Hadoop系列002-从Hadoop框架讨论大数据生态
本人微信公众号,欢迎扫码关注!

从Hadoop框架讨论大数据生态
1、Hadoop是什么
1)Hadoop是一个由Apache基金会所开发的分布式系统基础架构
2)主要解决,海量数据的存储和海量数据的分析计算问题。
3)广义上来说,HADOOP通常是指一个更广泛的概念——HADOOP生态圈
2、Hadoop发展历史
1)Lucene--Doug Cutting开创的开源软件,用java书写代码,实现与Google类似的全文搜索功能,它提供了全文检索引擎的架构,包括完整的查询引擎和索引引擎
2)2001年年底成为apache基金会的一个子项目
3)对于大数量的场景,Lucene面对与Google同样的困难
4)学习和模仿Google解决这些问题的办法 :微型版Nutch
5)可以说Google是hadoop的思想之源(Google在大数据方面的三篇论文)
- GFS --->HDFS
- Map-Reduce --->MR
- BigTable --->Hbase
6)2003-2004年,Google公开了部分GFS和Mapreduce思想的细节,以此为基础Doug Cutting等人用了2年业余时间实现了DFS和Mapreduce机制,使Nutch性能飙升
7)2005 年Hadoop 作为 Lucene的子项目 Nutch的一部分正式引入Apache基金会。2006 年 3 月份,Map-Reduce和Nutch Distributed File System (NDFS) 分别被纳入称为 Hadoop 的项目中
8)名字来源于Doug Cutting儿子的玩具大象
9)Hadoop就此诞生并迅速发展,标志这云计算时代来临
3、Hadoop三大发行版本
Apache、Cloudera、Hortonworks
1)Apache版本最原始(最基础)的版本,对于入门学习最好。
2)Cloudera在大型互联网企业中用的较多。
- 2008年成立的Cloudera是最早将Hadoop商用的公司,为合作伙伴提供Hadoop的商用解决方案,主要是包括支持、咨询服务、培训。
- 2009年Hadoop的创始人Doug Cutting也加盟Cloudera公司。Cloudera产品主要为CDH,Cloudera Manager,Cloudera Support
- CDH是Cloudera的Hadoop发行版,完全开源,比Apache Hadoop在兼容性,安全性,稳定性上有所增强
- Cloudera Manager是集群的软件分发及管理监控平台,可以在几个小时内部署好一个Hadoop集群,并对集群的节点及服务进行实时监控。Cloudera Support即是对Hadoop的技术支持。
- Cloudera的标价为每年每个节点4000美元。Cloudera开发并贡献了可实时处理大数据的Impala项目。
3)Hortonworks文档较好。
- 2011年成立的Hortonworks是雅虎与硅谷风投公司Benchmark Capital合资组建。
- 公司成立之初就吸纳了大约25名至30名专门研究Hadoop的雅虎工程师,上述工程师均在2005年开始协助雅虎开发Hadoop,贡献了Hadoop80%的代码。
- 雅虎工程副总裁、雅虎Hadoop开发团队负责人Eric Baldeschwieler出任Hortonworks的首席执行官。
- Hortonworks的主打产品是Hortonworks Data Platform(HDP),也同样是100%开源的产品,HDP除常见的项目外还包括了Ambari,一款开源的安装和管理系统。
- HCatalog,一个元数据管理系统,HCatalog现已集成到Facebook开源的Hive中。Hortonworks的Stinger开创性的极大的优化了Hive项目。Hortonworks为入门提供了一个非常好的,易于使用的沙盒。
