Hadoop简介及架构
狭义上来说,hadoop就是单独指代hadoop这个软件,
广义上来说,hadoop指代大数据的一个生态圈,包括很多其他的软件
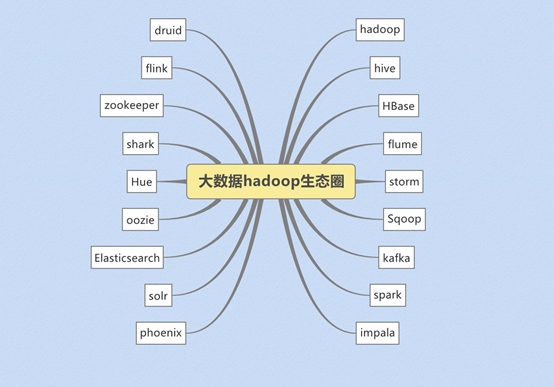

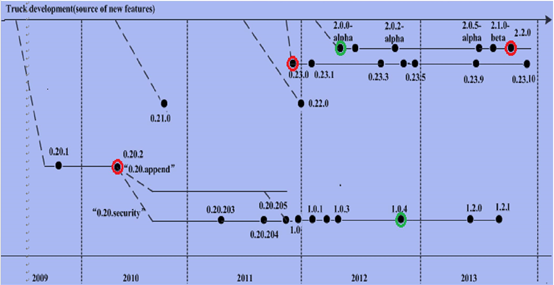
2、hadoop的历史版本介绍
0.x系列版本:hadoop当中最早的一个开源版本,在此基础上演变而来的1.x以及2.x的版本
1.x版本系列:hadoop版本当中的第二代开源版本,主要修复0.x版本的一些bug等
2.x版本系列:架构产生重大变化,引入了yarn平台等许多新特性
3、hadoop三大公司发型版本介绍
免费开源版本apache:
优点:拥有全世界的开源贡献者,代码更新迭代版本比较快,
缺点:版本的升级,版本的维护,版本的兼容性,版本的补丁都可能考虑不太周到,学习可以用,实际生产工作环境尽量不要使用
apache所有软件的下载地址(包括各种历史版本):
http://archive.apache.org/dist/
免费开源版本hortonWorks:
hortonworks主要是雅虎主导Hadoop开发的副总裁,带领二十几个核心成员成立Hortonworks,核心产品软件HDP(ambari),HDF免费开源,并且提供一整套的web管理界面,供我们可以通过web界面管理我们的集群状态,web管理界面软件HDF网址(http://ambari.apache.org/)
软件收费版本ClouderaManager:
cloudera主要是美国一家大数据公司在apache开源hadoop的版本上,通过自己公司内部的各种补丁,实现版本之间的稳定运行,大数据生态圈的各个版本的软件都提供了对应的版本,解决了版本的升级困难,版本兼容性等各种问题,生产环境强烈推荐使用
4、hadoop的架构模型(1.x,2.x的各种架构模型介绍)
4.1、1.x的版本架构模型介绍

文件系统核心模块:
NameNode:集群当中的主节点,主要用于管理集群当中的各种数据
secondaryNameNode:主要能用于hadoop当中元数据信息的辅助管理
DataNode:集群当中的从节点,主要用于存储集群当中的各种数据
数据计算核心模块:
JobTracker:接收用户的计算请求任务,并分配任务给从节点
TaskTracker:负责执行主节点JobTracker分配的任务
4.2、2.x的版本架构模型介绍
第一种:NameNode与ResourceManager单节点架构模型
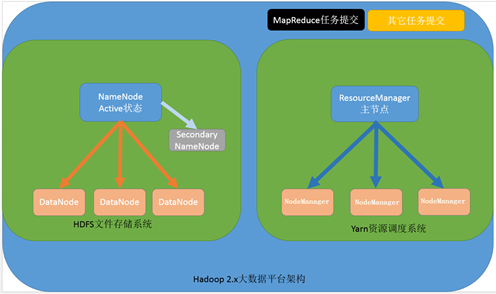
文件系统核心模块:
NameNode:集群当中的主节点,主要用于管理集群当中的各种数据
secondaryNameNode:主要能用于hadoop当中元数据信息的辅助管理
DataNode:集群当中的从节点,主要用于存储集群当中的各种数据
数据计算核心模块:
ResourceManager:接收用户的计算请求任务,并负责集群的资源分配
NodeManager:负责执行主节点APPmaster分配的任务
第二种:NameNode单节点与ResourceManager高可用架构模型

文件系统核心模块:
