Kaggle-pandas(4)
Grouping-and-sorting
教程
映射使我们可以一次将整个列中的数据转换为DataFrame或Series中的一个值。 但是,通常我们希望对数据进行分组,然后对数据所在的组进行特定的操作。
正如您将学到的,我们使用groupby()操作来完成此操作。 我们还将介绍一些其他主题,例如为DataFrames编制索引的更复杂方法以及如何对数据进行排序。
Groupwise analysis
到目前为止,我们一直在使用的一个函数是value_counts()函数。 我们可以通过执行以下操作来复制value_counts()的功能:
reviews.groupby('points').points.count()
groupby()创建了一组reviews,这些reviews为给定的葡萄酒分配了相同的分值。 然后,对于每个组,我们都抓住了points()列并计算了它出现的次数。 value_counts()只是该groupby()操作的快捷方式。
我们可以将之前使用的任何汇总功能与此数据一起使用。 例如,要获取每个点值类别中最便宜的葡萄酒,我们可以执行以下操作:
reviews.groupby('points').price.min()
您可以将我们生成的每个组视为DataFrame的一部分,其中仅包含具有匹配值的数据。 我们可以使用apply()方法直接访问此DataFrame,然后我们可以按照自己认为合适的任何方式来操作数据。 例如,这是一种从数据集中的每个酿酒厂中选择第一批葡萄酒名称的方法:
reviews.groupby('winery').apply(lambda df: df.title.iloc[0])
为了获得更细粒度的控制,您还可以按多个列进行分组。 例如,以下是我们如何按国家和省份挑选最佳葡萄酒的方法:
reviews.groupby(['country', 'province']).apply(lambda df: df.loc[df.points.idxmax()])
分类结果如下

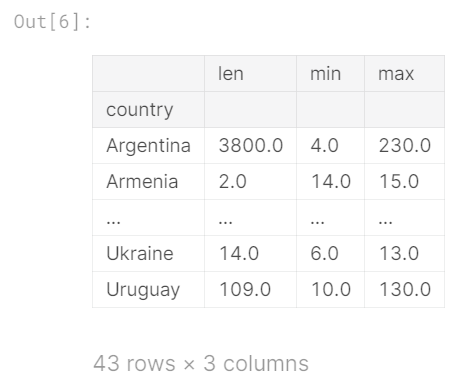
另一个值得一提的groupby()方法是agg(),它使您可以同时在DataFrame上运行许多不同的函数。 例如,我们可以生成数据集的简单统计摘要,如下所示:
reviews.groupby(['country']).price.agg([len, min, max])
Multi-indexes
到目前为止,在所有示例中,我们一直在使用带有单标签索引的DataFrame或Series对象。 groupby()稍有不同,因为它取决于我们运行的操作,有时会导致所谓的多索引。
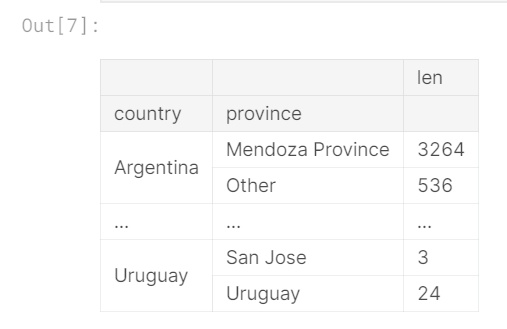
多索引与常规索引的不同之处在于它具有多个级别。 例如:
countries_reviewed = reviews.groupby(['country', 'province']).description.agg([len])
countries_reviewed
mi = countries_reviewed.index
type(mi)
Output:
pandas.core.indexes.multi.MultiIndex
多索引有几种方法来处理它们的分层结构,而单级索引则没有。 它们还需要两个级别的标签才能检索值。 对于刚接触pandas的用户来说,处理多索引输出是常见的“陷阱”。
pandas文档的“多索引/高级选择”部分中详细说明了多索引的使用案例以及使用说明。
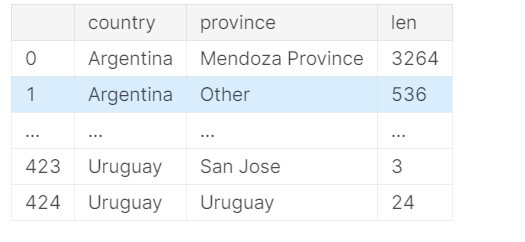
但是,通常,您最常使用的多索引方法是一种可转换回常规索引的方法,即reset_index()方法:
Sorting
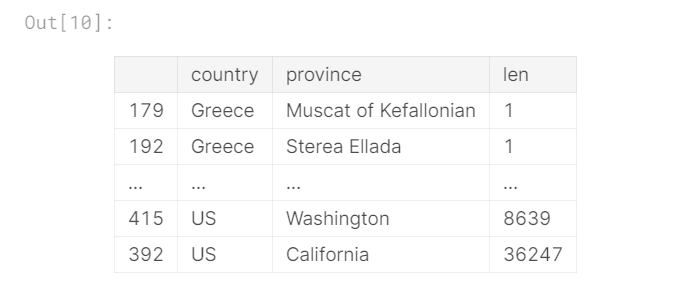
再次查看countries_reviewed,我们可以看到分组以索引顺序而不是以值顺序返回数据。 也就是说,在输出groupby的结果时,行的顺序取决于索引中的值,而不取决于数据中的值。
要按需要的顺序获取数据,我们可以自己对其进行排序。 sort_values()方法很方便。
countries_reviewed = countries_reviewed.reset_index()
countries_reviewed.sort_values(by='len')
Output:
要按索引值排序,请使用配套方法sort_index()。 此方法具有相同的参数和默认顺序:
countries_reviewed.sort_index()
Output:
练习
1
Who are the most common wine reviewers in the dataset? Create a Series whose index is the taster_twitter_handle category from the dataset, and whose values count how many reviews each person wrote.
# Your code here
reviews_written = reviews.groupby("taster_twitter_handle").taster_twitter_handle.count()