- Hortonworks开发了很多增强特性并提交至核心主干,这使得Apache Hadoop能够在包括Window Server和Windows Azure在内的microsoft Windows平台上本地运行。定价以集群为基础,每10个节点每年为12500美元。
4、Hadoop的优势
1)高可靠性:因为Hadoop假设计算元素和存储会出现故障,因为它维护多个工作数据副本,在出现故障时可以对失败的节点重新分布处理。
2)高扩展性:在集群间分配任务数据,可方便的扩展数以千计的节点。
3)高效性:在MapReduce的思想下,Hadoop是并行工作的,以加快任务处理速度。
4)高容错性:自动保存多份副本数据,并且能够自动将失败的任务重新分配。
5、Hadoop组成
5.1 HDFS架构概述
1)NameNode(nn):存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的DataNode等。
2)DataNode(dn):在本地文件系统存储文件块数据,以及块数据的校验和。
3)Secondary NameNode(2nn):用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据的快照。
5.2 YARN架构概述
1)ResourceManager(rm):处理客户端请求、启动/监控ApplicationMaster、监控NodeManager、资源分配与调度。
2)NodeManager(nm):单个节点上的资源管理、处理来自ResourceManager的命令、处理来自ApplicationMaster的命令。
3)ApplicationMaster:数据切分、为应用程序申请资源,并分配给内部任务、任务监控与容错。
4)Container:对任务运行环境的抽象,封装了CPU、内存等多维资源以及环境变量、启动命令等任务运行相关的信息。
5.3 MapReduce架构概述
MapReduce将计算过程分为两个阶段:Map和Reduce
1)Map阶段并行处理输入数据
2)Reduce阶段对Map结果进行汇总
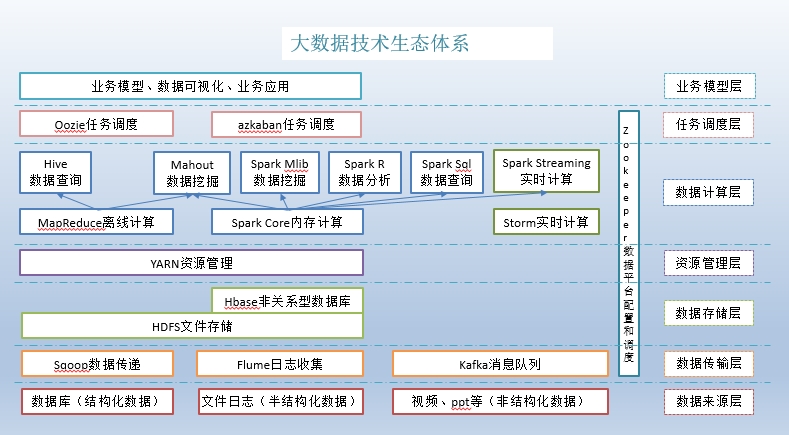
6、大数据技术生态体系
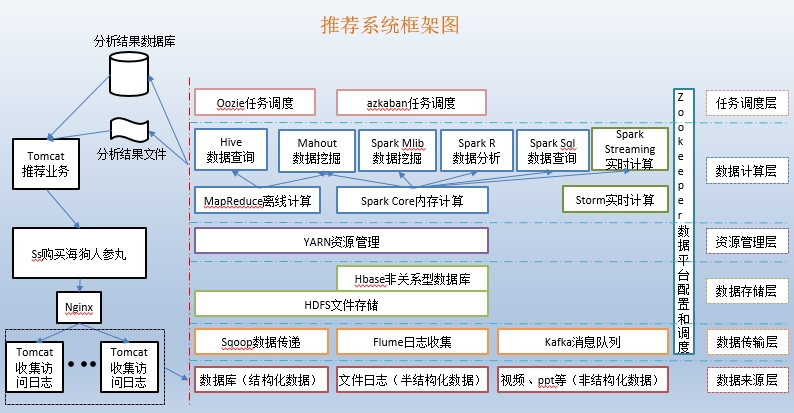
7、推荐系统框架图
Hadoop系列002-从Hadoop框架讨论大数据生态的更多相关文章
- Hadoop基础(二):从Hadoop框架讨论大数据生态
1 Hadoop是什么 2 Hadoop三大发行版本 Hadoop三大发行版本:Apache.Cloudera.Hortonworks. Apache版本最原始(最基础)的版本,对于入门学习最好. C ...
- 啃掉Hadoop系列笔记(01)-Hadoop框架的大数据生态
一.Hadoop是什么 1)Hadoop是一个由Apache基金会所开发的分布式系统基础架构 2)主要解决,海量数据的存储和海量数据的分析计算问题. 3)广义上来说,HADOOP通常是指一个更广泛的概 ...
- 从Hadoop框架讨论大数据
[Hadoop是什么?] 1)Hadoop 是一个由 Apache 基金会所开发的分布式系统基础架构. 2)主要解决,海量数据的存储和海量数据的分析计算问题. 3)广义上来说,HADOOP 通常是指一 ...
- Hadoop生态圈-大数据生态体系快速入门篇
Hadoop生态圈-大数据生态体系快速入门篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.大数据概念 1>.什么是大数据 大数据(big data):是指无法在一定时间 ...