NameNode:集群当中的主节点,主要用于管理集群当中的各种数据
secondaryNameNode:主要能用于hadoop当中元数据信息的辅助管理
DataNode:集群当中的从节点,主要用于存储集群当中的各种数据
数据计算核心模块:
ResourceManager:接收用户的计算请求任务,并负责集群的资源分配,以及计算任务的划分,通过zookeeper实现ResourceManager的高可用
NodeManager:负责执行主节点ResourceManager分配的任务
第三种:NameNode高可用与ResourceManager单节点架构模型
文件系统核心模块:
NameNode:集群当中的主节点,主要用于管理集群当中的各种数据,其中nameNode可以有两个,形成高可用状态
DataNode:集群当中的从节点,主要用于存储集群当中的各种数据
JournalNode:文件系统元数据信息管理
数据计算核心模块:
ResourceManager:接收用户的计算请求任务,并负责集群的资源分配,以及计算任务的划分
NodeManager:负责执行主节点ResourceManager分配的任务
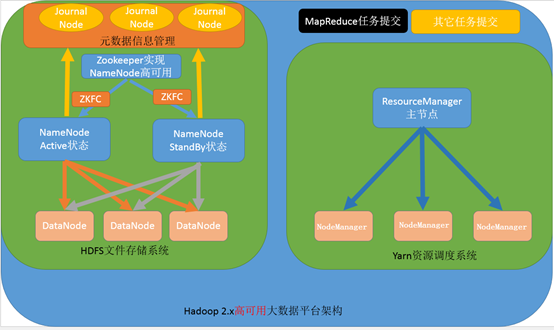
第四种:NameNode与ResourceManager高可用架构模型
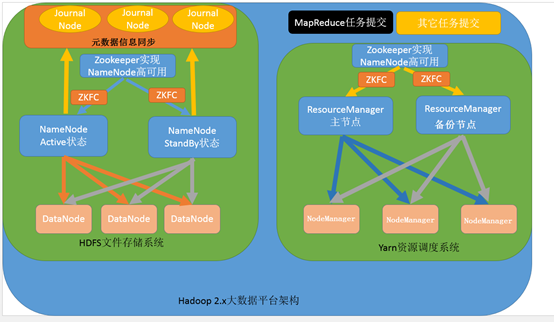
文件系统核心模块:
NameNode:集群当中的主节点,主要用于管理集群当中的各种数据,一般都是使用两个,实现HA高可用
JournalNode:元数据信息管理进程,一般都是奇数个
DataNode:从节点,用于数据的存储
数据计算核心模块:
ResourceManager:Yarn平台的主节点,主要用于接收各种任务,通过两个,构建成高可用
NodeManager:Yarn平台的从节点,主要用于处理ResourceManager分配的任务
Hadoop简介及架构的更多相关文章
- NO.1 hadoop简介
第一次接触这个时候在网上查了很多讲解,以下很多只是来自网络. 1.Hadoop (1)Hadoop简介 Hadoop是一个分布式系统基础架构,由Apache基金会开发.用户可以在不了解分布式底层 ...
- Hadoop简介与分布式安装
Hadoop的基本概念和分布式安装: Hadoop 简介 Hadoop 是Apache Lucene创始人道格·卡丁(Doug Cutting)创建的,Lucene是一个应用广泛的文本搜索库,Hado ...
- 1 预备知识--Hadoop简介
1 预备知识--Hadoop简介 Hadoop是Apache的一个开源的分布式计算平台,以HDFS分布式文件系统和MapReduce分布式计算框架为核心,为用户提供了一套底层透明的分布式基础设施Had ...
- Amazon EMR(Elastic MapReduce):亚马逊Hadoop托管服务运行架构&Hadoop云服务之战:微软vs.亚马逊
http://s3tools.org/s3cmd Amazon Elastic MapReduce (Amazon EMR)简介 Amazon Elastic MapReduce (Amazon EM ...
