python——简单爬虫
因为要学习python,所以看到一些网站有很多文章。
如:http://python.jobbole.com/all-posts/
目标:
将某个网站脚本编程-》python模块这个分类下所有的文章标题和网址提取(就相当于一个目录索引了)
在目录中找东西总好过一页页点击网页上的下一页吧。
为什么用python来实现呢,因为实在太简单易用了。在不考虑效率的情况下是大大方便了我等小白
我感觉我用爬虫得几个原因:
自从百度的site、intitle、inurl等这类搜索命令失效之后搜索关键内容的灵活度降低了,找不到想要的内容
技术博客里面有很多文章分类,可是一个分类下的文章遗憾的就是没有目录,难道要一页一页地打开网页查找么
不过不试不知道,一个简单的爬虫也牵扯了挺多东西的,总结一下
1、正则表达式,为了一行代码,把正则表达式的东西又加深学习了一遍了,无分组捕获、命名捕获、零宽断言、贪婪模式等等以前没有听过的东东。具体自己去了解吧!
2、urllib的使用,简单的使用也会有问题,看错误如下
IOError: ('http protocol error', 0, 'got a bad status line', None)
http://blog.csdn.net/yueguanghaidao/article/details/11994229 中有解释是因为http://www.website.com/需要在域名后加"/",不然会报"IOError: ('http protocol error', 0, 'got a bad status line', None)”。我第一次抓取的网页有这个错误,加了“/”访问网页直接返回404。我换成urllib2就有错误“httplib.BadStatusLine”
后来发现IOERROR是因为那个坑爹的网页本来就有问题,前一刻访问好好的,程序没写完就变成了足彩网站了。我可以理解为网站管理员休假了么。
3、中文编码问题,成功抓取了可是显示了一片看不明白的东东。看了下encode(),decode()毫无头绪,我怎么知道用什么来解码啊
>>> print fi
['python chardet\xc4\xa3\xbf\xe9\xc5\xd0\xb6\xcf\xd7\xd6\xb7\xfb\xb1\xe0\xc2\xeb'
引用一段:出自http://www.linuxidc.com/Linux/2014-11/109853.htm
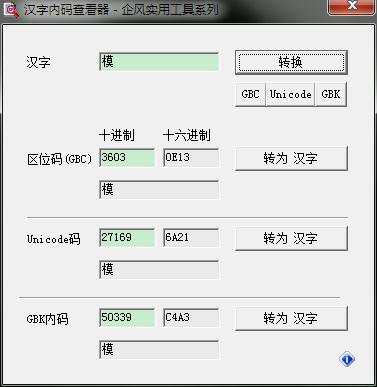
可以发现C4A3的编码是GBK,哈哈,别介意我作弊,然后成功解码。
#coding=utf-8
import urllib2
import re
import time
pattern_site_title=re.compile(r'(?<=<a class="archive-title" target="_blank" href=")(.*)(?="\stitle="(.*)">)')
for page in range(1,10):
url='http://python.jobbole.com/all-posts/page/%d/'%page
try:
url_open=urllib2.urlopen(url)
except:
exit()
print "urlopen error!" result=pattern_site_title.findall(url_open.read())
print "--------------------------------------------------------------"
for i in range(0,len(result)):
print "%s %s"%result[i]
time.sleep(3)
url_open.close()
正则表达式是个值得研究的地方,怎样才能匹配到自己需要的内容。简单的几行程序,实现了需要的功能。有更多的需要还可以在这基础上扩展。噢~~python真是个好东西
python——简单爬虫的更多相关文章
- Python简单爬虫入门三
我们继续研究BeautifulSoup分类打印输出 Python简单爬虫入门一 Python简单爬虫入门二 前两部主要讲述我们如何用BeautifulSoup怎去抓取网页信息以及获取相应的图片标题等信 ...
- Python简单爬虫入门二
接着上一次爬虫我们继续研究BeautifulSoup Python简单爬虫入门一 上一次我们爬虫我们已经成功的爬下了网页的源代码,那么这一次我们将继续来写怎么抓去具体想要的元素 首先回顾以下我们Bea ...
