ElasticSearch 全文检索— ElasticSearch 核心概念
ElasticSearch核心概念-Cluster
1)代表一个集群,集群中有多个节点,其中有一个为主节点,这个主节点是可以通过选举产生的,主从节点是对于集群内部来说的。es的一个概念就是去中心化,字面上理解就是无中心节点,这是对于集群外部来说的,因为从外部来看es集群,在逻辑上是个整体,你与任何一个节点的通信和与整个es集群通信是等价的。
2)主节点的职责是负责管理集群状态,包括管理分片的状态和副本的状态,以及节点的发现和删除。
3)注意:主节点不负责对数据的增删改查请求进行处理,只负责维护集群的相关状态信息。
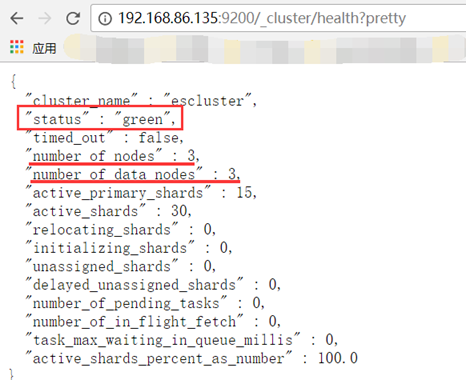
集群状态查看
http://192.168.20.135:9200/_cluster/health?pretty
ElasticSearch核心概念-shards
1)代表索引分片,es可以把一个完整的索引分成多个分片,这样的好处是可以把一个大的索引水平拆分成多个,分布到不同的节点上。构成分布式搜索, 提供性能和吞吐量。
2)分片的数量只能在创建索引库时指定,索引库创建后不能更改。
[hadoop@masternode elasticsearch-2.4.0]$ curl -XPUT 'masternode:9200/zimo3/' -d'{"settings":{"number_of_replicas":2}}'
{"acknowledged":true}
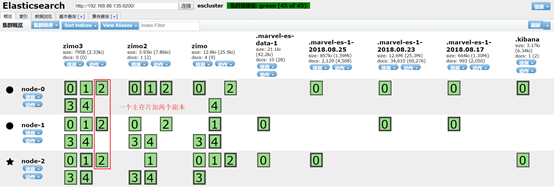
默认是一个索引库有5个分片
每个分片中最多存储2,147,483,519条数据
https://www.elastic.co/guide/en/elasticsearch/reference/2.4/_basic_concepts.html
ElasticSearch核心概念-replicas
代表索引副本,es可以给索引分片设置副本,
副本的作用:
一是提高系统的容错性,当某个节点某个分片损坏或丢失时可以从副本中恢复。
二是提高es的查询效率,es会自动对搜索请求进行负载均衡。
【副本的数量可以随时修改】
可以在创建索引库的时候指定
curl -XPUT 'master:9200/zimo3/' -d'{"settings":{"number_of_replicas":2}}‘
默认是一个分片有1个副本
index.number_of_replicas: 1
也可以修改已有库的副本数目
[hadoop@masternode elasticsearch-2.4.]$ curl -XPUT 'masternode:9200/zimo3/_settings' -d'{"index":{"number_of_replicas":1}}'
{"acknowledged":true}
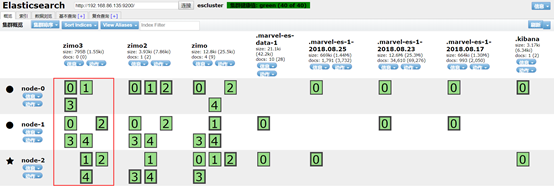
可以看到zimo3的副本数目较上面少了一个。
注意:主分片和副本不会存在一个节点中
ElasticSearch核心概念-recovery
代表数据恢复或叫数据重新分布,es在有节点加入或退出时会根据机器的负载对索引分片进行重新分配,挂掉的节点重新启动时也会进行数据恢复。
ElasticSearch核心概念-gateway
代表es索引的持久化存储方式,es默认是先把索引存放到内存中,当内存满了时再持久化到硬盘。当这个es集群关闭再重新启动时就会从gateway中读取索引数据。es支持多种类型的gateway,有本地文件系统(默认),分布式文件系统,Hadoop的HDFS和Amazon的s3云存储服务。
Hadoop插件安装
bin/plugin install elasticsearch/elasticsearch-repository-hdfs/2.2.
