Hadoop基础(二):从Hadoop框架讨论大数据生态
1 Hadoop是什么
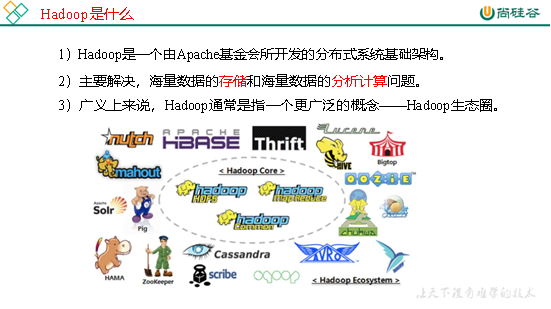
2 Hadoop三大发行版本
Hadoop三大发行版本:Apache、Cloudera、Hortonworks。
Apache版本最原始(最基础)的版本,对于入门学习最好。
Cloudera在大型互联网企业中用的较多。
Hortonworks文档较好。
- Apache Hadoop
官网地址:http://hadoop.apache.org/releases.html
下载地址:https://archive.apache.org/dist/hadoop/common/
- Cloudera Hadoop
官网地址:https://www.cloudera.com/downloads/cdh/5-10-0.html
下载地址:http://archive-primary.cloudera.com/cdh5/cdh/5/
(1)2008年成立的Cloudera是最早将Hadoop商用的公司,为合作伙伴提供Hadoop的商用解决方案,主要是包括支持、咨询服务、培训。
(2)2009年Hadoop的创始人Doug Cutting也加盟Cloudera公司。Cloudera产品主要为CDH,Cloudera Manager,Cloudera Support
(3)CDH是Cloudera的Hadoop发行版,完全开源,比Apache Hadoop在兼容性,安全性,稳定性上有所增强。
(4)Cloudera Manager是集群的软件分发及管理监控平台,可以在几个小时内部署好一个Hadoop集群,并对集群的节点及服务进行实时监控。Cloudera Support即是对Hadoop的技术支持。
(5)Cloudera的标价为每年每个节点4000美元。Cloudera开发并贡献了可实时处理大数据的Impala项目。
3. Hortonworks Hadoop
官网地址:https://hortonworks.com/products/data-center/hdp/
下载地址:https://hortonworks.com/downloads/#data-platform
(1)2011年成立的Hortonworks是雅虎与硅谷风投公司Benchmark Capital合资组建。
(2)公司成立之初就吸纳了大约25名至30名专门研究Hadoop的雅虎工程师,上述工程师均在2005年开始协助雅虎开发Hadoop,贡献了Hadoop80%的代码。
(3)雅虎工程副总裁、雅虎Hadoop开发团队负责人Eric Baldeschwieler出任Hortonworks的首席执行官。
(4)Hortonworks的主打产品是Hortonworks Data Platform(HDP),也同样是100%开源的产品,HDP除常见的项目外还包括了Ambari,一款开源的安装和管理系统。
(5)HCatalog,一个元数据管理系统,HCatalog现已集成到Facebook开源的Hive中。Hortonworks的Stinger开创性的极大的优化了Hive项目。Hortonworks为入门提供了一个非常好的,易于使用的沙盒。
(6)Hortonworks开发了很多增强特性并提交至核心主干,这使得Apache Hadoop能够在包括Window Server和Windows Azure在内的Microsoft Windows平台上本地运行。定价以集群为基础,每10个节点每年为12500美元。
3Hadoop的优势(4高)

4 Hadoop组成(面试重点)
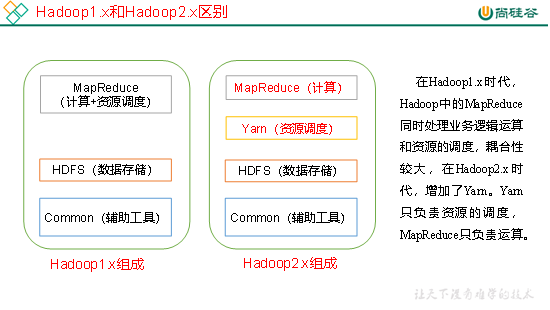
Hadoop1.x与Hadoop2.x的区别
4.1 HDFS架构概述
HDFS(Hadoop Distributed File System)的架构概述,如图2-23所示。

