分类模型的F1-score、Precision和Recall 计算过程
分类模型的F1分值、Precision和Recall 计算过程
引入
通常,我们在评价classifier的性能时使用的是accuracy
考虑在多类分类的背景下
accuracy = (分类正确的样本个数) / (分类的所有样本个数)
这样做其实看上去也挺不错的,不过可能会出现一个很严重的问题:例如某一个不透明的袋子里面装了1000台手机,其中有600台iphone6, 300台galaxy s6, 50台华为mate7,50台mx4(当然,这些信息分类器是不知道的。。。)。如果分类器只是简单的把所有的手机都预测为iphone6, 那么通过上面的公式计算的准确率accuracy为0.6,看起来还不错;可是三星,华为和小米的全部预测错了。如果再给一个袋子,里面装着600台galaxy s6, 300台mx4, 50台华为mate7,50台iphone,那这个分类器立马就爆炸了,连回家带孩子的要求都达不到
所以,仅仅用accuracy来衡量一个分类器的性能是很不科学的。因此要引入其他的衡量标准。
二分类
是不是经常看见如下类似的图?这是二分类的图,假设只有正类和负类,True和False分别表示对和错;Positive和Negative分别表示预测为正类和负类。

那么
- TP:预测为Positive并且对了(样本为正类且预测为正类)
- TN:预测为Negative并且对了(样本为负类且预测为负类)
- FP:预测为Positive但错了(样本为负类但预测为正类)
- FN:预测为Negative但错了(样本为正类但预测为负类)
- TP+FP:预测为Positive并且对了+预测为Positive但错了=预测为Positive的样本总数
- TP+FN:预测为Positive并且对了+预测为Negative但错了=实际为Positive的样本总数
所以precision就表示:被正确预测的Positive样本 / 被预测为Positive的样本总数
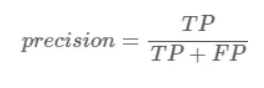
同理,recall就表示:被正确预测的Positive样本 / 实际为Positive的样本总数
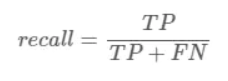
F1是调和平均值,精准率和召回率只要有一个比较小的话,F1的值也会被拉下来:

多分类情况
其实和二分类情况很类似,例子如下 这个是Micro , 和二分类类似 (将例子中的precision和recall代入到F1公式中,得到的就是Micro下的F1值)

