Mysql之表的查询
一、单表的查询
首先让我们先熟悉一下mysql语句在查询操作时执行的顺序:
(1)from
(2) on
(3) join
(4) where
(5)group by
(6) avg,sum....
(7)having
(8) select
(9) distinct
(10) order by
创建查询环境:
创建一个学生表:
create table stu(id int primary key auto_increment,name char(10) not null,gender enum('男','女'),age int not null);
插入数据:
insert into stu(name,gender,age) values ('小红','女','16'),('小明','男','18'),('小丽','女','17'),('月月','女','12'),('孙哥','男','28');
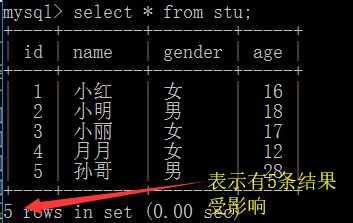
1.查询所有字段
select * from 表名;
注: * 表示所有字段
2.查询指定字段
select 字段1,字段2... from 表名;

3.查询指定记录
selec 字段 from 表名 where 约束条件

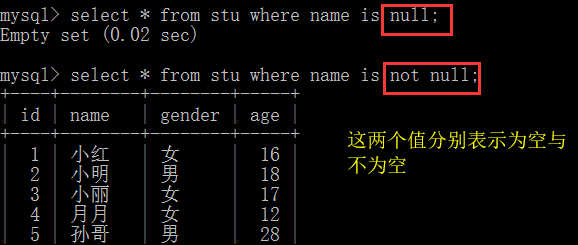
4.空值的查询
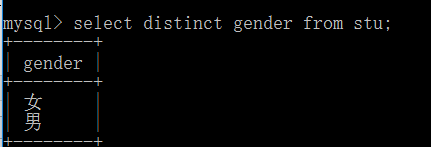
5.关键字查询in与distinct
in关键字:IN(xx,yy,...) 满足条件范围内的一个值即为匹配项

distinct让查询的结果不重复
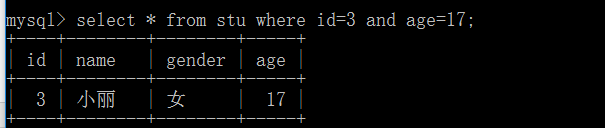
6.多条件查询and与or
and: 相当于"逻辑与",也就是说要同时满足条件才算匹配
or:相当于“逻辑或",也就是说只要满足其中一个条件,就算匹配上了,跟IN关键字效果差不多

7.范围查询between and
between ... and ... : 在...到...范围内的值即为匹配项,
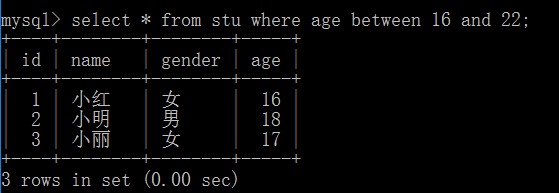
8.字符匹配查询like
like: 相当于模糊查询,和LIKE一起使用的通配符有 "%"与"_"
"%":作用是能匹配任意长度的字符。
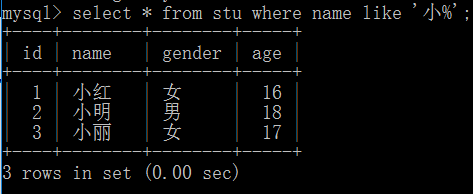
"_":只能匹配任意一个字符

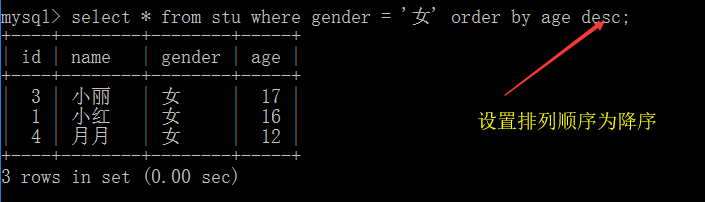
9.对查询结果排序order by
关键字 order by,有两个值供选择 desc 降序 、asc 升序(默认值)
不设置则为默认

desc
10.分组查询group by ※
分组查询作为查询中的重点难点在这里会详细解释说明一下,相信很多初学者在这里遇到过不少问题,希望你们在看了我的文章后能从中获得启发,
创建一个新的查询环境
创建课程表:
create table cou(cid int primary key auto_increment,cname char(20) not null,elenum int not null,teacher char(10) not null);
注:cid表示课程号;cname表示课程名;elenum:表示选课人数;teacher:表示授课教师;
向表中添加数据:
insert into cou(cname,elenum,teacher) values ('高等数学',67,'张红燕'),('大学物理',67,'李健民'),('大学外语',67,'王小丹'),('大学生安全教育',32,'吴菲'),('舌尖上的植物学',32,'老丁'),('体育',20,'高飞');