图2-23 HDFS架构概述
4.2 YARN架构概述
YARN架构概述,如图2-24所示。
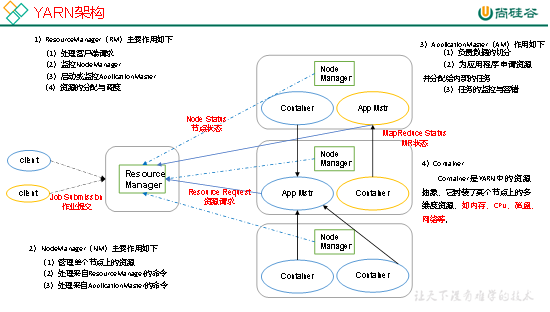
图2-24 YARN架构概述
4.3 MapReduce架构概述
MapReduce将计算过程分为两个阶段:Map和Reduce,如图2-25所示
1)Map阶段并行处理输入数据
2)Reduce阶段对Map结果进行汇总

5 大数据技术生态体系
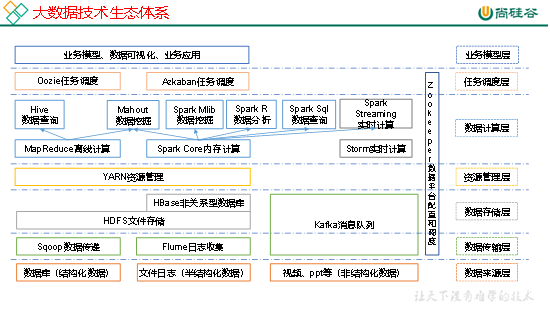
图中涉及的技术名词解释如下:
1)Sqoop:Sqoop是一款开源的工具,主要用于在Hadoop、Hive与传统的数据库(MySql)间进行数据的传递,可以将一个关系型数据库(例如 :MySQL,Oracle 等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
2)Flume:Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
3)Kafka:Kafka是一种高吞吐量的分布式发布订阅消息系统,有如下特性:
(1)通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能。
(2)高吞吐量:即使是非常普通的硬件Kafka也可以支持每秒数百万的消息。
(3)支持通过Kafka服务器和消费机集群来分区消息。
(4)支持Hadoop并行数据加载。
4)Storm:Storm用于“连续计算”,对数据流做连续查询,在计算时就将结果以流的形式输出给用户。
5)Spark:Spark是当前最流行的开源大数据内存计算框架。可以基于Hadoop上存储的大数据进行计算。
6)Oozie:Oozie是一个管理Hdoop作业(job)的工作流程调度管理系统。
7)Hbase:HBase是一个分布式的、面向列的开源数据库。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。
8)Hive:Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL查询功能,可以将SQL语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
10)R语言:R是用于统计分析、绘图的语言和操作环境。R是属于GNU系统的一个自由、免费、源代码开放的软件,它是一个用于统计计算和统计制图的优秀工具。
11)Mahout:Apache Mahout是个可扩展的机器学习和数据挖掘库。
12)ZooKeeper:Zookeeper是Google的Chubby一个开源的实现。它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、 分布式同步、组服务等。ZooKeeper的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
6 推荐系统框架图
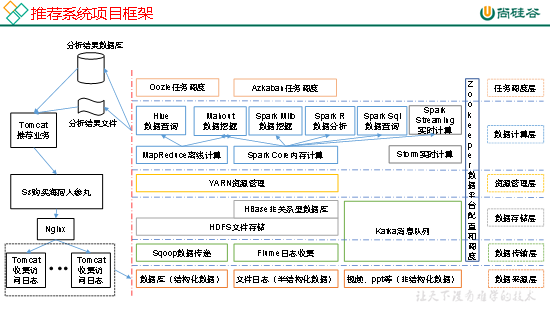
Hadoop基础(二):从Hadoop框架讨论大数据生态的更多相关文章
- Hadoop系列002-从Hadoop框架讨论大数据生态
本人微信公众号,欢迎扫码关注! 从Hadoop框架讨论大数据生态 1.Hadoop是什么 1)Hadoop是一个由Apache基金会所开发的分布式系统基础架构 2)主要解决,海量数据的存储和海量数据的 ...
- 啃掉Hadoop系列笔记(01)-Hadoop框架的大数据生态
一.Hadoop是什么 1)Hadoop是一个由Apache基金会所开发的分布式系统基础架构 2)主要解决,海量数据的存储和海量数据的分析计算问题. 3)广义上来说,HADOOP通常是指一个更广泛的概 ...
