分类模型的性能评价指标(Classification Model Performance Evaluation Metric)
二分类模型的预测结果分为四种情况(正类为1,反类为0):
- TP(True Positive):预测为正类,且预测正确(真实为1,预测也为1)
- FP(False Positive):预测为正类,但预测错误(真实为0,预测为1)
- TN(True Negative):预测为负类,且预测正确(真实为0,预测也为0)
- FN(False Negative):预测为负类,但预测错误(真实为1,预测为0)
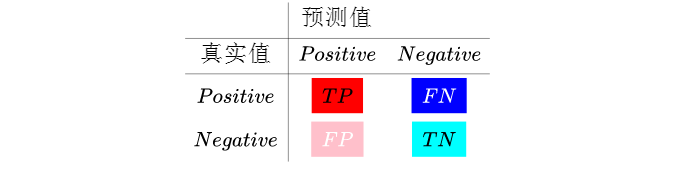
TP+FP+TN+FN=测试集所有样本数量。
分类模型的性能评价指标(Performance Evaluation Metric)有:
准确率(Accuracy):所有分类正确的样本数量除以总样本数量
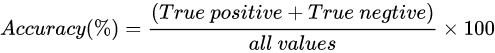
错误率(Error Rate):所有分类错误的样本数量除以总样本数量
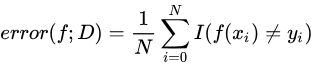 (其中
(其中为指示函数,满足要求则为1,不满足为0)
错误率等于一减准确率:。
混淆矩阵(Confusion Matrix):把真实值和预测值相对应的样本数量列出来的一张交叉表。这样,所有正确的预测结果都在其对角线上,所以从混淆矩阵中可以很直观地看出哪里有错误。


准确率或错误率是最基本的分类模型性能评价指标。但是有时候各类别样本数量不均衡,比如说,在一共100个测试样本中,正类样本有98个,负类样本只有2个,那么我们只需要把模型做成把所有样本都判为正类即可,这样准确率可以达到98%。但是这样的模型毫无意义。
即使各类别样本数量比较均衡,但如果我们更关心其中某个类别,那么我们就需要选择我们感兴趣的类别的各项指标来评价模型的好坏。因此,人们又发明出了查全率和查准率等指标。
精确度(Precision):在所有预测为正类的样本中,预测正确的比例,也称为查准率

召回率(Recall):在所有实际为正类的样本中,预测正确的比例,也称为查全率
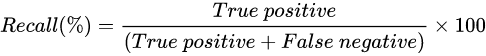
查准率和查全率是一对矛盾的度量。一般来说,查准率高时,查全率往往偏低;而查全率高时,查准率往往偏低。如果对这两个指标都有要求,那么可以计算模型的F1值或查看PR曲线。
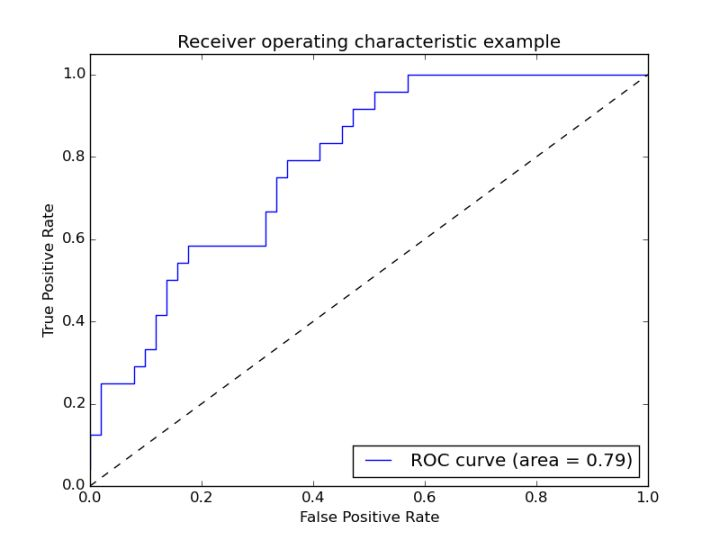
F1值(F1 Score):查准率和查全率的调和平均值
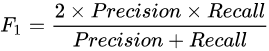
P-R曲线(Precision-Recall Curve):以precision为y轴,以recall为x轴,取不同的分类阈值,在此基础上画出来的一条曲线就叫做PR曲线。PR曲线越接近右上角(precision=1, recall=1),代表模型越好。若一个模型的PR曲线被另一个模型的PR曲线完全“包住”,则可断言后者的性能优于前者;但若二者的曲线发生了交叉,则难以一般性地断言两者孰优孰劣,只能在具体查准率或查全率条件下比较。一般而言,比较 P-R 曲线下面积的大小,可一定程度上表征模型在查准率和查全率上取得相对 “双高”的比例,但该值不太容易计算。因此其它相对容易计算的性能度量被提出。
真正率(True Positive Rate,TPR):TPR = TP/(TP+FN),TPR越大越好,1为理想状态