- Hadoop1-认识Hadoop大数据处理架构
一.简介概述 1.什么是Hadoop Hadoop是Apache软件基金会旗下的一个开源分布式计算平台,为用户提供了系统底层细节透明的分布式基础架构 Hadoop是基于java语言开发,具有很好的跨平 ...
- java大数据最全课程学习笔记(1)--Hadoop简介和安装及伪分布式
Hadoop简介和安装及伪分布式 大数据概念 大数据概论 大数据(Big Data): 指无法在一定时间范围内用常规软件工具进行捕捉,管理和处理的数据集合,是需要新处理模式才能具有更强的决策力,洞察发 ...
- Hadoop工程包架构解析
Hadoop源码解析 1 --- Hadoop工程包架构解析 1 Hadoop中各工程包依赖简述 Google的核心竞争技术是它的计算平台.Google的大牛们用了下面5篇文章,介绍了它们的计算 ...
- 基于hadoop的BI架构
BI系统,是企业利用数据驱动运营的一个典型系统.BI系统通过发掘企业运行过程中的数据,发现企业的潜在风险.为企业的各项决策提供数据支撑. 传统的BI系统通常构建于关系型数据库之上.随着企业业务量的增大 ...
- Hadoop:Hadoop简介及环境配置
http://blog.csdn.net/pipisorry/article/details/51243805 Hadoop简介 下次写上... 皮皮blog 配置hadoop环境可能出现的问题 每次 ...
随机推荐
- NOI2013 二叉查找树
题目链接:戳我 对于一个排序二叉树来讲,它的中序遍历对应的序列是可以确定的. 我们知道如果求一个访问频率最低的(也就是没有修改),直接就区间DP即可.\(dp[i][j]=min(dp[i][j],d ...
- UBUNTU 15.10 CAFFE安装教程(测试可用)
转帖:https://github.com/BVLC/caffe/wiki/Ubuntu-15.10-Installation-Guide Ubuntu 15.10 have been release ...
- python版本升级流程,升级2.7跟3.x版本流程一样
前言: 目前python2.6版本很多库已经不支持,在安装库的时候总会遇到很多装不上的事故,特别烦恼,所以以后不纠结,直接升级python版本后再使用,避免多次采坑:当然,未来趋势还是python3. ...
- java中MD5函数
import java.security.MessageDigest; import java.security.NoSuchAlgorithmException; public class MD5U ...
- AcWing:143. 最大异或对(01字典树 + 位运算 + 异或性质)
在给定的N个整数A1,A2……ANA1,A2……AN中选出两个进行xor(异或)运算,得到的结果最大是多少? 输入格式 第一行输入一个整数N. 第二行输入N个整数A1A1-ANAN. 输出格式 输出一 ...
- (转载)深入理解Java:内省(Introspector)
本文转载自:https://www.cnblogs.com/peida/archive/2013/06/03/3090842.html 一些概念: 内省(Introspector) 是Java 语言对 ...
- Error in render: "TypeError: Cannot read property 'url_img' of undefined"
如果我们 vue 组件中 template 里面添加了下标(靠数组索引得到的值),就会报索引为 undefined 解决方法: 在我们使用下标时,要在父组件上做条件判断,如果这个下标存在,然后就显示里 ...
- EBI架构 VS. MVC
和 MVC 模式中的 Model 代表着整个后端(包括所有实体.服务和它们之间的关系在内的一切)一样,EBI 模式将边界看作是和外部世界的完整连接,而不仅仅是一个视图.一个控制器或是一个接口(这里指的 ...
- Selenium 2自动化测试实战22(处理HTML5的视频播放)
一.处理HTML5的视频播放 大多数浏览器使用控件(如Flash)来播放视频,但是,不同的浏览器需要使用不同的插件.HTML5定义了一个新的元素<video>,指定了一个标准的方式来嵌入电 ...
- 点击其他区域关闭dialog
1.在打开dialog处阻止冒泡,在body click事件中关闭dialog2.不阻止冒泡,在body click事件中判断target是否为diallog或其子节点 在Safari浏览器中,在默认 ...