部署Hadoop2.0高性能集群
废话不多说直接实战,部署Hadoop高性能集群:
拓扑图:
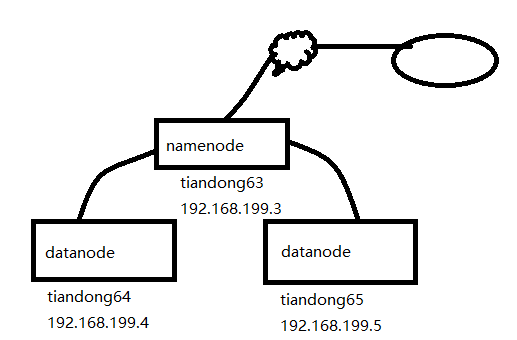
一、实验前期环境准备:
1、三台主机配置hosts文件:(复制到另外两台主机上)
[root@tiandong63 ~]# more /etc/hosts
192.168.199.3 tiandong63
192.168.199.4 tiandong64
192.168.199.5 tiandong65
2、创建Hadoop账号(另外两台主机上都的创建)
[root@tiandong63 ~]#useradd -u 8000 hadoop
[root@tiandong63 ~]#echo '123456' | passwd --stdin hadoop
3、给hadoop用户增加sudo权限,增加内容(另外两台主机上都得配置)
[root@tiandong63 ~]# vim /etc/sudoers
hadoop ALL=(ALL) ALL
4、主机互信(在tiandong63主机上)
可以ssh无密码登录机器tiandong63,tiandong64,tiandong65 ,方便后期复制文件和启动服务。因为namenode启动时,会连接到datanode上启动对应的服务。
[root@tiandong63 ~]# su - hadoop
[hadoop@tiandong63 ~]$ ssh-keygen
[hadoop@tiandong63 ~]$ ssh-copy-id root@192.168.199.4
[hadoop@tiandong63 ~]$ ssh-copy-id root@192.168.199.5
二、配置hadoop环境
1、配置jdk环境:(三台都的配置)
[root@tiandong63 ~]# ll jdk-8u191-linux-x64.tar.gz
-rw-r--r-- 1 root root 191753373 Dec 30 00:58 jdk-8u191-linux-x64.tar.gz
[root@tiandong63 ~]# tar zxvf jdk-8u191-linux-x64.tar.gz -C /usr/local/src/
[root@tiandong63 ~]# vim /etc/profile
export JAVA_HOME=/usr/local/src/jdk1.8.0_191
export JAVA_BIN=/usr/local/src/jdk1.8.0_191/bin
export PATH=${JAVA_HOME}/bin:$PATH
export CLASSPATH=.:${JAVA_HOME}/lib/dt.jar:${JAVA_HOME}/lib/tools.jar
export hadoop_root_logger=DEBUG,console
[root@tiandong63 ~]# source /etc/profile
2、关闭防火墙(三台都的关闭)
[root@tiandong63 ~]# /etc/init.d/iptables stop
3、在tiandong63安装Hadoop 并配置成namenode主节点
[root@tiandong63 ~]# cd /home/hadoop/
[root@tiandong63 hadoop]# ll hadoop-2.7.7.tar.gz
-rw-r--r-- 1 hadoop hadoop 218720521 Dec 29 21:11 hadoop-2.7.7.tar.gz
[root@tiandong63 ~]# su - hadoop
[hadoop@tiandong63 ~]$ tar -zxvf hadoop-2.7.7.tar.gz
创建hadoop相关的工作目录:
[hadoop@tiandong63 ~]$ mkdir -p /home/hadoop/dfs/name/ /home/hadoop/dfs/data/^Chome/hadoop/tmp/
4、配置hadoop(修改7个配置文件)
文件名称:hadoop-env.sh、yarn-evn.sh、slaves、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml
[hadoop@tiandong63 ~]$ cd /home/hadoop/hadoop-2.7.7/etc/hadoop/
[hadoop@tiandong63 hadoop]$ vim hadoop-env.sh 指定hadoop的Java运行环境
25 export JAVA_HOME=/usr/local/src/jdk1.8.0_191
[hadoop@tiandong63 hadoop]$ vim yarn-env.sh 指定yarn框架的java运行环境
26 JAVA_HOME=/usr/local/src/jdk1.8.0_191
[hadoop@tiandong63 hadoop]$ vim slaves 指定datanode 数据存储服务器
tiandong64
tiandong65
[hadoop@tiandong63 hadoop]$ vim core-site.xml 指定访问hadoop web界面访问路径
19 <configuration>
20 <property>
21 <name>fs.defaultFS</name>
22 <value>hdfs://tiandong63:9000</value>
23 </property>
24
25 <property>
26 <name>io.file.buffer.size</name>
