而治之的方式来提升处理效率
高可用:提供复制(replia)机制
实时性:通过将磁盘上的文件放入文件缓存系统来提高查询速度
基本概念
- Index: 一系列文档的集合,类似于mysql中数据库的概念
- Type: 在Index里面可以定义不同的type,type的概念类似于mysql中表的概念,是一系列具有相同特征数据的结合。
- Document: 文档的概念类似于mysql中的一条存储记录,并且为json格式,在Index下的不同type下,可以有许多document。
- Shards: 在数据量很大的时候,进行水平的扩展,提高搜索性能
- Replicas: 防止某个分片的数据丢失,可以并行得在备份数据里及搜索提高性能
注意:分片和副本
分片和副本
一个ES Index下面有大量数据,超过硬件的存储能力时,可以在ES中将index分成多个分片(shard),将index分片有两个作用:
横向扩展一个index的容量:
提高计算的并行度。
ES中的分片分为:主分片(primary Shard)和副本分片(Replica Shard).
主分片:index中的每个Document都属于一个唯一的主分片,所有主分片的数据决定了一个index的容量 ,主分片(Primary Shard)数量需要在Index创建的时候指定,创建后不可修改
副本分片:主分片的拷贝,不仅用于提供数据冗余,也提供数据读取服务(比如检索请求、Document获取请求等)。
一个index中每个主分片的副本分片数既可以在index创建时候指定,也可以在index创建后动态修改
默认情况设置:一个index有5个主分片,每个主分片有一个副本分片,所以默认情况下,index中总共有10个分片。
ES会保证每一个节点上相同的数据只有一份,也就是说主分片和它自己的副本分片永远不会存在一个节点上。
特点:

2、为employee的索引编入一个文档
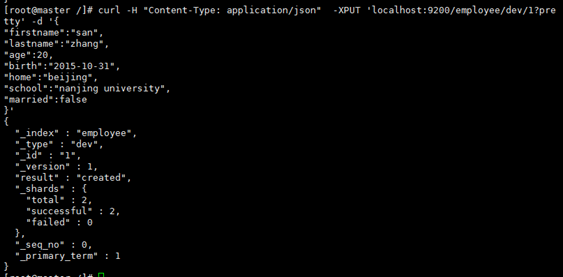
报错:

解决办法:加入:-H "Content-Type: application/json"

3、查看Document是否存在
注意:查看某个路径下的Doucment是否存在使用Head,curl要加上 – I 选项打印HTTP header

4、获取整个Document
要获取一个完整的Document,使用GET并指定Document的路径,路径的形式为/<index>/<type>/<id>

_source 字段中存储的是Document内部的数据
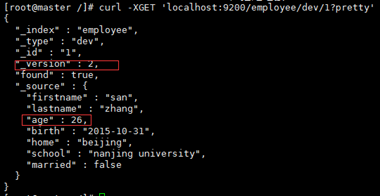
5、更新Document
说明ES中的Document不可更改,只能更新操作和编入Document相同—对想要更新的Document路径执行PUT,ES会将路径的Document版本加1
将年龄修改为26,在查看,发现年龄修改成功,版本号为2

6、删除Document
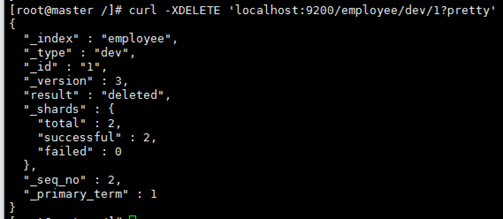
7、删除索引

8、创建Index

二、
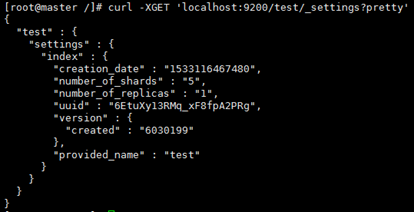
1、查看index设置
2、获取index mapping(可以查看某索引下字段的类型)

三、Cluster API
1、用于查看集群和index的健康状况:健康状况分为三种:
Green 、yellow、red。在shard级别:
|
red |
无法在集群中找到该Shard |
|
Yellow |
Shard可以找到,但是Replica找不到 |
|
green |
Shard和Replica都能找到 |
2、查看这个集群的健康状况:

