Cloudera Manager安装部署
1、连接阿里云服务器
打开远程连接工具进行配置,这里以CRT为例。
1)新建一个session
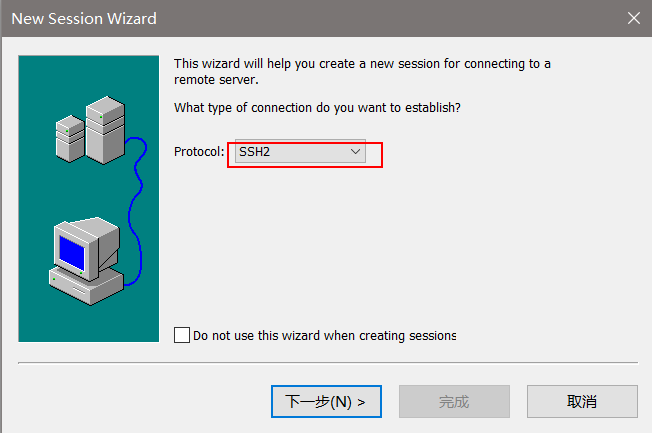
2)填写hostname(填写公网ip)

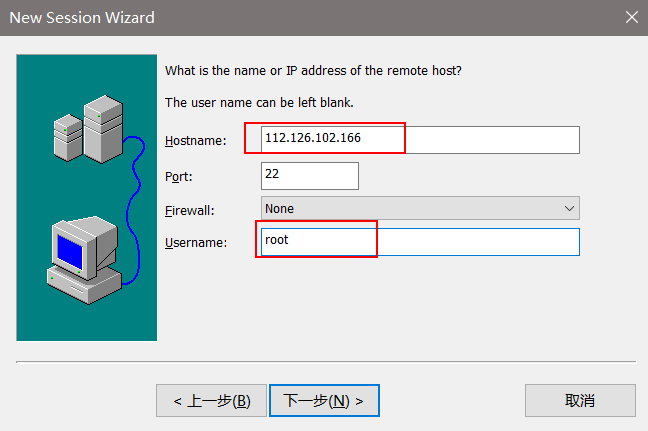
2、修改hosts
[root@hadoop001 ~]# vim /etc/hosts
127.0.0.1 localhost localhost
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
172.17.138.24 hadoop102 hadoop102
172.17.138.25 hadoop103 hadoop103
172.17.138.23 hadoop104 hadoop104
注意:ip填写的是私有ip,做完后ping一下。
3、SSH免密登录
配置hadoop102对hadoop102、hadoop103、hadoop104三台服务器免密登录。CDH服务开启与关闭是通过server和agent来完成的,所以这里不需要配置SSH免密登录,但是为了我们分发文件方便,在这里我们也配置SSH。
1)生成公钥和私钥:
[root@hadoop102 .ssh]$ ssh-keygen -t rsa
然后敲(三个回车),就会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
2)将公钥拷贝到要免密登录的目标机器上
[root@hadoop102 .ssh]$ ssh-copy-id hadoop102
[root@hadoop102 .ssh]$ ssh-copy-id hadoop103
[root@hadoop102 .ssh]$ ssh-copy-id hadoop104
3)重复1和2的操作,配置hadoop103对hadoop102、hadoop103、hadoop104三台服务器免密登录。
4、集群同步脚本
1)在/root目录下创建bin目录,并在bin目录下创建文件xsync,文件内容如下:
#!/bin/bash
#1 获取输入参数个数,如果没有参数,直接退出
pcount=$#
if((pcount==0)); then
echo no args;
exit;
fi #2 获取文件名称
p1=$1
fname=`basename $p1`
echo fname=$fname #3 获取上级目录到绝对路径
pdir=`cd -P $(dirname $p1); pwd`
echo pdir=$pdir #4 获取当前用户名称
user=`whoami` #5 循环
for((host=103; host<105; host++)); do
echo ------------------- hadoop$host --------------
rsync -av $pdir/$fname $user@hadoop$host:$pdir
done
2)修改脚本 xsync 具有执行权限
[root@hadoop102 bin]$ chmod 777 xsync
5、集群整体操作脚本
1)在/root/bin目录下创建脚本xcall.sh
[root@hadoop102 bin]$ vim xcall.sh
2)在脚本中编写如下内容
#! /bin/bash for i in hadoop102 hadoop103 hadoop104
do
echo --------- $i ----------
ssh $i "source /etc/profile ; $*"
done
3)修改脚本执行权限
[root@hadoop102 bin]$ chmod +x xcall.sh
4)测试
[root@hadoop102 bin]# xcall.sh jps