27 <value>131072</value>
28 </property>
29
30 <property>
31 <name>hadoop.tmp.dir</name>
32 <value>file:/home/hadoop/tmp</value>
33 <description>Abase for other temporary directories.</description>
34 </property>
35 </configuration>
[hadoop@tiandong63 hadoop]$ mkdir -p /home/hadoop/tmp
[hadoop@tiandong63 hadoop]$ vim hdfs-site.xml
hdfs的配置文件,dfs.http.address配置了hdfs的http的访问位置,dfs.replication配置了文件块的副本数,一般不大于从机的个数。
19 <configuration>
20 <property>
21 <name>dfs.namenode.secondary.http-address</name>
22 <value>tiandong63:9001</value>
23 </property>
24
25 <property>
26 <name>dfs.namenode.name.dir</name>
27 <value>file:/home/hadoop/dfs/name</value>
28 </property>
29 <property>
30 <name>dfs.datanode.data.dir</name>
31 <value>file:/home/hadoop/dfs/data</value>
32 </property>
33
34 <property>
35 <name>dfs.replication</name>
36 <value>2</value>
37 </property>
38
39 <property>
40 <name>dfs.webhdfs.enabled</name>
41 <value>true</value>
42 </property>
43 </configuration>
[hadoop@tiandong63 hadoop]$ vim mapred-site.xml
19 <configuration>
20 <property>
21 <name>mapreduce.framework.name</name>
22 <value>yarn</value>
23 </property>
24
25 <property>
26 <name>mapreduce.jobhistory.address</name>
27 <value>tiandong63:10020</value>
28 </property>
29
30 <property>
31 <name>mapreduce.jobhistory.webapp.address</name>
32 <value>tiandong:19888</value>
33 </property>
34 </configuration>
[hadoop@tiandong63 hadoop]$ vim yarn-site.xml 该文件为yarn框架的配置,主要是一些任务的启动位置
15 <configuration>
16
17 <!-- Site specific YARN configuration properties -->
18 <property>
19 <name>yarn.nodemanager.aux-services</name>
20 <value>mapreduce_shuffle</value>
21 </property>
22
23 <property>
24 <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
25 <value>org.apache.hadoop.mapred.ShuffleHandler</value>
26 </property>
27
28 <property>
29 <name>yarn.resourcemanager.address</name>
30 <value>tiandong63:8032</value>
31 </property>
32
33 <property>
34 <name>yarn.resourcemanager.scheduler.address</name>
35 <value>tiandong63:8030</value>
36 </property>
37
38 <property>
39 <name>yarn.resourcemanager.resource-tracker.address</name>
40 <value>tiandong63:8031</value>
41 </property>
42
43 <property>
44 <name>yarn.resourcemanager.admin.address</name>
45 <value>tiandong63:8033</value>
46 </property>
47
48 <property>
49 <name>yarn.resourcemanager.webapp.address</name>
50 <value>tiandong63:8088</value>
51 </property>
52 </configuration>
复制到其他datanode节点(192.168.199.4/5)