首先我们先对字段elenum进行分组
select elenum from cou group by elenuml;
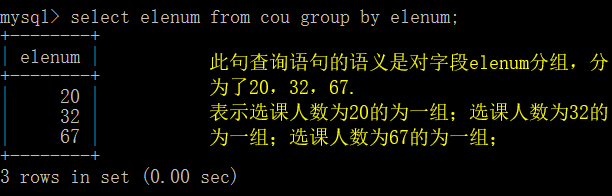
从图中可有看出将字段elenum分组后,分为了三个组20、32、67

11.筛选having
分组之后还进行条件过滤,将不想要的分组丢弃,使用关键字 having

12.限制查询LIMIT
LIMIT[位置偏移量] 行数 通过LIMIT可以选择数据库表中的任意行数

13.集合函数查询
集合函数查询包括:COUNT()函数、SUM()函数、AVG()函数、MAX()函数、MIN()函数
COUNT()函数:作用是统计数据表中包含的记录行的总数,或者根据查询结果返回列中包含的数据行数
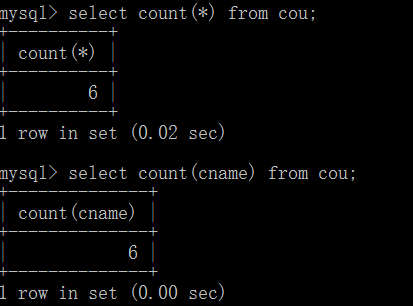
COUNT(*):计算表中的总的行数,不管某列有数值或者为空值,因为*就是代表查询表中所有的数据行
COUNT(字段名):计算该字段名下总的行数,计算时会忽略空值的行,也就是NULL值的行。
SUM()函数:作用是一个求总和的函数,返回指定列值的总和

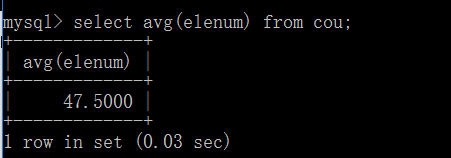
AVG()函数:作用是通过计算返回的行数和每一行数据的和,求的指定列数据的平均值
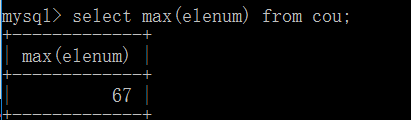
MAX()函数:作用是返回指定列中的最大值
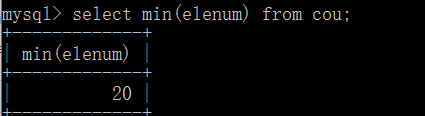
MIN()函数:作用是返回指定列中的最小值
二、多表的查询
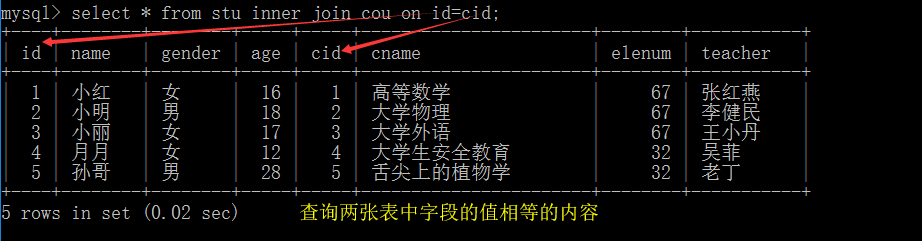
1.内链接查询
格式:表名 INNER JOIN 表名 ON 连接条件
2.外链接查询
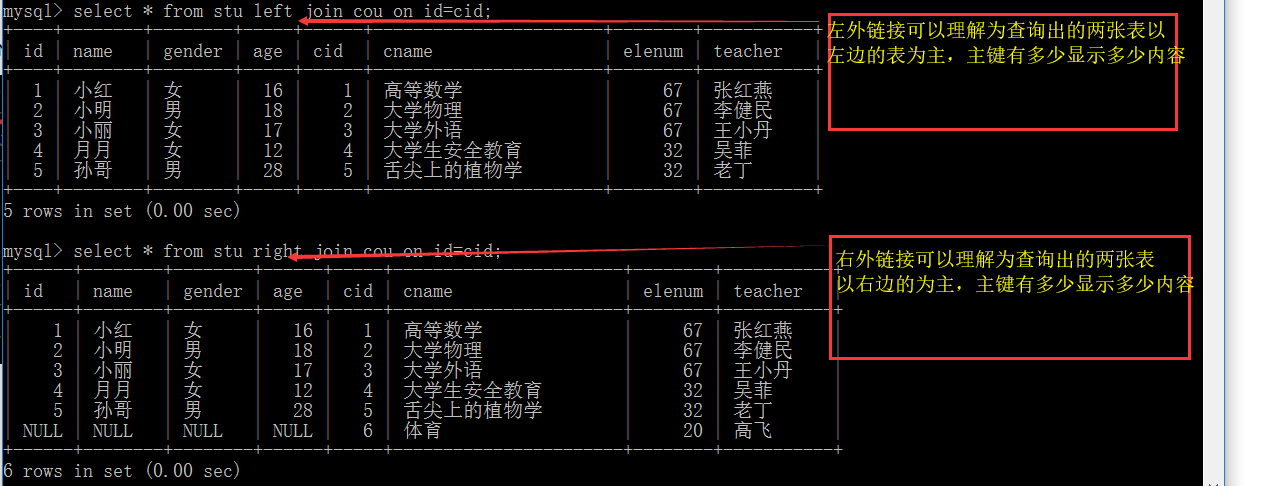
左外链接查询
格式:表名 LEFT JOIN 表名 ON 条件; 返回包括左表中的所有记录和右表中连接字段相等的记录
右外链接查询
格式:表名 RIGHT JOIN 表名 ON 条件 返回包括右表中的所有记录和右表中连接字段相等的记录
3.复合条件查询
在连接查询(内连接、外连接)的过程中,通过添加过滤条件,限制查询的结果,使查询的结果更加准确,通俗点讲,就是将连接查询时的条件更加细化。
举两个简单的例子:


