Two kinds of item classification model architecture
Introduction:
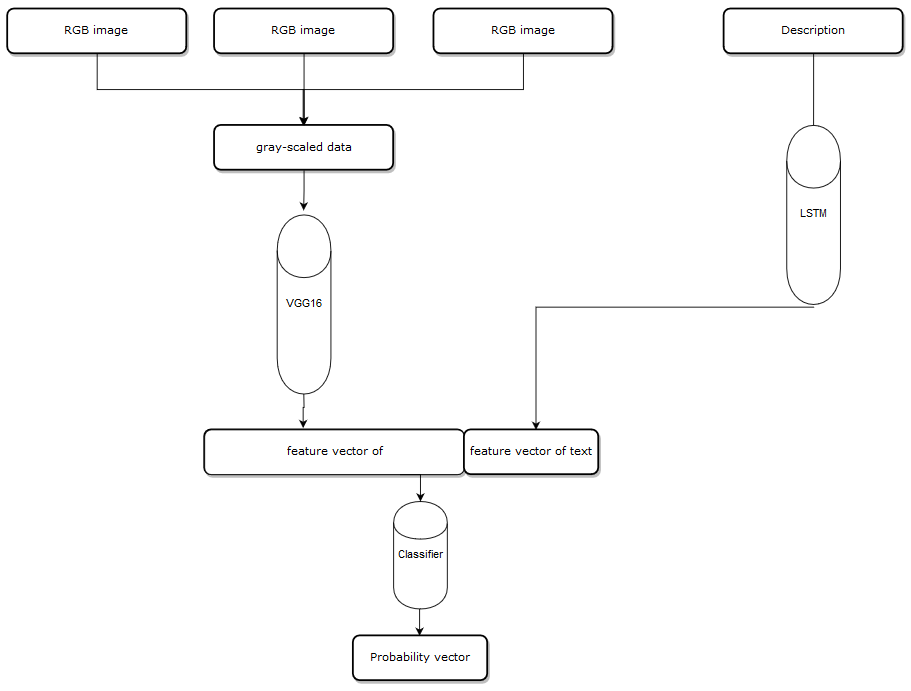
Introduction to Fusing-Probability model:
Cause the input has two parts, one is item images, the number of images can be 1 to N, one is item description contains several words. The main idea of Fusing-Probability is predicting on these features individually, and we have two classifiers, on the image side, we use VGG16 deep learning architecture which is a convolutional neural network to produce a probability for each image, and in the description side, we use an LSTM network to train a model to classify the text features. Then I use an algorithm to put all probability vectors together, finally, we get a composite probability vector, more about the algorithm can be found here https://github.com/solitaire2015/Machine-Learning-kernels/blob/master/composite-score/Composite_Score_Solution.ipynb.
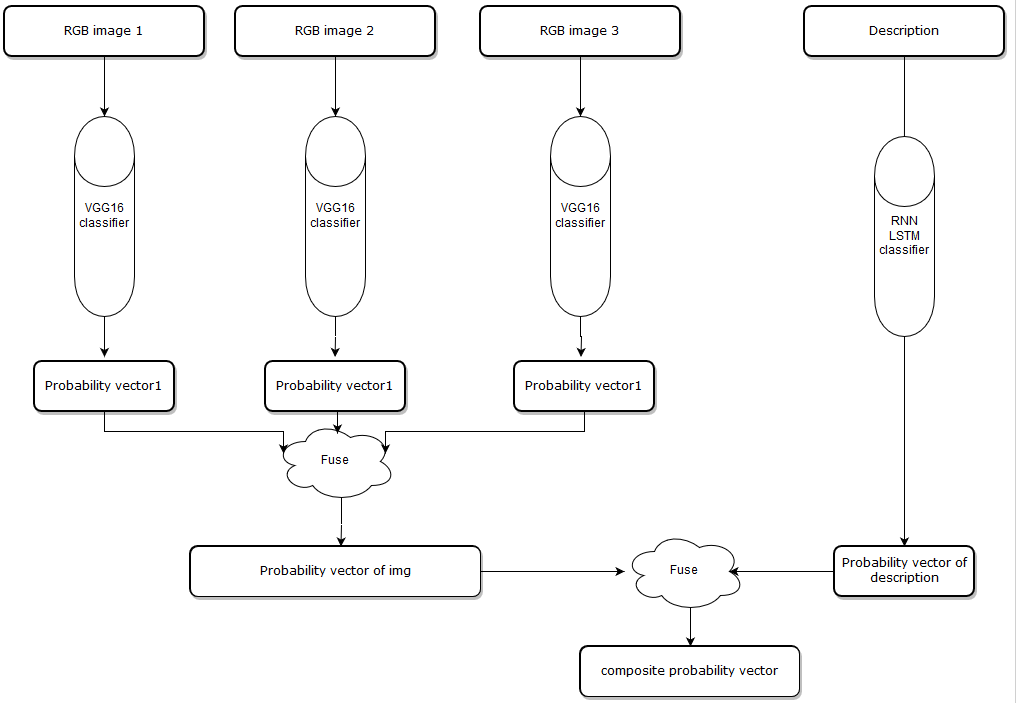
Introduction to Multi-Task model:
The main difference between these two models is we combine all features first, and put it into a single classifier, first, I choose first 3 images and convert them into gray-scale image, the shape of an RGB image is (width,height,3) because there are three channels in an RGB image, and the shape of gray-scaled image is (width,height) there is only one channel, and I combine three gray-scaled images into one data block which has shape(width,height,3). Then, we put it in the VGG16 model, instead of getting a probability vector, we get the feature vector after the last pooling layer, now we get a feature vector from the images, on the description side, same as before ,we put the description into the LSTM model, we get text feature before the model produce a probability vector, and we combine two feature vectors. then put the vector to a classifier and get the final probability vector.
Multi-Task model architecture:
Fusing-Probability model architecture:
Validation:
I test two architectures on the same data set. the data set has 10 classes:
'Desktop_CPU',
'Server_CPU',
'Desktop_Memory',
'Server_Memory',
'AllInOneComputer',
'CellPhone',
'USBFlashDrive',
‘Keyboard',
‘Mouse',
‘NoteBooks',
And the data set contains 5487 items, the Fusing-Probability model gets 93.87% accuracy, the Multi-Task model gets 93.38% accuracy, I have several figures to show the difference between two architectures.