6、关闭防火墙
阿里云的防火墙默认是关闭的,但是他有web防火墙,我们需要将7180,3306,8888,8889,9870等端口开放。
7、关闭SELINUX(阿里云环境可跳过)
安全增强型Linux(Security-Enhanced Linux)简称SELinux,它是一个 Linux 内核模块,也是Linux的一个安全子系统。为了避免安装过程出现各种错误,建议关闭,有如下两种关闭方法:
1)临时关闭(不建议使用)
[root@hadoop102 ~]# setenforce 0
但是这种方式只对当次启动有效,重启机器后会失效。
2)永久关闭(建议使用)
修改配置文件/etc/selinux/config
[root@hadoop102 ~]# vim /etc/selinux/config
将SELINUX=enforcing 改为SELINUX=disabled
SELINUX=disabled
3)同步/etc/selinux/config配置文件
[root@hadoop102 ~]# xsync /etc/selinux/config
4)重启hadoop102、hadoop103、hadoop104主机
[root@hadoop102 ~]# reboot
[root@hadoop103 ~]# reboot
[root@hadoop104 ~]# reboot
8、配置NTP时钟同步(阿里云环境可跳过)
1)NTP服务器配置
1)NTP服务器配置
[root@hadoop102 ~]# vi /etc/ntp.conf
①注释掉所有的restrict开头的配置
②修改#restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap
为restrict 192.168.1.102 mask 255.255.255.0 nomodify notrap
③将所有server配置进行注释
④添加下面两行内容
server 127.127.1.0
fudge 127.127.1.0 stratum 10
2)启动NTP服务 service ntpd start
[root@hadoop102 ~]# service ntpd start
3)NTP客户端配置(在agent主机上进行配置hadoop103,hadoop104)
[root@hadoop103 ~]# vi /etc/ntp.conf ①注释所有restrict和server配置
②添加server 192.168.1.102
4)手动测试
[root@hadoop103~]# ntpdate 192.168.1.102
显示如下内容为成功:
17 Jun 15:34:38 ntpdate[9247]: step time server 192.168.1.102 offset 77556618.173854 sec
如果显示如下内容需要先关闭ntpd:
17 Jun 15:25:42 ntpdate[8885]: the NTP socket is in use, exiting
5)启动ntpd并设置为开机自启(每个节点hadoop102,hadoop103,hadoop104)
[root@hadoop103 ~]# chkconfig ntpd on
[root@hadoop103 ~]# service ntpd start
6)使用群发date命令查看结果
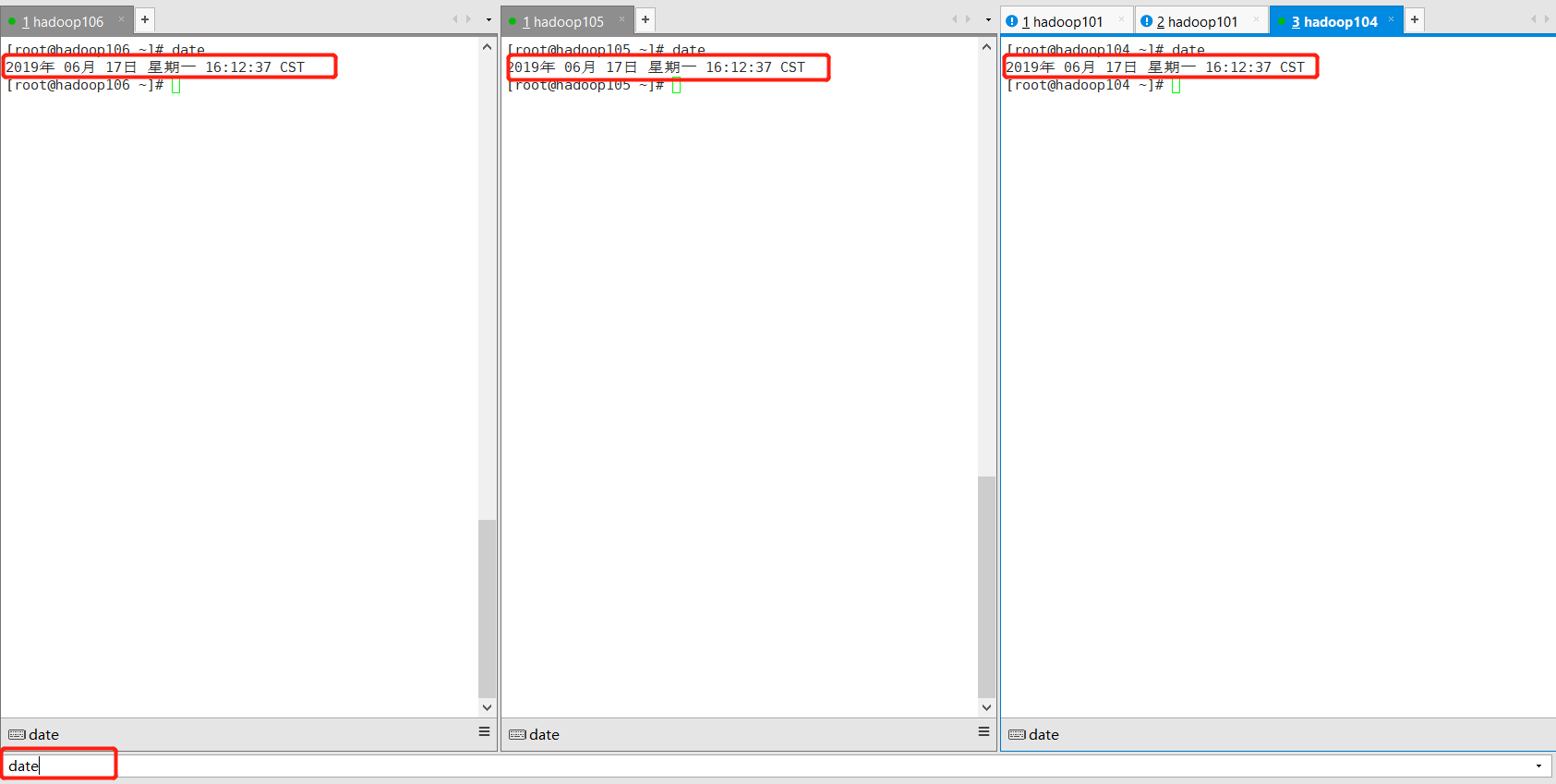
9、安装jdk
1)在hadoop102创建/usr/java目录
[root@hadoop102 opt]# mkdir /usr/java
2)用SecureCRT将jdk-8u144-linux-x64.tar.gz上传至hadoop102,并解压到/usr/java目录下。