print(reviews_written) # Check your answer
q1.check()
2.
What is the best wine I can buy for a given amount of money? Create a Series whose index is wine prices and whose values is the maximum number of points a wine costing that much was given in a review. Sort the values by price, ascending (so that 4.0 dollars is at the top and 3300.0 dollars is at the bottom).
best_rating_per_price = reviews.groupby('price')['points'].max().sort_index()
# Check your answer
q2.check()
3.
What are the minimum and maximum prices for each variety of wine? Create a DataFrame whose index is the variety category from the dataset and whose values are the min and max values thereof.
price_extremes = reviews.groupby('variety')["price"].agg([min,max])
# Check your answer
q3.check()
4.
What are the most expensive wine varieties? Create a variable sorted_varieties containing a copy of the dataframe from the previous question where varieties are sorted in descending order based on minimum price, then on maximum price (to break ties).
sorted_varieties = price_extremes.sort_values(by=['min', 'max'], ascending=False)
# Check your answer
q4.check()
5.
Create a Series whose index is reviewers and whose values is the average review score given out by that reviewer. Hint: you will need the taster_name and points columns.
reviewer_mean_ratings = reviews.groupby('taster_name').points.mean()
# Check your answer
q5.check()
6.
What combination of countries and varieties are most common? Create a Series whose index is a MultiIndexof {country, variety} pairs. For example, a pinot noir produced in the US should map to {"US", "Pinot Noir"}. Sort the values in the Series in descending order based on wine count.
country_variety_counts = reviews.groupby(['country', 'variety']).size().sort_values(ascending=False) # Check your answer
q6.check()
Kaggle-pandas(4)的更多相关文章
- 由Kaggle竞赛wiki文章流量预测引发的pandas内存优化过程分享
pandas内存优化分享 缘由 最近在做Kaggle上的wiki文章流量预测项目,这里由于个人电脑配置问题,我一直都是用的Kaggle的kernel,但是我们知道kernel的内存限制是16G,如下: ...
- kaggle入门2——改进特征
1:改进我们的特征 在上一个任务中,我们完成了我们在Kaggle上一个机器学习比赛的第一个比赛提交泰坦尼克号:灾难中的机器学习. 可是我们提交的分数并不是非常高.有三种主要的方法可以让我们能够提高他: ...
- Kaggle入门教程
此为中文翻译版 1:竞赛 我们将学习如何为Kaggle竞赛生成一个提交答案(submisson).Kaggle是一个你通过完成算法和全世界机器学习从业者进行竞赛的网站.如果你的算法精度是给出数据集中最 ...