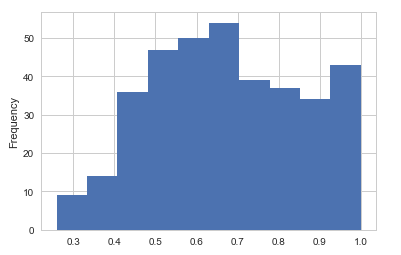
1. Items that model predict successfully and the probability distribution.
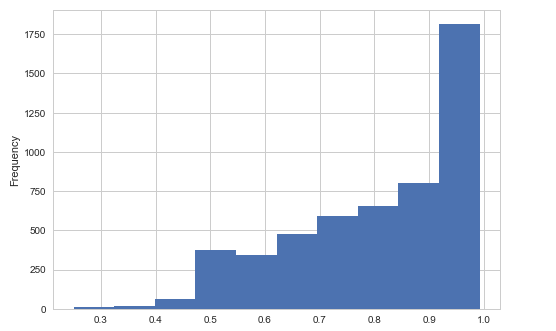
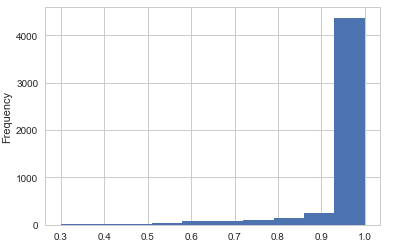
Fusing-Probability Multi-Task
2. Items that model doesn't predict success and the probability distribution.
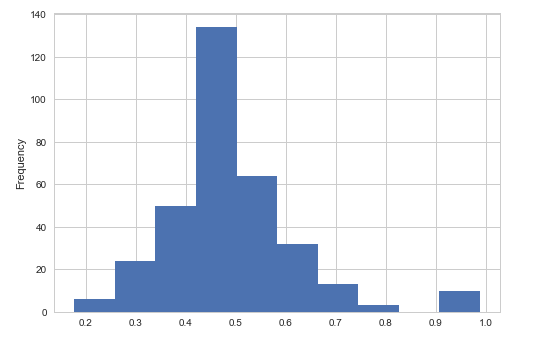
Fusing-Probability Multi-Task
3. Fraction map of the accuracy on each class.
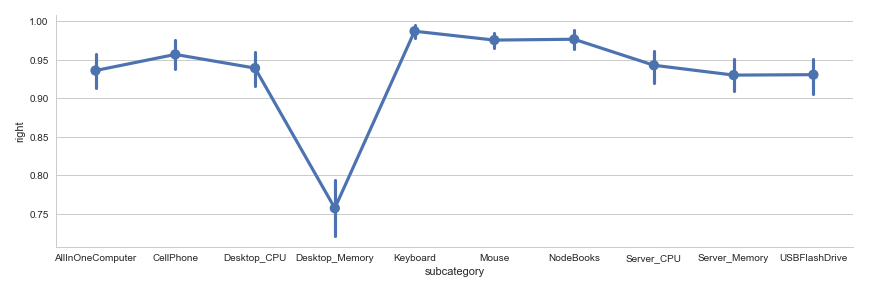

Fusing-Probability Multi-Task
4.Curve figure.