[root@hadoop102 ~]# tar -zxvf jdk-8u144-linux-x64.tar.gz -C /usr/java/
3)配置JAVA_HOME环境变量
(1)打开/etc/profile文件
[root@hadoop102 software]$ vim /etc/profile
在profile文件末尾添加JDK路径
#JAVA_HOME
export JAVA_HOME=/usr/java/jdk1.8.0_144
export PATH=$PATH:$JAVA_HOME/bin
(2)让修改后的文件生效
[root@hadoop102 jdk1.8.0_144]$ source /etc/profile
4)测试JDK是否安装成功
[root@hadoop102 jdk1.8.0_144]# java -version
java version "1.8.0_144"
5)将hadoop102中的JDK和环境变量分发到hadoop103、hadoop104两台主机
[root@hadoop102 opt]# xsync /usr/java/
[root@hadoop102 opt]# xsync /etc/profile
分别在hadoop103、hadoop104上source一下
[root@hadoop103 ~]$ source /etc/profile
[root@hadoop104 ~]# source /etc/profile
10、安装MySQL及其驱动(hadoop102上操作)
1)卸载mariadb
rpm -qa | grep mariadb | xargs rpm -e --nodeps
2)下载msql5.7 yum源
wget https://dev.mysql.com/get/mysql57-community-release-el7-9.noarch.rpm
3)安装yum源
rpm -ivh mysql57-community-release-el7-9.noarch.rpm
4)安装mysql
yum -y install mysql-server
5)启动mysql
service mysqld start
6)查看root用户密码
grep 'temporary password' /var/log/mysqld.log d9V,K1..6e.Q
7)执行mysql初始化脚本
mysql_secure_installation
8)输入新密码(至少12个字符,至少包含一个大写字母有,一个小写字母,一个数字,一个特殊字符)

9)配置root用户远程访问权限
mysql> grant all privileges on *.* to 'root' @'%' identified by 'Atguigu.123456';
mysql> flush privileges;
10)为CM安装mysql驱动
(1)将mysql-connector-java-5.1.27-bin.jar拷贝到/usr/share/java路径下,并重命名
[root@hadoop102 java]# mv mysql-connector-java-5.1.27-bin.jar mysql-connector-java.jar
(2)分发驱动
xsync /usr/share/java
11、CM安装
Cloudera Manager默认采用yum安装,对于能够联网的用户,可直接在线安装,十分快捷方便。对于网络不畅的用户,则可搭建本地yum源,进行安装。
1)集群规划
|
节点 |
hadoop102 |
hadoop103 |
hadoop104 |
|
服务 |
cloudera-scm-server cloudera-scm-agent |
cloudera-scm-agent |
cloudera-scm-agent |
2)下载在线yum源配置文件(在线yum安装)