官网安装说明
https://github.com/elastic/elasticsearch-hadoop/tree/master/repository-hdfs https://oss.sonatype.org/content/repositories/snapshots/org/elasticsearch/elasticsearch-repository-hdfs/
Hadoop 插件配置
vi elasticsearch.yml
gateway:
type: hdfs
gateway:
hdfs:
uri: hdfs://localhost:9000
ElasticSearch核心概discovery.zen
代表es的自动发现节点机制,es是一个基于p2p的系统,它先通过广播寻找存在的节点,再通过多播协议来进行节点之间的通信,同时也支持点对点的交互。
如果是不同网段的节点如何组成es集群
禁用自动发现机制
discovery.zen.ping.multicast.enabled: false
设置新节点被启动时能够发现的主节点列表
discovery.zen.ping.unicast.hosts: ["192.168.20.135", "192.168.20.136", "192.168.20.137"]
ElasticSearch核心概Transport
代表es内部节点或集群与客户端的交互方式,默认内部是使用tcp协议进行交互,同时它支持http协议(json格式)、thrift、servlet、memcached、zeroMQ等的传输协议(通过插件方式集成)。
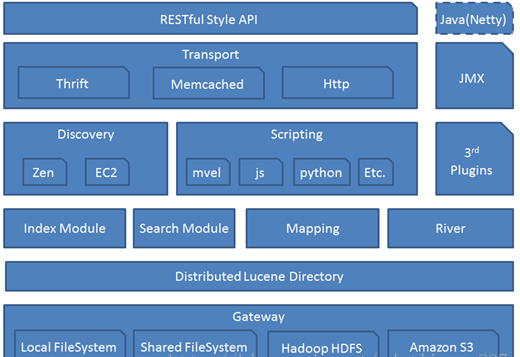
ElasticSearch Setting
settings修改索引库默认配置
https://www.elastic.co/guide/en/elasticsearch/reference/current/indices-create-index.html
例如:分片数量,副本数量
查看:
[hadoop@masternode elasticsearch-2.4.]$ curl -XGET http://masternode:9200/zimo/_settings?pretty
{
"zimo" : {
"settings" : {
"index" : {
"creation_date" : "",
"number_of_shards" : "",
"number_of_replicas" : "",
"uuid" : "oGqP-hgzRGuIxPCssdj3jA",
"version" : {
"created" : ""
}
}
}
}
}
操作不存在索引(创建):
curl -XPUT 'http://master:9200/zimo3/' -d '{"settings":{"number_of_shards":3,"number_of_replicas":2}}'
操作已存在索引(修改):
curl -XPUT 'http://master:9200/zimo3/_settings' -d '{"index":{"number_of_replicas":1}}’
ElasticSearch Mapping
就是对索引库中索引的字段名称及其数据类型进行定义,类似于mysql中的表结构信息。不过es的mapping比数据库灵活很多,它可以动态识别字段。一般不需要指定mapping都可以,因为es会自动根据数据格式识别它的类型,如果你需要对某些字段添加特殊属性(如:定义使用其它分词器、是否分词、是否存储等),就必须手动添加mapping。
https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping.html
查询索引库的mapping信息:
[hadoop@masternode elasticsearch-2.4.]$ curl -XGET http://masternode:9200/zimo/_mapping?pretty
{
"zimo" : {
"mappings" : {
"user" : {
"properties" : {
"age" : {
"type" : "string"
},
"name" : {
"type" : "string"
}
}
}
}
}
}
操作不存在的索引(创建):
[hadoop@masternode elasticsearch-2.4.]$ curl -XPUT 'http://masternode:9200/zimo4' -d'{"mapping":{"user":{"properties":{"name":{"type":"string","analyzer":"ik_max_word"}}}}}'
{"acknowledged":true}
操作已存在的索引(修改):
curl -XPOST http://masternode:9200/zimo4/user/_mapping -d'{"properties":{"name":{"type":"string","analyzer":"ik_max_word"}}}'
更新或者修改已存在mapping遇到的问题
http://stackoverflow.com/questions/38179683/how-to-update-the-mapping-in-elasticsearch-to-change-the-field-datatype-and-chan
以上就是博主为大家介绍的这一板块的主要内容,这都是博主自己的学习过程,希望能给大家带来一定的指导作用,有用的还望大家点个支持,如果对你没用也望包涵,有错误烦请指出。如有期待可关注博主以第一时间获取更新哦,谢谢!
ElasticSearch 全文检索— ElasticSearch 核心概念的更多相关文章
- Elasticsearch之重要核心概念(cluster(集群)、shards(分配)、replicas(索引副本)、recovery(据恢复或叫数据重新分布)、gateway(es索引的持久化存储方式)、discovery.zen(es的自动发现节点机制机制)、Transport(内部节点或集群与客户端的交互方式)、settings(修改索引库默认配置)和mappings)
Elasticsearch之重要核心概念如下: 1.cluster 代表一个集群,集群中有多个节点,其中有一个为主节点,这个主节点是可以通过选举产生的,主从节点是对于集群内部来说的.es的一个概念就是 ...