- 从Hadoop框架讨论大数据
[Hadoop是什么?] 1)Hadoop 是一个由 Apache 基金会所开发的分布式系统基础架构. 2)主要解决,海量数据的存储和海量数据的分析计算问题. 3)广义上来说,HADOOP 通常是指一 ...
- Hadoop生态圈-大数据生态体系快速入门篇
Hadoop生态圈-大数据生态体系快速入门篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.大数据概念 1>.什么是大数据 大数据(big data):是指无法在一定时间 ...
- Hadoop优势,组成的相关架构,大数据生态体系下的模式
Hadoop优势,组成的相关架构,大数据生态体系下的模式 一.Hadoop的优势 二.Hadoop的组成 2.1 HDFS架构 2.2 Yarn架构 2.3 MapReduce架构 三.大数据生态体系 ...
- 追本溯源 解析“大数据生态环境”发展现状(CSDN)
程学旗先生是中科院计算所副总工.研究员.博士生导师.网络科学与技术重点实验室主任.本次程学旗带来了中国大数据生态系统的基础问题方面的内容分享.大数据的发展越来越快,但是对于大数据的认知大都还停留在最初 ...
- 一文带你读懂zookeeper在大数据生态的应用
一个执着于技术的公众号 一.简述 在一群动物掌管的世界中,动物没有人类聪明的思想,为了保持动物世界的生态平衡,这时,动物管理员-zookeeper诞生了. 打开Apache zookeeper的官网, ...
- 开源大数据生态下的 Flink 应用实践
过去十年,面向整个数字时代的关键技术接踵而至,从被人们接受,到开始步入应用.大数据与计算作为时代的关键词已被广泛认知,算力的重要性日渐凸显并发展成为企业新的增长点.Apache Flink(以下简称 ...
- Hadoop是一种开源的适合大数据的分布式存储和处理的平台
"Hadoop能做什么?" ,概括如下: 1)搜索引擎:这也正是Doug Cutting设计Hadoop的初衷,为了针对大规模的网页快速建立索引: 2)大数据存储:利用Hadoop ...
随机推荐
- 【微信H5】 Redirect_uri参数错误解决方法
1 https://open.weixin.qq.com/connect/oauth2/authorize?appid=wx14127af0bc9fd367&redirect_uri=http ...
- HTML常用API(位置信息、音频视频)
感谢:链接(讲解的很详细) 位置信息 1.代码: <script type="text/javascript"> navigator.geolocation.getCu ...
- [计网笔记] 传输层---TCP 传输层思维导图
传输层思维导图 TCP笔记 为什么是三次握手和四次挥手 https://blog.csdn.net/baixiaoshi/article/details/67712853 [问题1]为什么连接的时候是 ...
- TensorFlow从0到1之TensorFlow实现单层感知机(20)
简单感知机是一个单层神经网络.它使用阈值激活函数,正如 Marvin Minsky 在论文中所证明的,它只能解决线性可分的问题.虽然这限制了单层感知机只能应用于线性可分问题,但它具有学习能力已经很好了 ...
- (三)Maven命令列表
mvn –version 显示版本信息 mvn clean 清理项目生产的临时文件,一般是模块下的target目录 mvn compile 编译源代码,一般编译模块下的src/main/java目录, ...
- Redis->主从复制->哨兵模式(高可用)
一:安装redis $ yum -y install gcc $ yum -y install gcc-c++ $ wget http://download.redis.io/releases/red ...
- Python多核编程mpi4py实践及并行计算-环境搭建篇
1.安装python,这个没什好说的,直接装就行 2.做并行计算.数据挖掘,机器学习等一般都要用的numpy,这个在Windows版本上安装有点问题,安装比较麻烦,建议在linux上搭建环境 3.安装 ...
- springboot 集成mybatis时日志输出
application.properties(yml)中配置的两种方式: 这两种方式的效果是一样的,但是下面一种可以指定某个包下的SQL打印出来,上面这个会全部的都会打印出来.
- 第三章:软件也要拼脸蛋-UI 开发的点点滴滴
常用控件 常用控件有:按钮 Button.文本显示框 TextView.图片显示框 ImageView.文本编辑框 EditText.进度条 ProgressBar.提示框 AlertDialog.进 ...
- java 中的 viewUtils框架
IoC的概念介绍 控制反转(IOC)模式(又称DI:Dependency Injection)就是Inversion of Control,控制反转.在Java开发中,IoC意 味着将你设计好的类交给 ...