三、子查询
子查询的意思就是将查询一张表得到的结果来充当另一个查询的条件,这样嵌套的查询就称为子查询。
需要注意的是在子查询完成后需要起一个别名,

as的使用方法就是写表或者派生表的后面+别名

1.关键字查询
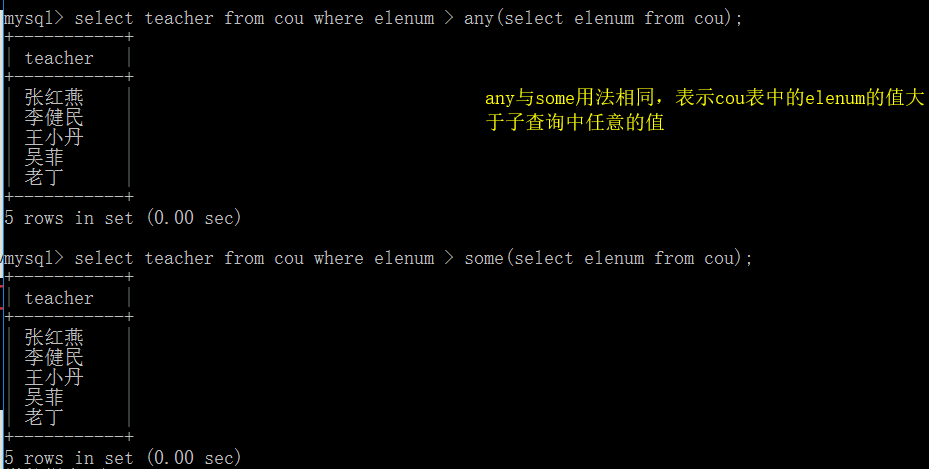
关键字ANY与SOME
ANY关键字与SOME关键字用法相同,都是接在一个比较操作符的后面,表示若与子查询返回的任何值比较为TRUE`
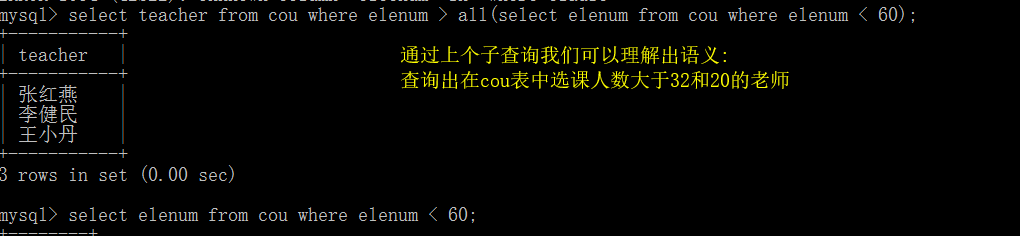
关键字AII
使用ALL时表示需要同时满足所有条件。
不太容易理解我们分步来做
先进行先子查询

在一起查询更容易理解:
关键字IN
IN关键字的作用跟上面单表查询的IN是一样的,不过这里IN中的参数放的是一个子查询语句。

四、合并结果查询
利用UNION关键字,可以将查询出的结果合并到一张结果集中,也就是通过UNION关键字将多条SELECT语句连接起来,注意,合并结果集,只是增加了表中的记录,并不是将表中的字段增加,仅仅是将记录行合并到一起。其显示的字段应该是相同的,不然不能合并。
UNION[ALL]的使用
UNION:不使用关键字ALL,执行的时候会删除重复的记录,所有返回的行度是唯一的,
UNION ALL:不删除重复航也不对结果进行自动排序。
格式:
SELECT 字段名,... FROM 表名
UNION[ALL]
SELECT 字段名,... FROM 表名