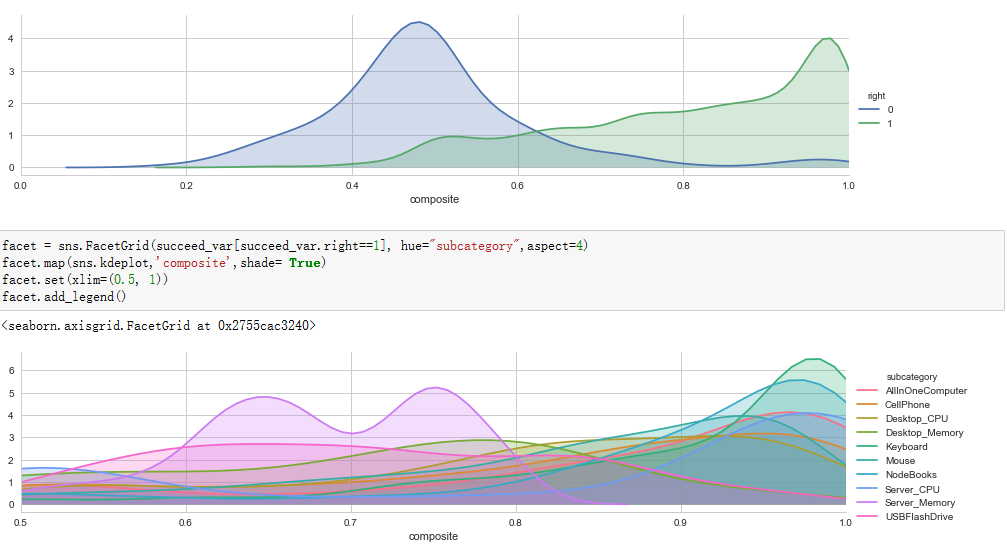
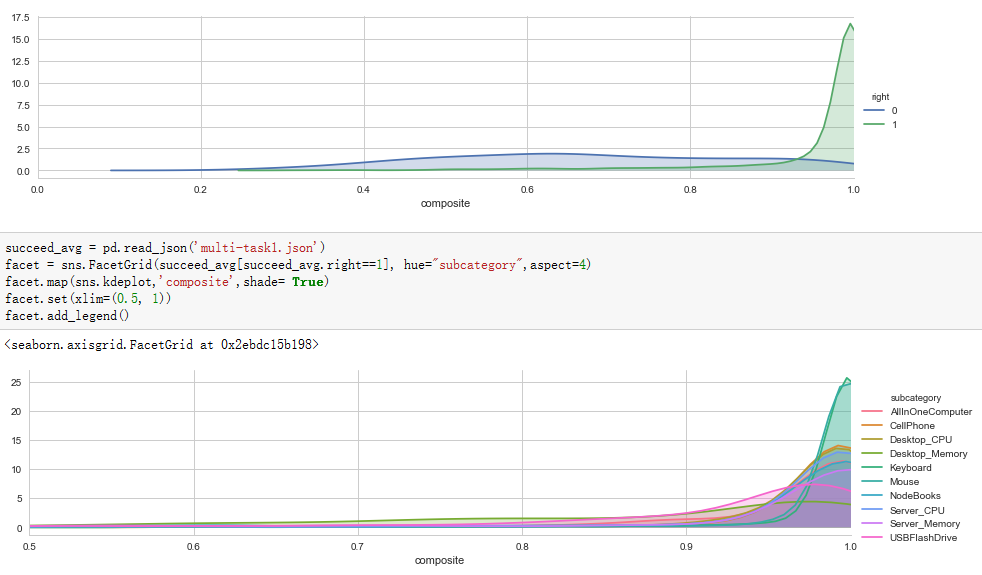
Fusing-Probability Multi-Task
5. Histogram.
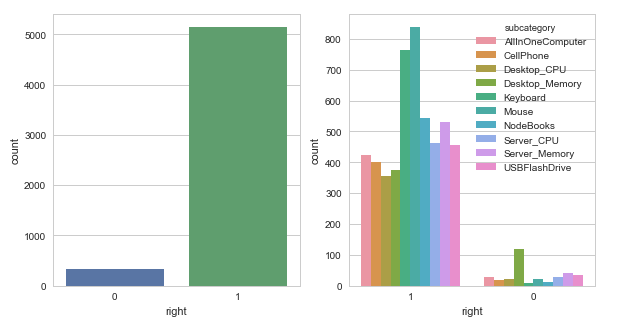
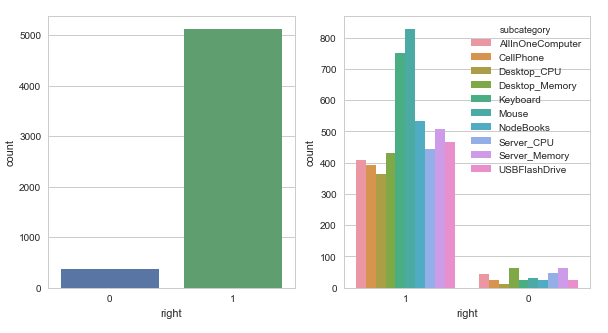
Fusing-Probability
Multi-Task
Analysis of the figures:
First,
let's look at the first couple of figures, the figure in left panel is
the histogram of the probability the Fusing-Probability model
successfully predicted, the right panel figure comes from the Multi-Task
model, most right answers have a probability greater than 0.9 in the
Multi-Task model, but in Fusing-Probability model there are some right
answers have a lower probability. From this view Multi-Task model is
better.
Second, we can get some information from a second couple
of figures, it shows the histogram of the probability that models
predict a wrong result. The probability centralizes on about 0.5 from
the Fusing-Probability model, I need to mention that some results get a
high probability greater than 0.9, they are really wrong, the data is
not so clean and has some misclassified items. Look at the right panel,
we can't find any relationship. So, Fusing-Probability model is better.
3th,
a fraction map shows model accuracy on each class, we can find that the
desktop-memory has the lowest accuracy in both models, there are some
items really hard to say if it's a desktop memory or server memory even
for a real person. But on other classes, the Fusing-Probability model
has higher accuracy than another model, Fusing-Probability is better.
4th,
it's a couple of curve figures of right and wrong predictions, we can
easily find a reasonable threshold from the left panel, because most
wrong predictions has about 0.5 probability, we can use a threshold as