3、查看集群信息
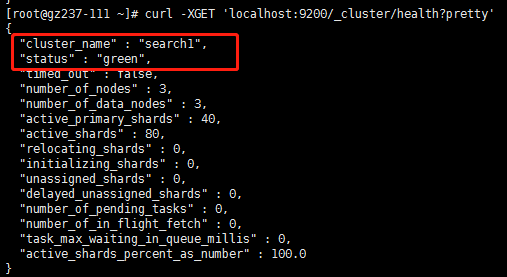
4、查看指定索引的健康状况:这里指定的索引为employee和test
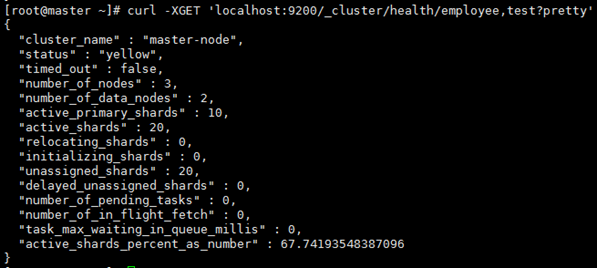
5、查看集群中所有Index的健康状况
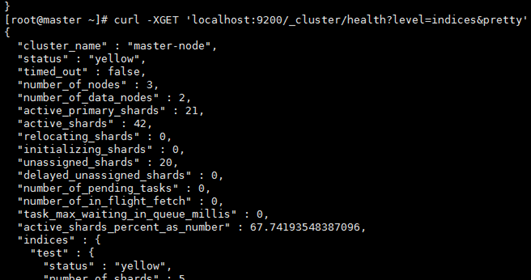
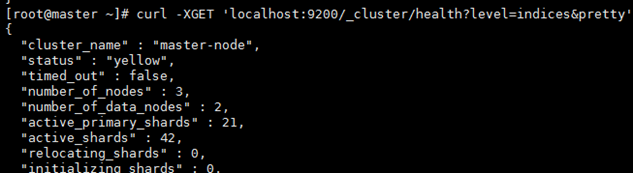
6、Cluster stats API用于获取整个集群的统计数据,包括基础的Index指标(Shard数量、存储大小、内存使用量)和节点指标(节点数量、角色、计算资源使用状况等等).
7、Cluster settings API可以用于查看(GET)或进行(PUT)集群的设置。

语法:设置批量插入的队列大小
curl -XPUT '<HOST>/_cluster/settings' -d '{
"persistent": {
"threadpool.bulk.queue_size" : 1000
}
}'
8、查看es集群nodes状态

9、查看所有节点的统计数据

10、查看指定节点的统计数据

四、检索
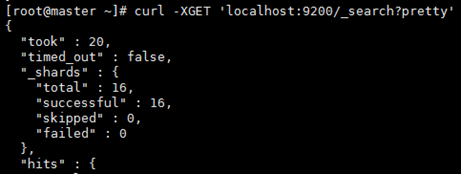
1、指定索引进行空检索

took:本次检索所花时间(单位毫秒) timed_out:本次检索是否超时。
_shards:所有本次检索涉及的分片数,分为所有涉及的(total)、成功的(successful)和失败的(failed)
2、所有Index中的dev和external Type中检索,使用_all