- GJM : Python简单爬虫入门(二) [转载]
感谢您的阅读.喜欢的.有用的就请大哥大嫂们高抬贵手"推荐一下"吧!你的精神支持是博主强大的写作动力以及转载收藏动力.欢迎转载! 版权声明:本文原创发表于 [请点击连接前往] ,未经 ...
- Python 简单爬虫案例
Python 简单爬虫案例 import requests url = "https://www.sogou.com/web" # 封装参数 wd = input('enter a ...
- Python简单爬虫记录
为了避免自己忘了Python的爬虫相关知识和流程,下面简单的记录一下爬虫的基本要求和编程问题!! 简单了解了一下,爬虫的方法很多,我简单的使用了已经做好的库requests来获取网页信息和Beauti ...
- Python简单爬虫
爬虫简介 自动抓取互联网信息的程序 从一个词条的URL访问到所有相关词条的URL,并提取出有价值的数据 价值:互联网的数据为我所用 简单爬虫架构 实现爬虫,需要从以下几个方面考虑 爬虫调度端:启动爬虫 ...
- python简单爬虫一
简单的说,爬虫的意思就是根据url访问请求,然后对返回的数据进行提取,获取对自己有用的信息.然后我们可以将这些有用的信息保存到数据库或者保存到文件中.如果我们手工一个一个访问提取非常慢,所以我们需要编 ...
- python 简单爬虫(beatifulsoup)
---恢复内容开始--- python爬虫学习从0开始 第一次学习了python语法,迫不及待的来开始python的项目.首先接触了爬虫,是一个简单爬虫.个人感觉python非常简洁,相比起java或 ...
- python 简单爬虫diy
简单爬虫直接diy, 复杂的用scrapy import urllib2 import re from bs4 import BeautifulSoap req = urllib2.Request(u ...
- Python简单爬虫入门一
为大家介绍一个简单的爬虫工具BeautifulSoup BeautifulSoup拥有强大的解析网页及查找元素的功能本次测试环境为python3.4(由于python2.7编码格式问题) 此工具在搜索 ...
随机推荐
- 昆虫之膜翅目(Hymenoptera)
1.简介 膜翅目昆虫(sawflies, wasps, ants, and bees,叶蜂.黄蜂目.蚂蚁目和蜜蜂目)是四大种类繁多的昆虫目之一,包括15.3万多种已知昆虫,可能还有多达100万种尚未发现 ...
- wget 报错 OpenSSL: error:14077410:SSL routines:SSL23_GET_SERVER_HELLO:sslv3 alert handshake failur
解决办法 换成 curl -O -L xxxxxxxx
- Tableau-安装的坑
前言: 为了学习Tableau的教程,我下载了这个软件从官网,结果安装的时候一直报一个奇怪的错误, 由于当时没有截图,只记得错误代码Xo80076666好像是,提示安装失败,已经有另一个产品安装 在我 ...
- Java输入输出流详解2
InputStream/Reader:所有输入流的基类,只能从中读取数据: OutputStream/Writer:所有输出流的基类,只能向其写入数据.
- Android笔记:intent
一.显式intent如下:(1)在intent构造函数传入两个activity文件名Intent intent = new Intent(FirstActivity.this, SecondActiv ...
- WAS 添加数据源
一.创建安全性别名认证 1.资源-全局安全性-JAVA认证和授权服务-J2C认证数据 2.新建 3.输入别名,这里后面加IP末尾.输入用户名.密码. 4.点击确定.保存. 二.创建数据源连接配置 1. ...
- P3796 【模板】AC自动机(加强版)
P3796 [模板]AC自动机(加强版) https://www.luogu.org/problemnew/show/P3796 题目描述 有NN个由小写字母组成的模式串以及一个文本串TT.每个模式串 ...
- matlab基础绘图知识
axis([xmin xmax ymin ymax]) %设置坐标轴的最小最大值 xlabel('string') %标记横坐标 ylabe ...
- 脚手架搭建vue框架
一. node安装 1)如果不确定自己是否安装了node,可以在命令行工具内执行: node -v (检查一下 版本): 2)如果 执行结果显示: xx 不是内部命令,说明你还没有安装node , ...
- centos下安装&&配置redis
一.Redis介绍 Redis是当前比较热门的NOSQL系统之一,它是一个key-value存储系统.和Memcache类似,但很大程度补偿了Memcache的不足,它支持存储的value类型相对更多 ...