而Macro情况下计算F1需要先计算出每个类别的F1值,然后求平均值。如下

Macro情况下上述例子的计算

sklearn计算程序(macro)
下面是使用sklearn直接计算多类别F1/P/R的程序,将接口中的average参数配置为’macro’即可。
from sklearn.metrics import f1_score, precision_score, recall_score
y_true=[1,2,3]
y_pred=[1,1,3]
f1 = f1_score( y_true, y_pred, average='macro' )
p = precision_score(y_true, y_pred, average='macro')
r = recall_score(y_true, y_pred, average='macro')
print(f1, p, r)
# output: 0.555555555556 0.5 0.666666666667
参考链接:
https://blog.csdn.net/ybdesire/article/details/96507733
https://www.jianshu.com/p/14b26f59040b
分类模型的F1-score、Precision和Recall 计算过程的更多相关文章
- 机器学习:评价分类结果(F1 Score)
一.基础 疑问1:具体使用算法时,怎么通过精准率和召回率判断算法优劣? 根据具体使用场景而定: 例1:股票预测,未来该股票是升还是降?业务要求更精准的找到能够上升的股票:此情况下,模型精准率越高越优. ...
- 【tf.keras】实现 F1 score、precision、recall 等 metric
tf.keras.metric 里面竟然没有实现 F1 score.recall.precision 等指标,一开始觉得真不可思议.但这是有原因的,这些指标在 batch-wise 上计算都没有意义, ...
- 机器学习--如何理解Accuracy, Precision, Recall, F1 score
当我们在谈论一个模型好坏的时候,我们常常会听到准确率(Accuracy)这个词,我们也会听到"如何才能使模型的Accurcy更高".那么是不是准确率最高的模型就一定是最好的模型? 这篇博文会向大家解释 ...
- 【笔记】F1 score
F1 score 关于精准率和召回率 精准率和召回率可以很好的评价对于数据极度偏斜的二分类问题的算法,有个问题,毕竟是两个指标,有的时候这两个指标也会产生差异,对于不同的算法,精准率可能高一些,召回率 ...
- 机器学习中的 precision、recall、accuracy、F1 Score
1. 四个概念定义:TP.FP.TN.FN 先看四个概念定义: - TP,True Positive - FP,False Positive - TN,True Negative - FN,False ...
- 利用sklearn对MNIST手写数据集开始一个简单的二分类判别器项目(在这个过程中学习关于模型性能的评价指标,如accuracy,precision,recall,混淆矩阵)
.caret, .dropup > .btn > .caret { border-top-color: #000 !important; } .label { border: 1px so ...
- 分类问题的几个评价指标(Precision、Recall、F1-Score、Micro-F1、Macro-F1
轉自 https://blog.csdn.net/sinat_28576553/article/details/80258619 四个基本概念TP.True Positive 真阳性:预测为正,实 ...
- ROC,AUC,Precision,Recall,F1的介绍与计算(转)
1. 基本概念 1.1 ROC与AUC ROC曲线和AUC常被用来评价一个二值分类器(binary classifier)的优劣,ROC曲线称为受试者工作特征曲线 (receiver operatin ...
- ROC,AUC,Precision,Recall,F1的介绍与计算
1. 基本概念 1.1 ROC与AUC ROC曲线和AUC常被用来评价一个二值分类器(binary classifier)的优劣,ROC曲线称为受试者工作特征曲线 (receiver operatin ...
随机推荐
- CentOS7.7 安装并配置JDK 1.8
本文介绍如何在CentOS中安装oracleJDK1.8并配置环境变量 1.下载并安装jdk1.8 进入下载页:https://www.oracle.com/technetwork/java/java ...
- XSS与CSRF定义
一. CSRF 1. CSRF的基本概念 跨站请求伪造(英语:Cross-site request forgery),也被称为 one-click attack 或者 session riding,通 ...
- python 装饰器(七):装饰器实例(四)类装饰器装饰类以及类方法
类装饰器装饰类方法 不带参数 from functools import wraps import types class CatchException: def __init__(self,orig ...
- Ethical Hacking - Web Penetration Testing(11)
SQL INJECTION Preventing SQLi Filters can be bypassed. Use a blacklist of commands? Still can be byp ...
- 服务注册与发现【Eureka】- Eureka简介
什么是服务治理 SpringCloud 封装了 Netflix 公司开发的 Eureka 模块来 实现服务治理. 在传统的rpc远程调用框架中,管理每个服务与服务之间依赖关系比较复杂,管理比较复杂,所 ...
- javascript : 递归遍历数组
我们假设有一个对象数组. 这个对象数组里的对象,有一个叫children的key,value也是一个对象数组. 这个数组里面可能还有children... 现在我们想递归遍历它. 上代码. test_ ...
- 利用Serverless应用搭建Hexo博客
本文将介绍如何使用火爆的Serverless应用,15分钟快速搭建Hexo博客.以腾讯云提供的Serverless应用–云开发为例: 步骤1:安装 CloudBase CLI 以及本地部署 Hexo ...
- APP自动化 -- 坐标获取和点击
一.获取元素坐标 二.点击坐标 1.driver的点击(这个可以实现多点同时点击) 1)执行 这个coordinate变量必须是一个list coordinate_list = [(0, 0), (1 ...
- Java基础之java8新特性(1)Lambda
一.接口的默认方法.static方法.default方法. 1.接口的默认方法 在Java8之前,Java中接口里面的默认方法都是public abstract 修饰的抽象方法,抽象方法并没有方法实体 ...
- liunx安装和部署nacos配置中心
1.下载https://github.com/alibaba/nacos/releases nacos-server-1.3.1.tar.gz 源码包2.上传到liunx服务器 /usr/lo ...