Two kinds of item classification model architecture
Introduction:
Introduction to Fusing-Probability model:
Cause the input has two parts, one is item images, the number of images can be 1 to N, one is item description contains several words. The main idea of Fusing-Probability is predicting on these features individually, and we have two classifiers, on the image side, we use VGG16 deep learning architecture which is a convolutional neural network to produce a probability for each image, and in the description side, we use an LSTM network to train a model to classify the text features. Then I use an algorithm to put all probability vectors together, finally, we get a composite probability vector, more about the algorithm can be found here https://github.com/solitaire2015/Machine-Learning-kernels/blob/master/composite-score/Composite_Score_Solution.ipynb.
Introduction to Multi-Task model:
The main difference between these two models is we combine all features first, and put it into a single classifier, first, I choose first 3 images and convert them into gray-scale image, the shape of an RGB image is (width,height,3) because there are three channels in an RGB image, and the shape of gray-scaled image is (width,height) there is only one channel, and I combine three gray-scaled images into one data block which has shape(width,height,3). Then, we put it in the VGG16 model, instead of getting a probability vector, we get the feature vector after the last pooling layer, now we get a feature vector from the images, on the description side, same as before ,we put the description into the LSTM model, we get text feature before the model produce a probability vector, and we combine two feature vectors. then put the vector to a classifier and get the final probability vector.
Multi-Task model architecture:
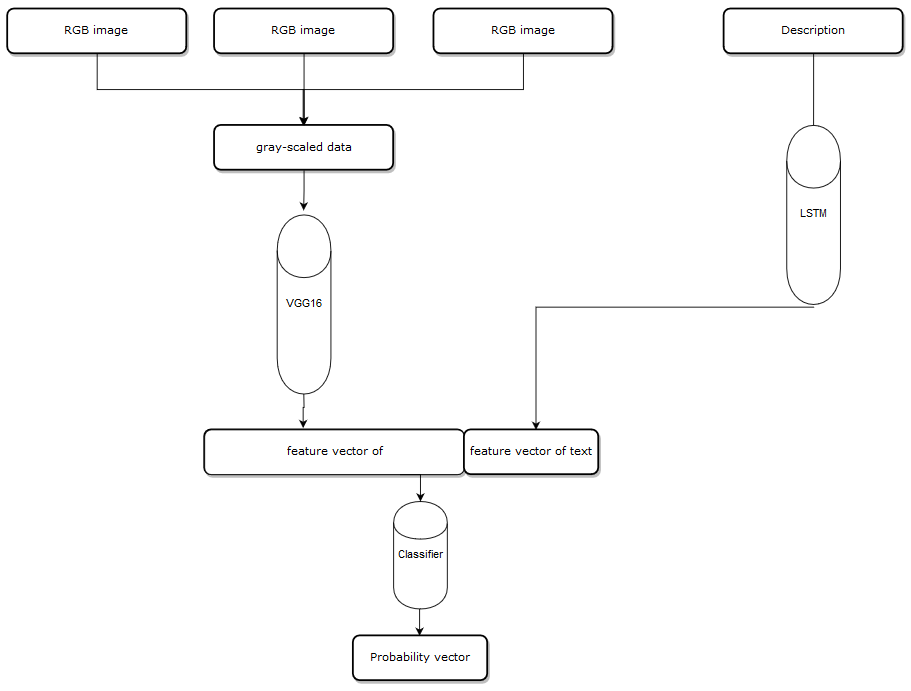
Fusing-Probability model architecture:
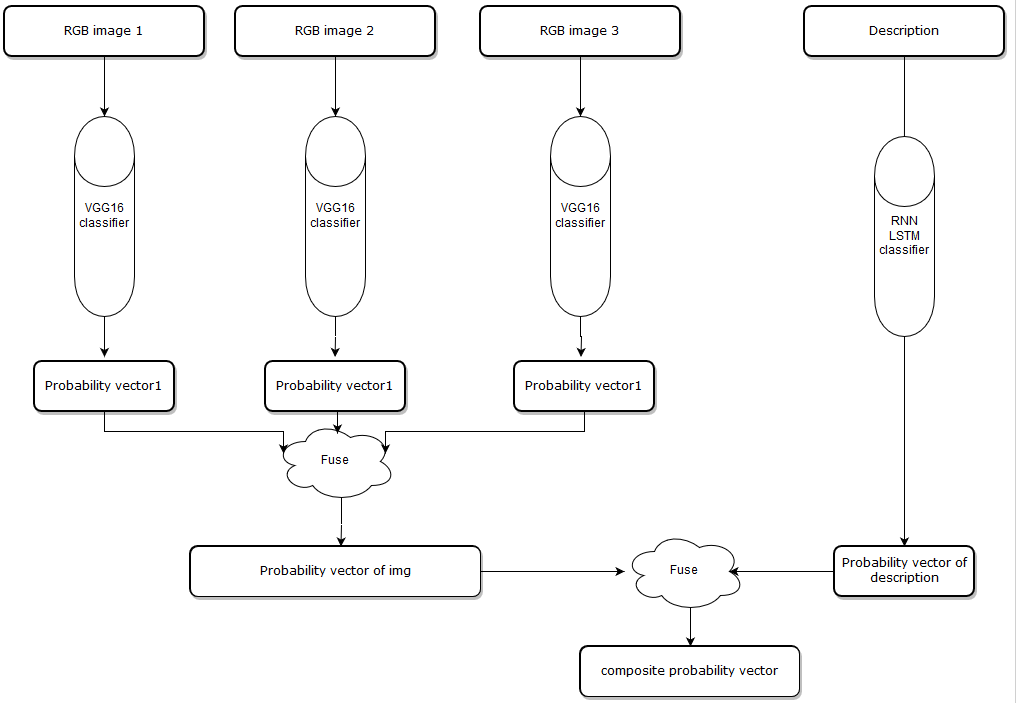
Validation:
I test two architectures on the same data set. the data set has 10 classes:
'Desktop_CPU',
'Server_CPU',
'Desktop_Memory',
'Server_Memory',
'AllInOneComputer',
'CellPhone',
'USBFlashDrive',
‘Keyboard',
‘Mouse',
‘NoteBooks',
And the data set contains 5487 items, the Fusing-Probability model gets 93.87% accuracy, the Multi-Task model gets 93.38% accuracy, I have several figures to show the difference between two architectures.