0.63 when we use the model to divide all predictions in to certain and
not sure group, but in Multi-Task model we can't get a very meaningful
threshold. So, Fusing-Probability model is better.
5th, a couple
of histograms, the Fusing-Probability model gets higher accuracy, except
desktop-memory class, the model works fine, the reason why the Mouse
and Keyboard class have most right predictions are we have more samples
on these two sets.
Finally, we can find the Fusing-Probability model works better than Multi-Task model.
Pros & cons:
Multi-Task model:
Easily
to train, get higher probability when it predicts right, but when we
have a very limit data set we can't do data augmentation on the data
set, because there is not a good way to produce more data on text, if we
only do data augmentation on images, the text will be more important,
the image will be useless. The model easily gets overfitting. the image
input part is a set of images, the order would not influence the result,
but this model treats the first image more important, and we can have
at most 3 images, we will lose some information if there are more than 3
images. we convert the RGB image into gray-scaled image we may miss
some important features.
Fusing-Probability model:
We
can do data augmentation separately because we train different models
on image input and text input, we can find a more reasonable threshold
for each class, base on the probability fusing algorithm, we can have
any number of images, and the model won't consider the order of
images.The model has more flexibility.
Two kinds of item classification model architecture的更多相关文章
- 分类模型的性能评价指标(Classification Model Performance Evaluation Metric)
二分类模型的预测结果分为四种情况(正类为1,反类为0): TP(True Positive):预测为正类,且预测正确(真实为1,预测也为1) FP(False Positive):预测为正类,但预测错 ...