cd /etc/yum.repos.d
wget https://archive.cloudera.com/cm6/6.2.1/redhat7/yum/cloudera-manager.repo
3)分发在线yum源配置文件(在线yum安装)
xsync /etc/yum.repos.d/cloudera-manager.repo
4)搭建本地yum源(离线yum安装)(若网络环境畅通,此步可直接跳过)
(1)将压缩包cloudera-repos.tar.gz拷贝到集群中的一台节点,解压到/var/www/html路径下
[root@hadoop102 ~]# tar -zxvf cloudera-repos.tar.gz -C /var/www/html
(2)进入/var/www/html/路径,并开启http服务
[root@hadoop102 ~]# cd /var/www/html/
[root@hadoop102 html]# python -m SimpleHTTPServer 8900
(3)浏览器访问该节点的8900端口,查看http服务是否正常开启
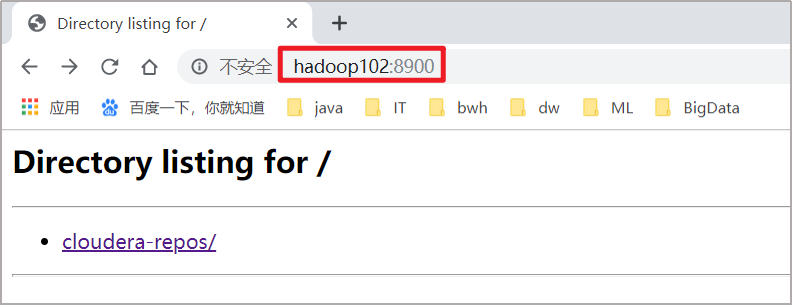
(4)编辑本地yum源配置文件
vim /etc/yum.repos.d/cloudera-manager.repo
文件内容如下
[cloudera-manager]
name=cloudera-manager
baseurl=http://hadoop102:8900/cloudera-repos/cm6/6.2.1/redhat7/yum/
enabled=1
gpgcheck=0
(5)分发该配置文件
xsync /etc/yum.repos.d/cloudera-manager.repo
4)安装CM server及agent
[root@hadoop102 ~]# yum -y install cloudera-manager-daemons cloudera-manager-agent cloudera-manager-server
[root@hadoop103 ~]# yum -y install cloudera-manager-agent cloudera-manager-daemons
[root@hadoop104 ~]# yum -y install cloudera-manager-agent cloudera-manager-daemons
12、修改CM配置文件(三台,不要用xsync同步)
vim /etc/cloudera-scm-agent/config.ini
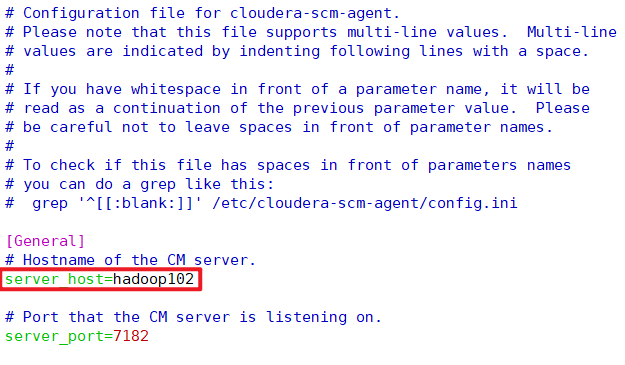
13、在MySQL中建库
1)创建各组件需要的数据库
mysql> CREATE DATABASE scm DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
mysql> CREATE DATABASE amon DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
mysql> CREATE DATABASE hue DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
mysql> CREATE DATABASE hive DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
mysql> CREATE DATABASE sentry DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
mysql> CREATE DATABASE oozie DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