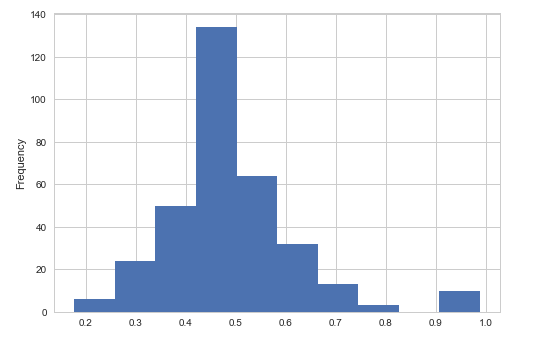
1. Items that model predict successfully and the probability distribution.
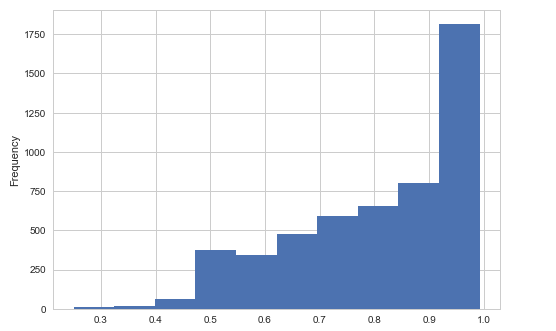
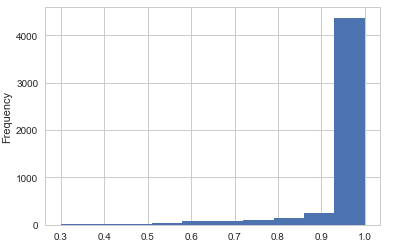
Fusing-Probability Multi-Task
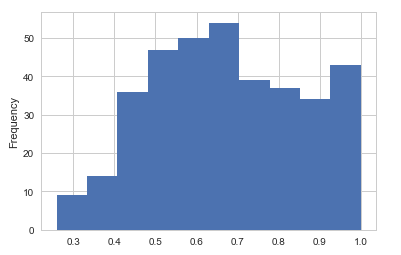
2. Items that model doesn't predict success and the probability distribution.
Fusing-Probability Multi-Task
3. Fraction map of the accuracy on each class.
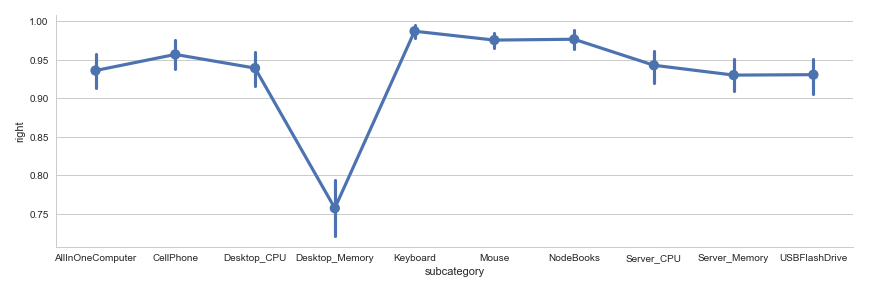

Fusing-Probability Multi-Task
4.Curve figure.