假正率(False Positive Rate,FPR):FPR = FP/(TN+FP),FPR越小越好,0为理想状态
灵敏性(Sensitivity): True Positive Rate,等同于召回率
特异性(Specificity): True Negative Rate,Specificity = 1- False Positive Rate,SPC = TN/(FP + TN)
这几个性能指标不受不均衡数据的影响。若要综合考虑TPR和FPR,那么可以查看ROC曲线。
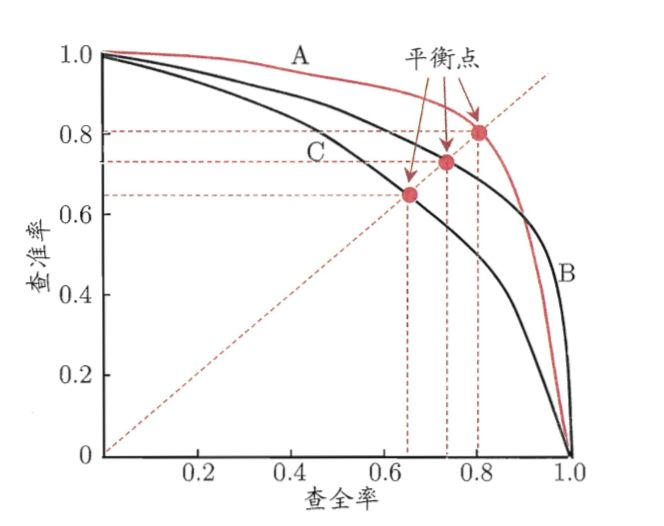
ROC曲线(Receiver Operating Characteristic Curve):全称“受试者工作特征”曲线。以“真正率”(True Positivate Rate,简称 TPR)为y轴,以“假正例”(False Positive Rate,简称 FPR)为x轴,取不同的分类阈值,在此基础上画出来的一条曲线就叫做ROC曲线。ROC曲线越接近左上角(true positive rate=1, false positive rate=0),代表模型性能越好。与 P-R 曲线一样,若一个模型的 ROC 曲线被另一个模型的曲线完全“包住”,则断言后者的性能优于前者;若有交叉,则难以一般断言,此时可通过比较ROC曲线下的面积来判断。
AUC(Area Under Curve):曲线下面积。AUC越大,代表模型性能越好。若AUC=0.5,即ROC曲线与上图中的虚线重合,表示模型的区分能力与随机猜测没有差别。
以上说的是二分类的场景。对于多分类问题,有两种方法计算其性能评价指标:
方法一:将多分类问题拆解成n个一对其余的二分类问题,这样可以得到n个混淆矩阵,分别计算出每个类别的precision和recall,再将其平均,即得到”宏查准率“(macro-P),”宏查全率“(macro-R),相应计算出的的F1值称为”宏F1“(macro-F1)。对每个类别计算出样本在各个阈值下的假正率(FPR)和真正率(TPR),从而绘制出一条ROC曲线,这样总共可以绘制出n条ROC曲线,对n条ROC曲线取平均,即可得到最终的ROC曲线。

方法二:将多分类问题拆解成n个一对其余的二分类问题,这样可以得到n个混淆矩阵,把所有混淆矩阵中的TP,NP,FP,FN计算平均值 ,再用这些平均值计算出查准率和查全率,称为”微查准率“(micro-P),”微查全率“(micro-R),由微查准率和微查全率计算出的F1值称为 ”微 F1“(micro-F1)。
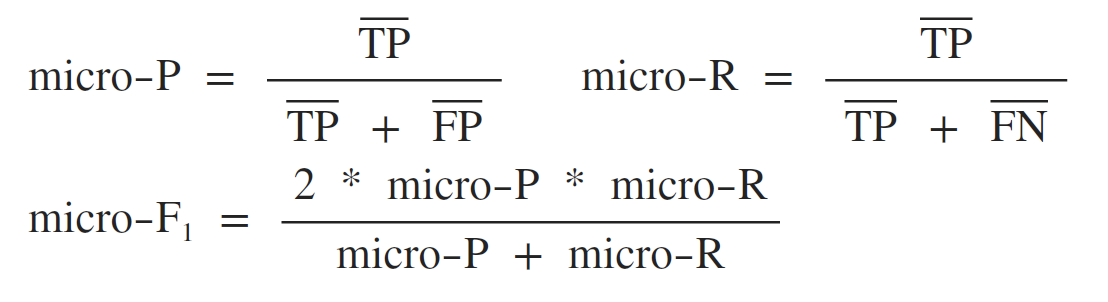
对于多分类问题,macro-average(宏平均) 要比 micro-average(微平均) 好,因为宏平均受样本数量少的类别影响较大。
参考:https://www.zhihu.com/question/30643044
分类模型的性能评价指标(Classification Model Performance Evaluation Metric)的更多相关文章
- 回归模型的性能评价指标(Regression Model Performance Evaluation Metric)
回归模型的性能评价指标(Performance Evaluation Metric)通常有: 1. 平均绝对误差(Mean Absolute Error, MAE):真实目标y与估计值y-hat之间差 ...