2)为CM配置数据库(自带脚本)
/opt/cloudera/cm/schema/scm_prepare_database.sh mysql scm root Atguigu.123456
14、启动CM服务
1)启动服务节点:hadoop102
[root@hadoop102 ~]# systemctl start cloudera-scm-server
2)启动工作节点:hadoop102、hadoop103、hadoop104
[root@hadoop102 ~]# systemctl start cloudera-scm-agent
[root@hadoop103 ~]# systemctl start cloudera-scm-agent
[root@hadoop104 ~]# systemctl start cloudera-scm-agent
3)查看Server启动日志
[root@hadoop102 cm]# tail -f /var/log/cloudera-scm-server/cloudera-scm-server.log

出现Started Jetty server字样及表明启动成功。
4)访问http://hadoop102:7180(初始用户名、密码均为admin)
15、关闭CM服务
1)关闭工作节点:hadoop102、hadoop103、hadoop104
[root@hadoop102 ~]# systemctl stop cloudera-scm-agent
[root@hadoop103 ~]# systemctl stop cloudera-scm-agent
[root@hadoop104 ~]# systemctl stop cloudera-scm-agent
2)关闭服务节点:hadoop102
[root@hadoop102 ~]# systemctl stop cloudera-scm-server
Cloudera Manager安装部署的更多相关文章
- Cloudera Manager安装_搭建CDH集群
2017年2月22日, 星期三 Cloudera Manager安装_搭建CDH集群 cpu 内存16G 内存12G 内存8G 默认单核单线 CDH1_node9 Server || Agent ...
- Cloudera Manager安装之利用parcels方式安装3或4节点集群(包含最新稳定版本或指定版本的安装)(添加服务)(CentOS6.5)(五)
参考博客 Cloudera Manager安装之利用parcels方式安装单节点集群 Cloudera Manager安装之Cloudera Manager 5.3.X安装(三)(tar方式.rpm ...
- Cloudera Manager安装之利用parcels方式安装单节点集群(包含最新稳定版本或指定版本的安装)(添加服务)(CentOS6.5)(四)
不多说,直接上干货! 福利 => 每天都推送 欢迎大家,关注微信扫码并加入我的4个微信公众号: 大数据躺过的坑 Java从入门到架构师 人工智能躺过的坑 ...
- Cloudera Manager安装之Cloudera Manager 5.3.X安装(三)(tar方式、rpm方式和yum方式)
不多说,直接上干货! 福利每天都有 => =>=>=>=> 欢迎大家,关注微信扫码并加入我的4个微信公众号: 大数据躺过的坑 Java从入门到架构师 ...
- Cloudera Manager安装之Cloudera Manager安装前准备(CentOS6.5)(一)
Cloudera Manager安装前准备 (一)机器准备 192.168.80.148 clouderamanager01 (部署ClouderaManager-server和Mirror se ...