- ElasticSearch入门及核心概念介绍
Elasticsearch研究有一段时间了,现特将Elasticsearch相关核心知识和原理以初学者的角度记录下来,如有不当,烦请指正! 0. 带着问题上路——ES是如何产生的? (1)思考:大 ...
- ElasticSearch安装和核心概念
1.ElasticSearch安装 elasticsearch的安装超级easy,解压即用(要事先安装好java环境). 到官网 http://www.elasticsearch.org下载最新版的 ...
- ElasticSearch 全文检索— ElasticSearch概述
ElasticSearch 产生背景 1.海量数据组合条件查询 2.毫秒级或者秒级返回数据 Lucene 定义 lucene是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一 ...
- ElasticSearch 全文检索— ElasticSearch 基本操作
REST 简介-定义 REST (REpresentation State Transfer)描述了一个架构样式的网络系统,比如 web 应用程序.它首次出现在 2000 年 Roy Fielding ...
- ElasticSearch 全文检索— ElasticSearch 安装部署
ElasticSearch 规划-集群规划 ElasticSearch 规划-集群规划 ElasticSearch 规划-用户规划 ElasticSearch 规划-目录规划 ElasticSearc ...
- ElasticSearch学习笔记-01 简介、安装、配置与核心概念
一.简介 ElasticSearch是一个基于Lucene构建的开源,分布式,RESTful搜索引擎.设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便.支持通过HTTP使用JSON进 ...
- Elasticsearch笔记四之配置参数与核心概念
在es根目录下有一个config目录,在此目录下有两个文件分别是elasticsearch.yml和logging.yml. logging.yml是日志文件,es也是使用log4j来记录日志的,我在 ...
- 剖析ElasticSearch核心概念,NRT,索引,分片,副本等
ElasticSearch 的核心概念 Near RealTime(NRT) 近实时 近实时有两种意思,一种是从写入数据到可以被搜索到有一个小延迟(大概一秒),还有一种就是基于ElasticSearc ...
随机推荐
- Poj 1936,3302 Subsequence(LCS)
一.Description(3302) Given a string s of length n, a subsequence of it, is defined as another string ...
- 通过gitweb管理Puppet配置(nginx版本+lighttpd版)
Puppet路径为:/etc/puppet 软件版本:gitweb-1.7.1-3.el6_4.1.noarch git-1.7.1-3.el6_4.1.x86_64 fcgi-2.4.0-12.el ...
- Linux统计文件夹占用空间大小--du命令基本用法
命令行环境下要知道linux系统里一个文件夹以及其包含的文件实际所占用的空间大小,linux自带的命令 du可以很好地满足需求. 其他的用法我就不一一写出来了,就列本人觉得会用得最多的,直接上: $ ...
- word2010以上版本中快捷录入数学公式的方法(二)
以前推荐的方法,随着方正飞翔网站上关闭了数学公式输入法的支持也不能不用了,现在再推荐一个可以在word2010以上版中快捷输入数学公式的方法,安装AxMath,一切问题都OK!我是直接购买的正版,25 ...
- #ifdef-#endif的作用及其使用技巧
电脑程序语句,我们可以用它区隔一些与特定头文件.程序库和其他文件版本有关的代码. 1 2 3 #ifdef语句1 //程序2 #endif 可翻译为:如果宏定义了语句1则程序2. 作用:我们可以用它区 ...
- 字符串(String)
字符串是由字符组成的数组,但在JavaScript中字符串是不可变的:可以访问字符串任意位置的文本,但是JavaScript并未提供修改已知字符串内容的方法. 常见功能: obj.length ...
- netstat查看网络信息
Netstat 命令用于显示各种网络相关信息,如网络连接,路由表,接口状态 (Interface Statistics),masquerade 连接,多播成员 (Multicast Membershi ...
- Servlet编程实例 续2
-----------------siwuxie095 Servlet 跳转之请求的重定向 继续完善登录实例,如下: login.jsp 不变,修改 LoginServlet,新建两个 JSP 文件 ...
- JDBC编程之数据查询
----------------siwuxie095 JDBC 编程之数据查询 首先下载 MySQL 的 JDBC 驱动 ...
- console (控制台)
console 模块提供了一个简单的调试控制台,类似于 Web 浏览器提供的 JavaScript 控制台. 该模块导出了两个特定的组件: 一个 Console 类,包含 console.log() ...