- Image Classification
.caret, .dropup > .btn > .caret { border-top-color: #000 !important; } .label { border: 1px so ...
- Undo/Redo for Qt Tree Model
Undo/Redo for Qt Tree Model eryar@163.com Abstract. Qt contains a set of item view classes that use ...
- [notes] ImageNet Classification with Deep Convolutional Neual Network
Paper: ImageNet Classification with Deep Convolutional Neual Network Achievements: The model address ...
- 论文笔记:Fast Neural Architecture Search of Compact Semantic Segmentation Models via Auxiliary Cells
Fast Neural Architecture Search of Compact Semantic Segmentation Models via Auxiliary Cells 2019-04- ...
- (转)Illustrated: Efficient Neural Architecture Search ---Guide on macro and micro search strategies in ENAS
Illustrated: Efficient Neural Architecture Search --- Guide on macro and micro search strategies in ...
- ASP.NET Core 中文文档 第二章 指南(4.4)添加 Model
原文:Adding a model 作者:Rick Anderson 翻译:娄宇(Lyrics) 校对:许登洋(Seay).孟帅洋(书缘).姚阿勇(Mr.Yao).夏申斌 在这一节里,你将添加一些类来 ...
- MVC5 DBContext.Database.SqlQuery获取对象集合到ViewModel集合中(可以利用这个方法给作为前台视图页cshtml页面的@model 源)
首先我们已经有了一个Model类: using System;using System.Data.Entity;using System.ComponentModel.DataAnnotations; ...
- .NET/ASP.NETMVC 大型站点架构设计—迁移Model元数据设置项(自定义元数据提供程序)
阅读目录: 1.需求背景介绍(Model元数据设置项应该与View绑定而非ViewModel) 1.1.确定问题域范围(可以使用DSL管理问题域前提是锁定领域模型) 2.迁移ViewModel设置到外 ...
随机推荐
- python学习笔记-os模块参数
python的os 模块提供了非常丰富的方法用来处理文件和目录.常用的方法如下表所示: os.access(path, mode) 检验权限模式 os.chdir(path) 改变当前工作目录 os. ...
- 使用Docker搭建LNMP开发环境
1.什么是Docker Docker 使用 Google 公司推出的 Go 语言 进行开发实现,基于 Linux 内核的 cgroup,namespace,以及 AUFS 类的 Union FS 等技 ...
- java-16习题
编写程序,产生10组彩票的“35选7”玩法的7个随机数.(-)随机数不能重复. 范围[,) import java.util.Iterator; import java.util.Random; im ...
- 多线程——C++
线程: 先说进程,进程是应用程序的执行实例,每个进程拥有其私有的虚拟地址空间.代码.数据和其它系统资源组成.进程在运行时创建的资源随着进程的终止而死亡. 而线程是一个独立的执行流,是进程内部的一个独立 ...
- 学习笔记CB004:提问、检索、回答、NLPIR
聊天机器人,提问.检索.回答. 提问,查询关键词生成.答案类型确定.句法和语义分析.查询关键词生成,提问提取关键词,中心词关联扩展词.答案类型确定,确定提问类型.句法和语义分析,问题深层含义剖析.检索 ...
- 谈一谈java中的Canves机制
0--写在前面: 很多初学java的童鞋,常常很苦恼,一天天的都跟命令行较劲,好像很无聊的样子,如果能跳出命令行做出界面甚至一个画图界面,那将是一件很兴奋的事情:也可以让编程变的有趣:有脑洞的同学还可 ...
- python-算法基础
1.时间复杂度和空间复杂度 2.查找算法 2.1 二分查询法 2.1.1 非递归代码 def erfen(data,target): low = 0 high = len(data) - 1 whil ...
- ionic页面间跳转的动画实现
1. 在<ion-view>标签中加入: nav-direction="back"或nav-direction="forward" 2.用$stat ...
- Salesforce Invoking Http Callouts and Testing Http Callouts
本文参考官方文档和zero zhang的博客: https://developer.salesforce.com/docs/atlas.en-us.apexcode.meta/apexcode/ape ...
- Win10无法访问网上邻居电脑共享的文件夹怎么办
Win10无法访问网上邻居电脑共享的文件夹怎么办 现在许多电脑上装的都是Win系统,Win10无法访问网上邻居电脑共享的文件夹怎么办呢?下面小编为大家介绍下解决的方法吧! 1点击桌面上的“此电脑”图标 ...