- 如何使用Python在Kaggle竞赛中成为Top15
如何使用Python在Kaggle竞赛中成为Top15 Kaggle比赛是一个学习数据科学和投资时间的非常的方式,我自己通过Kaggle学习到了很多数据科学的概念和思想,在我学习编程之后的几个月就开始 ...
- kaggle数据挖掘竞赛初步--Titanic<原始数据分析&缺失值处理>
Titanic是kaggle上的一道just for fun的题,没有奖金,但是数据整洁,拿来练手最好不过啦. 这道题给的数据是泰坦尼克号上的乘客的信息,预测乘客是否幸存.这是个二元分类的机器学习问题 ...
- kaggle& titanic代码
这两天报名参加了阿里天池的’公交线路客流预测‘赛,就顺便先把以前看的kaggle的titanic的训练赛代码在熟悉下数据的一些处理.题目根据titanic乘客的信息来预测乘客的生还情况.给了titan ...
- 初窥Kaggle竞赛
初窥Kaggle竞赛 原文地址: https://www.dataquest.io/mission/74/getting-started-with-kaggle 1: Kaggle竞赛 我们接下来将要 ...
- 逻辑回归应用之Kaggle泰坦尼克之灾(转)
正文:14pt 代码:15px 1 初探数据 先看看我们的数据,长什么样吧.在Data下我们train.csv和test.csv两个文件,分别存着官方给的训练和测试数据. import pandas ...
- kaggle之Grupo Bimbo Inventory Demand
Grupo Bimbo Inventory Demand kaggle比赛解决方案集合 Grupo Bimbo Inventory Demand 在这个比赛中,我们需要预测某个产品在某个销售点每周的需 ...
- kaggle之人脸特征识别
Facial_Keypoints_Detection github code facial-keypoints-detection, 这是一个人脸识别任务,任务是识别人脸图片中的眼睛.鼻子.嘴的位置. ...
随机推荐
- day45 如何完全删除mysql服务
卸载mysql之后,mysql的服务无法删除 解决方案 在我们在卸载mysql后会有一些东西没有删除干净,当我们把这些内容清除干净后,服务自然就消失了 步骤一: 如果是默认安装的话 在这三个文件内都有 ...
- 浏览器如何解析css选择器?
浏览器会『从右往左』解析CSS选择器. 我们知道DOM Tree与Style Rules合成为 Render Tree,实际上是需要将Style Rules附着到DOM Tree上, 因此需要根据选择 ...
- devtools 判断类数组的方法
var obj = { '2': 3, '3': 4, 'length': 2, 'splice': Array.prototype.splice, 'push': Array.prototype.p ...
- 阻止 iPhone 视频自动全屏
最近一年都在做直播,遭video 全屏的问题困扰了很久.下面将阻止 ios视频自动全屏的办法写出来.添加 playsinline 和 webkit-playsinline="true&quo ...
- LINQ多表查询
#region Group,Join //只有join,没有into,内联(inner join) //var sql = from c in sdb.Classic // join s in sdb ...
- 5分钟带你快速入门和了解 OAM Kubernetes
什么是 OAM? OAM 的全称为开放应用模型(Open Application Model),由阿里巴巴宣布联合微软共同推出. OAM 解决了什么问题? OAM 本质是为了解耦K8S中现存的形形色色 ...
- Redis如何存储和计算一亿用户的活跃度
1 前段时间,在网上看到一道面试题: 如何用redis存储统计1亿用户一年的登陆情况,并快速检索任意时间窗口内的活跃用户数量. 觉得很有意思,就仔细想了下 .并做了一系列实验,自己模拟了下 .还是有点 ...
- 6.ALOHA协议
动态媒体接入控制/多点接入特点:信道并非在用户通信时固定分配给用户. 一.纯ALOHA协议 纯 ALOHA协议思想:不监听信道,不按时间槽发送,随机重发.想发就发 二.时隙ALOHA协议 时隙 ALO ...
- PyQt5绘图
QPainter 功能:QPainter实现在QWidget上画图功能 说明:绘图必须在paintEvent中完成,且要在bengin和end之间作图 接口: 方法 描述 begin 开始画图 end ...
- 设计模式:bridge模式
目的:将“类的功能层次结构”和“类的实现层次结构”分类 类的功能层次:通过类的继承添加功能(添加普通函数) 类的实现层次:通过类的继承实现虚函数 理解:和适配器模式中的桥接方法相同 例子: class ...