- Cloudera Manager安装之利用parcels方式(在线或离线)安装3或4节点集群(包含最新稳定版本或指定版本的安装)(添加服务)(Ubuntu14.04)(五)
前期博客 Cloudera Manager安装之Cloudera Manager 5.6.X安装(tar方式.rpm方式和yum方式) (Ubuntu14.04) (三) 如果大家,在启动的时候,比如 ...
- Cloudera Manager安装之Cloudera Manager安装前准备(Ubuntu14.04)(一)
其实,基本思路跟如下差不多,我就不多详细说了,贴出主要图. 博主,我是直接借鉴下面这位博主,来进行安装的!(灰常感谢他们!) 在线和离线安装Cloudera CDH 5.6.0 Cloudera M ...
- Cloudera Manager 安装集群遇到的坑
Cloudera Manager 安装集群遇到的坑 多次安装集群,但每次都不能顺利,都会遇到很多很多的坑,今天就过去踩过的坑简单的总结一下,希望已经踩了的和正在踩的童鞋能够借鉴一下,希望对你们能有所帮 ...
- Cloudera Manager安装之时间服务器和时间客户端(二)
福利 => 每天都推送 欢迎大家,关注微信扫码并加入我的4个微信公众号: 大数据躺过的坑 Java从入门到架构师 人工智能躺过的坑 Java全栈大联盟 ...
随机推荐
- Hive表的基本操作
目录 1. 创建表 2. 拷贝表 3. 查看表结构 4. 删除表 5. 修改表 5.1 表重命名 5.2 增.修.删分区 5.3 修改列信息 5.4 增加列 5.5 删除列 5.6 修改表的属性 1. ...
- #1使用html+css+js制作网站教程 准备
#1使用html+css+js制作网站教程 准备 本系列链接 0 准备 0.1 IDE编辑软件 0.2 浏览器 0.3 基础概念 0.3.1 html 0.3.2 css 0.3.3 js 0.4 文 ...
- Dubbo 就是靠它崭露头角!(身为开源框架很重要的一点)
Hola,我是 yes. 经过了 RPC 核心和 Dubbo 微内核两篇文章后,今天终于要稍稍深入一波 Dubbo 了. 作为一个通用的 RPC 框架,性能是很重要的一环,而易用性和扩展性也极为重要. ...
- 剑指offer 查找和排序的基本操作:查找排序算法大集合
重点 查找算法着重掌握:顺序查找.二分查找.哈希表查找.二叉排序树查找. 排序算法着重掌握:冒泡排序.插入排序.归并排序.快速排序. 顺序查找 算法说明 顺序查找适合于存储结构为顺序存储或链接存储的线 ...
- 【Web】实现动态文章列表
简单记录 -慕课网- 步骤二:动态文章列表效果 实现这个 一个网页中常见的文章列表效果. 怎么实现文章列表案例 分解一波,CSS来改变样式 标题标签 HTML的无序列表 去掉项目符号 符号所占空间 列 ...
- 【高级排序算法】2、归并排序法的实现-Merge Sort
简单记录 - bobo老师的玩转算法系列–玩转算法 -高级排序算法 Merge Sort 归并排序 Java实现归并排序 SortTestHelper 排序测试辅助类 package algo; im ...
- 更改mysql的密码
mysql> set password for 'root'@'localhost' =PASSWORD('');Query OK, 0 rows affected (0.17 sec) mys ...
- 【Oracle】增量备份和全库备份怎么恢复数据库
1差异增量实验示例 1.1差异增量备份 为了演示增量备份的效果,我们在执行一次0级别的备份后,对数据库进行一些改变. 再执行一次1级别的差异增量备份: 执行完1级别的备份后再次对数据库进行更改: 再执 ...
- 【老孟Flutter】源码分析系列之InheritedWidget
老孟导读:这是2021年源码系列的第一篇文章,其实源码系列的文章不是特别受欢迎,一个原因是原理性的知识非常枯燥,我自己看源码的时候特别有感触,二是想把源码分析讲的通俗易懂非常困难,自己明白 和 让别人 ...
- python7、8章
目录 第七章 用户输入和while循环 7.1 函数input()的工作原理 7.1.1 编写清晰的程序 7.1.2 使用int()来获取数值输入 分析: 结果: 7.1.3 求模运算符 7.1.4 ...