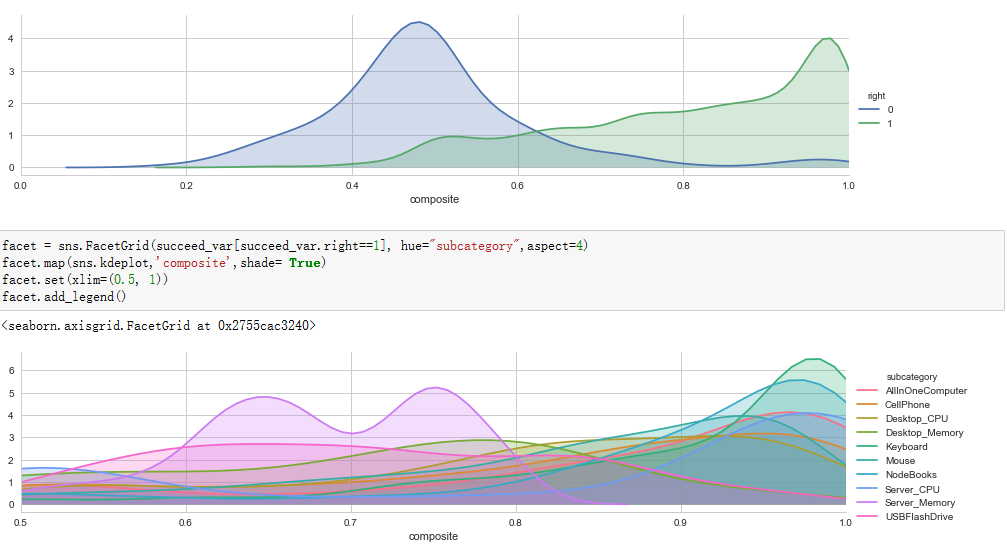
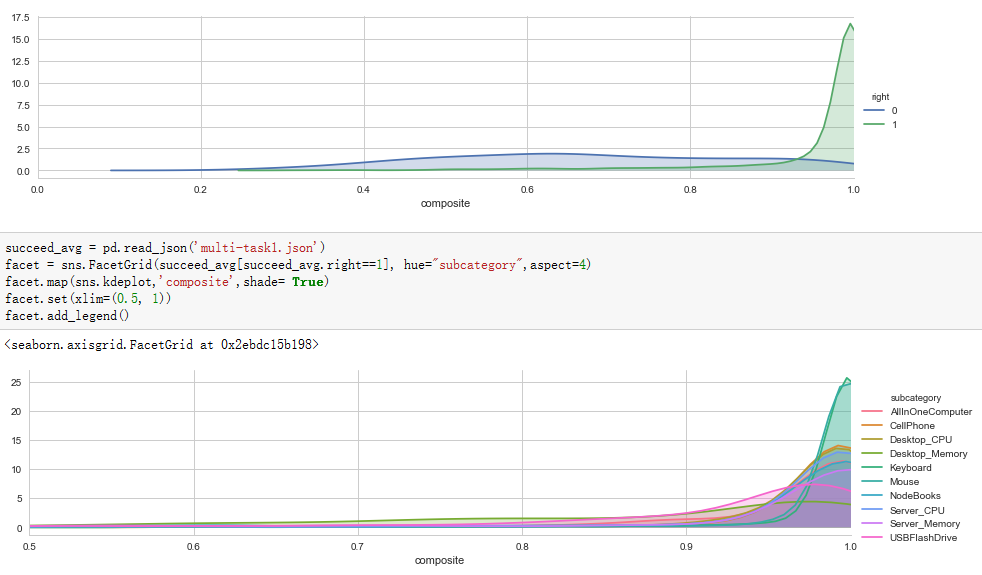
Fusing-Probability Multi-Task
5. Histogram.
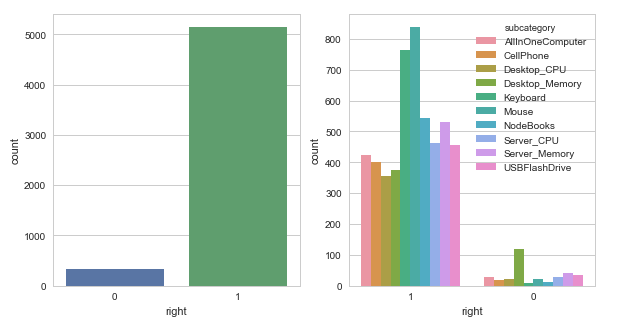
Fusing-Probability
Multi-Task
Analysis of the figures:
First,
let's look at the first couple of figures, the figure in left panel is
the histogram of the probability the Fusing-Probability model
successfully predicted, the right panel figure comes from the Multi-Task
model, most right answers have a probability greater than 0.9 in the
Multi-Task model, but in Fusing-Probability model there are some right
answers have a lower probability. From this view Multi-Task model is
better.
Second, we can get some information from a second couple
of figures, it shows the histogram of the probability that models
predict a wrong result. The probability centralizes on about 0.5 from
the Fusing-Probability model, I need to mention that some results get a
high probability greater than 0.9, they are really wrong, the data is
not so clean and has some misclassified items. Look at the right panel,
we can't find any relationship. So, Fusing-Probability model is better.
3th,
a fraction map shows model accuracy on each class, we can find that the
desktop-memory has the lowest accuracy in both models, there are some
items really hard to say if it's a desktop memory or server memory even
for a real person. But on other classes, the Fusing-Probability model
has higher accuracy than another model, Fusing-Probability is better.
4th,
it's a couple of curve figures of right and wrong predictions, we can
easily find a reasonable threshold from the left panel, because most
wrong predictions has about 0.5 probability, we can use a threshold as
0.63 when we use the model to divide all predictions in to certain and
not sure group, but in Multi-Task model we can't get a very meaningful