- Hadoop优势,组成的相关架构,大数据生态体系下的模式
Hadoop优势,组成的相关架构,大数据生态体系下的模式 一.Hadoop的优势 二.Hadoop的组成 2.1 HDFS架构 2.2 Yarn架构 2.3 MapReduce架构 三.大数据生态体系 ...
- 啃掉Hadoop系列笔记(03)-Hadoop运行模式之本地模式
Hadoop的本地模式为Hadoop的默认模式,不需要启用单独进程,直接可以运行,测试和开发时使用. 在<啃掉Hadoop系列笔记(02)-Hadoop运行环境搭建>中若环境搭建成功,则直 ...
- 追本溯源 解析“大数据生态环境”发展现状(CSDN)
程学旗先生是中科院计算所副总工.研究员.博士生导师.网络科学与技术重点实验室主任.本次程学旗带来了中国大数据生态系统的基础问题方面的内容分享.大数据的发展越来越快,但是对于大数据的认知大都还停留在最初 ...
- 开源大数据生态下的 Flink 应用实践
过去十年,面向整个数字时代的关键技术接踵而至,从被人们接受,到开始步入应用.大数据与计算作为时代的关键词已被广泛认知,算力的重要性日渐凸显并发展成为企业新的增长点.Apache Flink(以下简称 ...
- 一文带你读懂zookeeper在大数据生态的应用
一个执着于技术的公众号 一.简述 在一群动物掌管的世界中,动物没有人类聪明的思想,为了保持动物世界的生态平衡,这时,动物管理员-zookeeper诞生了. 打开Apache zookeeper的官网, ...
随机推荐
- jQuery学习之旅 Item2 选择器【二】
这里接着上一个Item1 把jQuery的选择器讲完.主要有:属性过滤器和子元素过滤器 点击"名称"会跳转到此方法的jQuery官方说明文档. 5. 属性过滤器 Attribute ...
- 8.app后端和web后端的区别
很多从web后端转到app后端的小伙伴经常很茫然,不知道这两者之间有啥区别.本文通过例子,分析web后端和app后端的区别,使各位更好地把握app后端的架构. (1) app后端要慎重考虑网络传输的流 ...
- ubuntu16.04开机循环输入密码无法进入桌面的解决办法
前些天碰到一个头疼的问题,启动我的ubuntu之后,输入密码闪屏一下,又需要输入密码!!!于是再输还要再输!!!!! 经过百度一翻后终于找到原因和解决办法. 原来是我之前在profile文件里配置了一 ...
- 【二分贪心】Bzoj3969 [WF2013] Low Power
Description 有n个机器,每个机器有2个芯片,每个芯片可以放k个电池. 每个芯片能量是k个电池的能量的最小值. 两个芯片的能量之差越小,这个机器就工作的越好. 现在有2nk个电池,已知它们的 ...
- Ubuntu18.04 Desktop Entry
1.Desktop Entry 是什么? 我们都知道,在Windows里软件在安装的时候都会询问是不是要在开始菜单和桌面创建快捷方式,这样就不用在使用软件的时候去安装目录启动,而是直接去开始菜单点击相 ...
- 异步处理,Event Souring,事务补偿,实现最终一致性和服务的弹性和批处理
这段时间一直学习极客时间皓哥的分布式架构,关于异步处理有一些感想用sketch做了一个图,展示上直观一些,和大家交流下
- 将wiki人脸数据集的性别信息提取出来制作标签
import scipy.io as scio dataFile = 'D:\\Users\\a\\Documents\\Tencent Files\\178026882\\FileRecv\\wik ...
- 哎呀,我老大写Bug啦——记一次MessageQueue的优化
MessageQueue,顾名思义消息队列,在系统开发中也是用的比较多的一个中间件吧.我们这里主要用它来做日志管理和订单管理的,记得老老大(恩,是的,就是老老大,因为他已经跳槽了)还在的时候,当时也是 ...
- 供应链金融&区块链应用
现代管理教育对供应链的定义为“供应链是围绕核心企业,通过对商流,信息流,物流,资金流的控制,从采购原材料开始,制成中间产品以及最终产品,最后由销售网络把产品送到消费者手中的将供应商,制造商,分销商,零 ...
- 如何扩展分布式日志组件(Exceptionless)的Webhook事件通知类型?
写在前面 从上一篇博客高并发.低延迟之C#玩转CPU高速缓存(附示例)到现在又有几个月没写博客了,啥也不说,变得越来越懒了,懒惰产生了拖延后遗症. 最近一周升级了微服务项目使用的分布式日志组件Exce ...