Mysql之表的查询的更多相关文章
- 【连接查询】mySql多表连接查询与union与union all用法
1.准备两个表 表a: 结构: mysql> desc a; +-------+-------------+------+-----+---------+-------+ | Field | T ...
- mysql数据库表的查询操作-总结
转自:https://www.cnblogs.com/whgk/p/6149009.html 序言 1.MySQL表操作(创建表,查询表结构,更改表字段等), 2.MySQL的数据类型(CHAR.VA ...
- MySQL多表数据查询(DQL)
数据准备: /* ------------------------------------创建班级表------------------------------------ */ CREATE TAB ...
- MySQL常用表结构查询语句
在我们使用数据库进行查询或者建表时,经常需要查看表结构,下面以employees数据库中的departments表为例进行表结构查询: departments表:(2列9行) +---------+- ...
- 最全MySQL数据库表的查询操作
序言 1.MySQL表操作(创建表,查询表结构,更改表字段等), 2.MySQL的数据类型(CHAR.VARCHAR.BLOB,等), 本节比较重要,对数据表数据进行查询操作,其中可能大家不熟悉的就对 ...
- MySQL多表关联查询数量
//多表关联查询数量select user, t1.count1, t2.count2from user tleft join ( select user_id, count(sport_type) ...
- JDBC MySQL 多表关联查询查询
public static void main(String[] args) throws Exception{ Class.forName("com.mysql.jdbc.Driver&q ...
- mysql多表联合查询
转自:http://www.cnblogs.com/Toolo/p/3634563.html 多表连接,小分三种(笛卡尔积.内连接.外连接),多分五种 (笛卡尔积.内连接.左连接.右连接.全连接(my ...
- Mysql 多表联合查询效率分析及优化
1. 多表连接类型 1. 笛卡尔积(交叉连接) 在MySQL中可以为CROSS JOIN或者省略CROSS即JOIN,或者使用',' 如: SELECT * FROM table1 CROSS JO ...
随机推荐
- Game and Application Protocol
This privacy policy details the information collected by the team ("we" or "our" ...
- 改进初学者的PID-手自动切换
最近看到了Brett Beauregard发表的有关PID的系列文章,感觉对于理解PID算法很有帮助,于是将系列文章翻译过来!在自我提高的过程中,也希望对同道中人有所帮助.作者Brett Beaure ...
- LeetCode_326. Power of Three
326. Power of Three Easy Given an integer, write a function to determine if it is a power of three. ...
- this page isn't working (ERR_EMPTY_RESPONSE)
特定情况触发了PHP的Call to undefined function(函数不存在)的Fatal error(致命错误),PHP异常终止执行,Apache收到PHP的异常信号时,认为PHP处理请求 ...
- Ubuntu18.04下LAMP环境搭建
可以安装安装Xampp,Xampp是一个集成的LAMP开发环境. 但是这只是对于一个刚安装好的系统来说的,但是很有可能我的电脑上面已经安装过Apache,或者安装过MySQL,或者安装过PHP了,或者 ...
- Ajax基本概念
一. Ajax 1. 什么是ajax Ajax: asynchronous javascript and xml (异步js和xml) 其是可以与服务器进行(异步/同步)交互的技术一. ajax ...
- python 线程队列LifoQueue-LIFO(36)
在 python线程队列Queue-FIFO 文章中已经介绍了 先进先出队列Queue,而今天给大家介绍的是第二种:线程队列LifoQueue-LIFO,数据先进后出类型,两者有什么区别呢? 一.队 ...
- HDU 1016Presentation Error
这是一道典型的DFS题目.幻想有n个箱子,每次都向箱子里扔一个数,(当然第一个是必定是1,因为题目要求按字典序输出).判断输出的条件就是,当我移动到第n+1个箱子的时候,就要return了,当然还要判 ...
- iphone订阅服务在那里取消
打开手机,找到设置,点击进去 往下拉,找到“APP Store与iTunes Store”点击进去,找到你的ID,再点击进去,输入你的密码 找到“订阅”这个选项,点击进去 进到里面后你会发 ...
- 十分钟快速入门 Python,看完即会,不用收藏!
本文以 Eric Matthes 的<Python编程:从入门到实践>为基础,以有一定其他语言经验的程序员视角,对书中内容提炼总结,化繁为简,将这本书的精髓融合成一篇10分钟能读完的文章. ...