3、在整个ES集群的所有Document中检索
elasticsearch基本概念和基本语法的更多相关文章
- elasticsearch基本概念与查询语法
序言 后面有大量类似于mysql的sum, group by查询 elk === elk总体架构 https://www.elastic.co/cn/products Beat 基于go语言写的轻量型 ...
- Elasticsearch基本概念和使用
Elasticsearch基本概念和使用 1.操作索引 1.1.基本概念 Elasticsearch也是基于Lucene的全文检索库,本质也是存储数据,很多概念与MySQL类似的. 对比关系: 索引( ...
- HTML基础-------最初概念以及相关语法
HTML概念以及相关语法 HTML HTML是一种类似于(c,java,c++)之类的语言,他是用来描述网页的一种语言.通过各种标签所代表的语义来构建出一个网页,再通过浏览器的渲染功能来实现该网页的各 ...
- react实战项目开发(2) react几个重要概念以及JSX语法
前言 前面我们已经学习了利用官方脚手架搭建一套可以应用在生产环境下的React开发环境.那么今天这篇文章主要先了解几个react重要的概念,以及讲解本文的重要知识JSX语法 React重要概念 [思想 ...
- ElasticSearch 核心概念
ElasticSearch核心概念-Cluster ElasticSearch核心概念-shards ElasticSearch核心概念-replicas ElasticSearch核心概念-reco ...
- ElasticSearch 全文检索— ElasticSearch 核心概念
ElasticSearch核心概念-Cluster 1)代表一个集群,集群中有多个节点,其中有一个为主节点,这个主节点是可以通过选举产生的,主从节点是对于集群内部来说的.es的一个概念就是去中心化,字 ...
- ELK 学习笔记之 elasticsearch基本概念和CRUD
elasticsearch基本概念和CRUD: 基本概念: CRUD: 创建索引: curl -XPUT 'http://192.168.1.151:9200/library/' -d '{" ...
- Elasticsearch入门教程(二):Elasticsearch核心概念
原文:Elasticsearch入门教程(二):Elasticsearch核心概念 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:ht ...
- 【ElasticSearch】概念
小史是一个非科班的程序员,虽然学的是电子专业,但是通过自己的努力成功通过了面试,现在要开始迎接新生活了. 对小史面试情况感兴趣的同学可以观看面试现场系列. 随着央视诗词大会的热播,小史开始对诗词感兴趣 ...
随机推荐
- 第10.8节 Python包的导入方式详解
一. 包导入与模块导入的关系 由于包本质上是模块,其实对模块的许多导入方法都适用于包,但由于包的结构与模块有差异,所以二者还是有些区别的: 对包的导入,实际上就是包目录下的__init__.py文件的 ...
- 第十六章、Model/View开发:QColumnView的作用及对应Model
老猿Python博文目录 专栏:使用PyQt开发图形界面Python应用 老猿Python博客地址 一.概述 在Qt Designer的Item Views(Model-based)部件中,Colum ...
- 用Python爬取了三大相亲软件评论区,结果...
小三:怎么了小二?一副愁眉苦脸的样子. 小二:唉!这不是快过年了吗,家里又催相亲了 ... 小三:现在不是流行网恋吗,你可以试试相亲软件呀. 小二:这玩意靠谱吗? 小三:我也没用过,你自己看看软件评论 ...
- 乌云wooyun网站硬盘复活
AWD比赛防止没有网络,在移动硬盘里面准备一个乌云漏洞库. 之前也想过弄一个乌云的镜像网站,无奈学生机性能太低下了,部署到公网上服务器存储空间都不够,只能部署在本地硬盘了. 乌云镜像的开源地址:htt ...
- 刷题记录:[GWCTF 2019]枯燥的抽奖
目录 刷题记录:[GWCTF 2019]枯燥的抽奖 知识点 php伪随机性 刷题记录:[GWCTF 2019]枯燥的抽奖 题目复现链接:https://buuoj.cn/challenges 参考链接 ...
- java基础之二:取整函数(Math类)
在日常开发中经常会遇到数字的情况,有关数据的场景中会遇到取整的情况,java中提供了取整函数.看下java.lang.Math类中取整函数的用法. 一.概述 java.lang.Math类中有三个和取 ...
- SASRec 实践
SASRec--2018,ICDM,论文<Self-Attentive Sequential Recommendation> 源代码链接:https://github.com/kang20 ...
- 【题解】「UVA681」Convex Hull Finding
更改了一下程序的错误. Translation 找出凸包,然后逆时针输出每个点,测试数据中没有相邻的边是共线的.多测. Solution 首先推销一下作者的笔记 由此进入>>> ( ...
- 我对js数据类型的理解和深浅(copy)的应用场景
本人毕业一所专科院校,所学专业是计算机应用技术,在大学时对前端有了一定的了解之后,觉得自己对前端的兴趣十分强烈,开始自学前端,一路上也是坎坎坷坷,也有想要放弃的时候,还好坚持了下来,并且从事前端开发已 ...
- 使用MySQL乐观锁解决超卖问题
在秒杀系统设计中,超卖是一个经典.常见的问题,任何商品都会有数量上限,如何避免成功下订单买到商品的人数不超过商品数量的上限,这是每个抢购活动都要面临的难点. 1 超卖问题描述 在多个用户同时发起对同一 ...