threshold. So, Fusing-Probability model is better.
5th, a couple
of histograms, the Fusing-Probability model gets higher accuracy, except
desktop-memory class, the model works fine, the reason why the Mouse
and Keyboard class have most right predictions are we have more samples
on these two sets.
Finally, we can find the Fusing-Probability model works better than Multi-Task model.
Pros & cons:
Multi-Task model:
Easily
to train, get higher probability when it predicts right, but when we
have a very limit data set we can't do data augmentation on the data
set, because there is not a good way to produce more data on text, if we
only do data augmentation on images, the text will be more important,
the image will be useless. The model easily gets overfitting. the image
input part is a set of images, the order would not influence the result,
but this model treats the first image more important, and we can have
at most 3 images, we will lose some information if there are more than 3
images. we convert the RGB image into gray-scaled image we may miss
some important features.
Fusing-Probability model:
We
can do data augmentation separately because we train different models
on image input and text input, we can find a more reasonable threshold
for each class, base on the probability fusing algorithm, we can have
any number of images, and the model won't consider the order of
images.The model has more flexibility.
Two kinds of item classification model architecture的更多相关文章
- 分类模型的性能评价指标(Classification Model Performance Evaluation Metric)
二分类模型的预测结果分为四种情况(正类为1,反类为0): TP(True Positive):预测为正类,且预测正确(真实为1,预测也为1) FP(False Positive):预测为正类,但预测错 ...
- Image Classification
.caret, .dropup > .btn > .caret { border-top-color: #000 !important; } .label { border: 1px so ...