- Spark学习笔记——构建分类模型
Spark中常见的三种分类模型:线性模型.决策树和朴素贝叶斯模型. 线性模型,简单而且相对容易扩展到非常大的数据集:线性模型又可以分成:1.逻辑回归:2.线性支持向量机 决策树是一个强大的非线性技术, ...
- 【AUC】二分类模型的评价指标ROC Curve
AUC是指:从一堆样本中随机抽一个,抽到正样本的概率比抽到负样本的概率大的可能性! AUC是一个模型评价指标,只能用于二分类模型的评价,对于二分类模型,还有很多其他评价指标,比如logloss,acc ...
- 『高性能模型』Roofline Model与深度学习模型的性能分析
转载自知乎:Roofline Model与深度学习模型的性能分析 在真实世界中,任何模型(例如 VGG / MobileNet 等)都必须依赖于具体的计算平台(例如CPU / GPU / ASIC 等 ...
- 利用libsvm-mat建立分类模型model参数解密[zz from faruto]
本帖子主要就是讲解利用libsvm-mat工具箱建立分类(回归模型)后,得到的模型model里面参数的意义都是神马?以及如果通过model得到相应模型的表达式,这里主要以分类问题为例子. 测试数据使用 ...
- 【分类问题中模型的性能度量(二)】超强整理,超详细解析,一文彻底搞懂ROC、AUC
文章目录 1.背景 2.ROC曲线 2.1 ROC名称溯源(选看) 2.2 ROC曲线的绘制 3.AUC(Area Under ROC Curve) 3.1 AUC来历 3.2 AUC几何意义 3.3 ...
- 分类模型的评价指标Fscore
小书匠深度学习 分类方法常用的评估模型好坏的方法. 0.预设问题 假设我现在有一个二分类任务,是分析100封邮件是否是垃圾邮件,其中不是垃圾邮件有65封,是垃圾邮件有35封.模型最终给邮件的结论只有两 ...
- NLP学习(2)----文本分类模型
实战:https://github.com/jiangxinyang227/NLP-Project 一.简介: 1.传统的文本分类方法:[人工特征工程+浅层分类模型] (1)文本预处理: ①(中文) ...
- 【机器学习与R语言】12- 如何评估模型的性能?
目录 1.评估分类方法的性能 1.1 混淆矩阵 1.2 其他评价指标 1)Kappa统计量 2)灵敏度与特异性 3)精确度与回溯精确度 4)F度量 1.3 性能权衡可视化(ROC曲线) 2.评估未来的 ...
随机推荐
- Django中ORM过滤时objects.filter()无法对月份过滤
django中的filter日期查询属性有:year.month.day.week_day.hour.minute.second 在做复习博客项目时,我把项目从linux移到了windows,然后博客 ...
- JVM 参数调优配置
在 tomcat 配置文件 tomcat/bin/catalina.sh 中 配置 JAVA_OPTS="-server -Xms2048m -Xmx2048m -Xss1024K -XX ...
- 表单提交学习笔记(二)—使用jquery.validate.js进行表单验证
一.官网下载地址:http://plugins.jquery.com/validate/ 二.用法 1.在页面上进行引用 <script src="~/scripts/jquery-1 ...
- docker save load export import的区别
export export命令用于持久化容器(不是镜像).所以,我们就需要通过以下方法得到容器ID: sudo docker ps -a 接着执行导出: sudo docker export < ...
- Kubernetes Storage Persistent Volumes
链接:https://kubernetes.io/docs/concepts/storage/persistent-volumes/ 支持的参数,比如mountOptions在这里可以找到 删除正在被 ...
- That IP address can't be assigned to.的问题
That IP address can't be assigned to. 烦恼了很久,现在知道了,解决的办法如下 首先确定端口号是不是开放,阿里云的直接在控制台修改 其次 看看 你的地址是不是输入错 ...
- 在Controller中添加事务管理
文章参考了此博客: https://blog.csdn.net/qq_40594137/article/details/82772545 写这篇文章之前先说明一下: 1. Controller中添加事 ...
- maven下载jar demo
pom.xml <?xml version="1.0"?> <project xmlns="http://maven.apache.org/POM/4. ...
- python系列:二、Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 打开我们的浏览器,调 ...
- 华为云主机配置yum源
问题: 拥有华为主机,配置华为云mirrors,不走公网流量加速体验 系统: centos7.6 解决: 01.华为云mirrors https://mirrors.huaweicloud.com/ ...