- Undo/Redo for Qt Tree Model
Undo/Redo for Qt Tree Model eryar@163.com Abstract. Qt contains a set of item view classes that use ...
- [notes] ImageNet Classification with Deep Convolutional Neual Network
Paper: ImageNet Classification with Deep Convolutional Neual Network Achievements: The model address ...
- 论文笔记:Fast Neural Architecture Search of Compact Semantic Segmentation Models via Auxiliary Cells
Fast Neural Architecture Search of Compact Semantic Segmentation Models via Auxiliary Cells 2019-04- ...
- (转)Illustrated: Efficient Neural Architecture Search ---Guide on macro and micro search strategies in ENAS
Illustrated: Efficient Neural Architecture Search --- Guide on macro and micro search strategies in ...
- ASP.NET Core 中文文档 第二章 指南(4.4)添加 Model
原文:Adding a model 作者:Rick Anderson 翻译:娄宇(Lyrics) 校对:许登洋(Seay).孟帅洋(书缘).姚阿勇(Mr.Yao).夏申斌 在这一节里,你将添加一些类来 ...
- MVC5 DBContext.Database.SqlQuery获取对象集合到ViewModel集合中(可以利用这个方法给作为前台视图页cshtml页面的@model 源)
首先我们已经有了一个Model类: using System;using System.Data.Entity;using System.ComponentModel.DataAnnotations; ...
- .NET/ASP.NETMVC 大型站点架构设计—迁移Model元数据设置项(自定义元数据提供程序)
阅读目录: 1.需求背景介绍(Model元数据设置项应该与View绑定而非ViewModel) 1.1.确定问题域范围(可以使用DSL管理问题域前提是锁定领域模型) 2.迁移ViewModel设置到外 ...
随机推荐
- spring 集成redis客户端jedis(java)
spring集成jedis简单实例 jedis是redis的java客户端,spring将redis连接池作为一个bean配置. “redis.clients.jedis.JedisPool”,这 ...
- list quen队列
队列特性:先进先出 stack 栈先进后出 push() 输入 pop()输出 set接口 collectonjiek list接口:可重复集(可以用下标取值) set接口:不可重复集(没下标) Ha ...
- Intel的CPU漏洞:Spectre
最近觉得越来越忙,写博客都没精力了.一定是太沉迷农药和刷即刻了…… 17年年底,18年年初,Intel被爆出了Meltdown(熔断)和Spectre(幽灵)漏洞.等Spectre攻击的POC出来以后 ...
- spring源码1:基本概念
一.预习 1.如何用spring?零配置(注解)或少配置,与应用无侵入性一起运行,与主流框架无缝集成. 2.spring 是什么?spring 是 java 企业应用级框架,目的是为了简化开发:主要体 ...
- C# Cookie方法
//写入 protected void Button1_Click(object sender, EventArgs e) { HttpCookie cookie=new HttpCookie(&qu ...
- http和https区别及概念
HTTP:是互联网上的应用广泛的一种网络协议,是一个客户端和服务器端请求和应答的传输协议,它可以使浏览器更加高效,使网络传输减少. HTTPS:是以安全为目标的HTTP通道,简单讲是HTTP的安全版, ...
- 芯灵思SinlinxA33开发板 Linux平台总线设备驱动
1.什么是platform(平台)总线? 相对于USB.PCI.I2C.SPI等物理总线来说,platform总线是一种虚拟.抽象出来的总线,实际中并不存在这样的总线. 那为什么需要platform总 ...
- kotlin 编译 运行 hello world
kotlin 编译器下载地址:https://github.com/JetBrains/kotlin/releases/tag/v1.3.31 解压:kotlin-compiler-1.3.31.zi ...
- Python(三)——文件操作
在我们用语言的过程中,比如要往文件内进行读写,那么势必要进行文件操作,那么咋操作呢?用眼睛直接看么?今天就定个小目标,把文件读写那些事扯一扯 文件操作 把大象放进冰箱分几步? 第一步:打开冰箱 第二步 ...
- Dubbo和Spring Cloud
1.Dubbo和Spring Cloud区别 1).通信方式不同 Dubbo使用RPC通信,Spring Cloud使用Http RestFul方式 2) 组成部分不同 组件 Dubbo Spring ...