[hadoop@tiandong63 ~]$ scp -r /home/hadoop/hadoop-2.7.7 hadoop@tiandong64
[hadoop@tiandong63 ~]$ scp -r /home/hadoop/hadoop-2.7.7 hadoop@tiandong65
三、启动hadoop:
在tiandong63上面启动(使用hadoop用户)
1、格式化:
[hadoop@tiandong63 ~]$ cd /home/hadoop/hadoop-2.7.7/bin/
[hadoop@tiandong63 bin]$ ./hdfs nodename -format
2、启动hdfs:
[hadoop@tiandong63 ~]$ /home/hadoop/hadoop-2.7.7/sbin/start-dfs.sh
查看进程(tiandong63上面查看namenode):
[hadoop@tiandong63 ~]$ ps -axu | grep namenode --color
Warning: bad syntax, perhaps a bogus '-'? See /usr/share/doc/procps-3.2.8/FAQ
hadoop 42851 0.4 17.6 2762196 177412 ? Sl 18:13 1:26 /usr/local/src/jdk1.8.0_191/bin/java -Dproc_namenode -Xmx1000m -Djava.net.preferIPv4Stack=true -Dhadoop.log.dir=/home/hadoop/hadoop-2.7.7/logs -Dhadoop.log.file=hadoop.log -Dhadoop.home.dir=/home/hadoop/hadoop-2.7.7 -Dhadoop.id.str=hadoop -Dhadoop.root.logger=INFO,console -Djava.library.path=/home/hadoop/hadoop-2.7.7/lib/native -Dhadoop.policy.file=hadoop-policy.xml -Djava.net.preferIPv4Stack=true -Djava.net.preferIPv4Stack=true -Djava.net.preferIPv4Stack=true -Dhadoop.log.dir=/home/hadoop/hadoop-2.7.7/logs -Dhadoop.log.file=hadoop-hadoop-namenode-tiandong63.log -Dhadoop.home.dir=/home/hadoop/hadoop-2.7.7 -Dhadoop.id.str=hadoop -Dhadoop.root.logger=INFO,RFA -Djava.library.path=/home/hadoop/hadoop-2.7.7/lib/native -Dhadoop.policy.file=hadoop-policy.xml -Djava.net.preferIPv4Stack=true -Dhadoop.security.logger=INFO,RFAS -Dhdfs.audit.logger=INFO,NullAppender -Dhadoop.security.logger=INFO,RFAS -Dhdfs.audit.logger=INFO,NullAppender -Dhadoop.security.logger=INFO,RFAS -Dhdfs.audit.logger=INFO,NullAppender -Dhadoop.security.logger=INFO,RFAS org.apache.hadoop.hdfs.server.namenode.NameNode
hadoop 43046 0.2 13.3 2733336 134344 ? Sl 18:13 0:35 /usr/local/src/jdk1.8.0_191/bin/java -Dproc_secondarynamenode -Xmx1000m -Djava.net.preferIPv4Stack=true -Dhadoop.log.dir=/home/hadoop/hadoop-2.7.7/logs -Dhadoop.log.file=hadoop.log -Dhadoop.home.dir=/home/hadoop/hadoop-2.7.7 -Dhadoop.id.str=hadoop -Dhadoop.root.logger=INFO,console -Djava.library.path=/home/hadoop/hadoop-2.7.7/lib/native -Dhadoop.policy.file=hadoop-policy.xml -Djava.net.preferIPv4Stack=true -Djava.net.preferIPv4Stack=true -Djava.net.preferIPv4Stack=true -Dhadoop.log.dir=/home/hadoop/hadoop-2.7.7/logs -Dhadoop.log.file=hadoop-hadoop-secondarynamenode-tiandong63.log -Dhadoop.home.dir=/home/hadoop/hadoop-2.7.7 -Dhadoop.id.str=hadoop -Dhadoop.root.logger=INFO,RFA -Djava.library.path=/home/hadoop/hadoop-2.7.7/lib/native -Dhadoop.policy.file=hadoop-policy.xml -Djava.net.preferIPv4Stack=true -Dhadoop.security.logger=INFO,RFAS -Dhdfs.audit.logger=INFO,NullAppender -Dhadoop.security.logger=INFO,RFAS -Dhdfs.audit.logger=INFO,NullAppender -Dhadoop.security.logger=INFO,RFAS -Dhdfs.audit.logger=INFO,NullAppender -Dhadoop.security.logger=INFO,RFAS org.apache.hadoop.hdfs.server.namenode.SecondaryNameNode
在tiandong64和tiandong65上面查看进程(datanode)
[root@tiandong64 ~]# ps -aux|grep datanode
Warning: bad syntax, perhaps a bogus '-'? See /usr/share/doc/procps-3.2.8/FAQ
hadoop 3938 0.3 12.2 2757576 122592 ? Sl 18:13 1:04 /usr/local/src/jdk1.8.0_191/bin/java -Dproc_datanode -Xmx1000m -Djava.net.preferIPv4Stack=true -Dhadoop.log.dir=/home/hadoop/hadoop-2.7.7/logs -Dhadoop.log.file=hadoop.log -Dhadoop.home.dir=/home/hadoop/hadoop-2.7.7 -Dhadoop.id.str=hadoop -Dhadoop.root.logger=INFO,console -Djava.library.path=/home/hadoop/hadoop-2.7.7/lib/native -Dhadoop.policy.file=hadoop-policy.xml -Djava.net.preferIPv4Stack=true -Djava.net.preferIPv4Stack=true -Djava.net.preferIPv4Stack=true -Dhadoop.log.dir=/home/hadoop/hadoop-2.7.7/logs -Dhadoop.log.file=hadoop-hadoop-datanode-tiandong64.log -Dhadoop.home.dir=/home/hadoop/hadoop-2.7.7 -Dhadoop.id.str=hadoop -Dhadoop.root.logger=INFO,RFA -Djava.library.path=/home/hadoop/hadoop-2.7.7/lib/native -Dhadoop.policy.file=hadoop-policy.xml -Djava.net.preferIPv4Stack=true -server -Dhadoop.security.logger=ERROR,RFAS -Dhadoop.security.logger=ERROR,RFAS -Dhadoop.security.logger=ERROR,RFAS -Dhadoop.security.logger=INFO,RFAS org.apache.hadoop.hdfs.server.datanode.DataNode
3、启动yarn(在tiandong63上面,即启动分布式计算):
[hadoop@tiandong63 ~]$ /home/hadoop/hadoop-2.7.7/sbin/start-yarn.sh
在tiandong63上面查看进程(resourcemanager进程)
[hadoop@tiandong63 ~]$ ps -ef|grep resourcemanager --color
hadoop 43196 1 0 18:14 pts/1 00:02:55 /usr/local/src/jdk1.8.0_191/bin/java -Dproc_resourcemanager -Xmx1000m -Dhadoop.log.dir=/home/hadoop/hadoop-2.7.7/logs -Dyarn.log.dir=/home/hadoop/hadoop-2.7.7/logs -Dhadoop.log.file=yarn-hadoop-resourcemanager-tiandong63.log -Dyarn.log.file=yarn-hadoop-resourcemanager-tiandong63.log -Dyarn.home.dir= -Dyarn.id.str=hadoop -Dhadoop.root.logger=INFO,RFA -Dyarn.root.logger=INFO,RFA -Djava.library.path=/home/hadoop/hadoop-2.7.7/lib/native -Dyarn.policy.file=hadoop-policy.xml -Dhadoop.log.dir=/home/hadoop/hadoop-2.7.7/logs -Dyarn.log.dir=/home/hadoop/hadoop-2.7.7/logs -Dhadoop.log.file=yarn-hadoop-resourcemanager-tiandong63.log -Dyarn.log.file=yarn-hadoop-resourcemanager-tiandong63.log -Dyarn.home.dir=/home/hadoop/hadoop-2.7.7 -Dhadoop.home.dir=/home/hadoop/hadoop-2.7.7 -Dhadoop.root.logger=INFO,RFA -Dyarn.root.logger=INFO,RFA -Djava.library.path=/home/hadoop/hadoop-2.7.7/lib/native -classpath /home/hadoop/hadoop-2.7.7/etc/hadoop:/home/hadoop/hadoop-2.7.7/etc/hadoop:/home/hadoop/hadoop-2.7.7/etc/hadoop:/home/hadoop/hadoop-2.7.7/share/hadoop/common/lib/*:/home/hadoop/hadoop-2.7.7/share/hadoop/common/*:/home/hadoop/hadoop-2.7.7/share/hadoop/hdfs:/home/hadoop/hadoop-2.7.7/share/hadoop/hdfs/lib/*:/home/hadoop/hadoop-2.7.7/share/hadoop/hdfs/*:/home/hadoop/hadoop-2.7.7/share/hadoop/yarn/lib/*:/home/hadoop/hadoop-2.7.7/share/hadoop/yarn/*:/home/hadoop/hadoop-2.7.7/share/hadoop/mapreduce/lib/*:/home/hadoop/hadoop-2.7.7/share/hadoop/mapreduce/*:/contrib/capacity-scheduler/*.jar:/contrib/capacity-scheduler/*.jar:/contrib/capacity-scheduler/*.jar:/contrib/capacity-scheduler/*.jar:/home/hadoop/hadoop-2.7.7/share/hadoop/yarn/*:/home/hadoop/hadoop-2.7.7/share/hadoop/yarn/lib/*:/home/hadoop/hadoop-2.7.7/etc/hadoop/rm-config/log4j.properties org.apache.hadoop.yarn.server.resourcemanager.ResourceManager
在tiandong64和tiandong65上面查看进程(nodemanager)
[root@tiandong64 ~]# ps -aux|grep nodemanager --color
Warning: bad syntax, perhaps a bogus '-'? See /usr/share/doc/procps-3.2.8/FAQ
hadoop 4048 0.5 15.7 2802552 158380 ? Sl 18:14 1:42 /usr/local/src/jdk1.8.0_191/bin/java -Dproc_nodemanager -Xmx1000m -Dhadoop.log.dir=/home/hadoop/hadoop-2.7.7/logs -Dyarn.log.dir=/home/hadoop/hadoop-2.7.7/logs -Dhadoop.log.file=yarn-hadoop-nodemanager-tiandong64.log -Dyarn.log.file=yarn-hadoop-nodemanager-tiandong64.log -Dyarn.home.dir= -Dyarn.id.str=hadoop -Dhadoop.root.logger=INFO,RFA -Dyarn.root.logger=INFO,RFA -Djava.library.path=/home/hadoop/hadoop-2.7.7/lib/native -Dyarn.policy.file=hadoop-policy.xml -server -Dhadoop.log.dir=/home/hadoop/hadoop-2.7.7/logs -Dyarn.log.dir=/home/hadoop/hadoop-2.7.7/logs -Dhadoop.log.file=yarn-hadoop-nodemanager-tiandong64.log -Dyarn.log.file=yarn-hadoop-nodemanager-tiandong64.log -Dyarn.home.dir=/home/hadoop/hadoop-2.7.7 -Dhadoop.home.dir=/home/hadoop/hadoop-2.7.7 -Dhadoop.root.logger=INFO,RFA -Dyarn.root.logger=INFO,RFA -Djava.library.path=/home/hadoop/hadoop-2.7.7/lib/native -classpath /home/hadoop/hadoop-2.7.7/etc/hadoop:/home/hadoop/hadoop-2.7.7/etc/hadoop:/home/hadoop/hadoop-2.7.7/etc/hadoop:/home/hadoop/hadoop-2.7.7/share/hadoop/common/lib/*:/home/hadoop/hadoop-2.7.7/share/hadoop/common/*:/home/hadoop/hadoop-2.7.7/share/hadoop/hdfs:/home/hadoop/hadoop-2.7.7/share/hadoop/hdfs/lib/*:/home/hadoop/hadoop-2.7.7/share/hadoop/hdfs/*:/home/hadoop/hadoop-2.7.7/share/hadoop/yarn/lib/*:/home/hadoop/hadoop-2.7.7/share/hadoop/yarn/*:/home/hadoop/hadoop-2.7.7/share/hadoop/mapreduce/lib/*:/home/hadoop/hadoop-2.7.7/share/hadoop/mapreduce/*:/contrib/capacity-scheduler/*.jar:/contrib/capacity-scheduler/*.jar:/home/hadoop/hadoop-2.7.7/share/hadoop/yarn/*:/home/hadoop/hadoop-2.7.7/share/hadoop/yarn/lib/*:/home/hadoop/hadoop-2.7.7/etc/hadoop/nm-config/log4j.properties org.apache.hadoop.yarn.server.nodemanager.NodeManager
注意:start-dfs和start-yarn.sh这两个脚本可以使用start-all.sh代替
4、查看HDFS分布式文件系统状态
[hadoop@tiandong63 ~]$ /home/hadoop/hadoop-2.7.7/bin/hdfs dfsadmin -report
四、hadoop的简单使用
运行hadoop计算任务,word count字数统计
在HDFS上创建文件夹:
[hadoop@tiandong63 ~]$ /home/hadoop/hadoop-2.7.7/bin/hadoop fs -mkdir /test/input
查看文件夹:
[hadoop@tiandong63 ~]$ /home/hadoop/hadoop-2.7.7/bin/hadoop fs -ls /test/
drwxr-xr-x - hadoop supergroup 0 2018-12-30 21:40 /test/input
上传文件:
创建一个计算的文件:
[hadoop@tiandong63 ~]$ more file1.txt
welcome to beijing
my name is thunder
what is your name
上传到HDFS的/test/input文件夹中
[hadoop@tiandong63 ~]$ /home/hadoop/hadoop-2.7.7/bin/hadoop fs -put /home/hadoop/file1.txt /test/input
查看是否上传成功:
[hadoop@tiandong63 ~]$ /home/hadoop/hadoop-2.7.7/bin/hadoop fs -ls /test/input
Found 1 items
-rw-r--r-- 2 hadoop supergroup 56 2018-12-30 21:40 /test/input/file1.txt
计算:
[hadoop@tiandong63 ~]$ /home/hadoop/hadoop-2.7.7/bin/hadoop jar /home/hadoop/hadoop-2.7.7/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount /test/input /test/output
查看运行结果:
[hadoop@tiandong63 ~]$ /home/hadoop/hadoop-2.7.7/bin/hadoop fs -cat /test/output/part-r-00000
beijing 1
is 2
my 1
name 2
thunder 1
to 1
welcome 1
what 1
your 1
部署Hadoop2.0高性能集群的更多相关文章
- Hadoop2.0 HA集群搭建步骤
上一次搭建的Hadoop是一个伪分布式的,这次我们做一个用于个人的Hadoop集群(希望对大家搭建集群有所帮助): 集群节点分配: Park01 Zookeeper NameNode (active) ...
- 部署hadoop2.7.2 集群 基于zookeeper配置HDFS HA+Federation
转自:http://www.2cto.com/os/201605/510489.html hadoop1的核心组成是两部分,即HDFS和MapReduce.在hadoop2中变为HDFS和Yarn.新 ...
- CentOS7 部署 ElasticSearch7.0.1 集群
环境 主机名 IP 操作系统 ES 版本 test1 192.168.1.2 CentOS7.5 7.0.1 test2 192.168.1.3 CentOS7.5 7.0.1 test3 192.1 ...
- centos7多节点部署redis4.0.11集群
1.服务器集群服务器 redis节点node-i(192.168.0.168) 7001,7002node-ii(192.168.0.169) 7003,7004node-iii(192.168.0. ...
- 基于Hadoop2.7.3集群数据仓库Hive1.2.2的部署及使用
基于Hadoop2.7.3集群数据仓库Hive1.2.2的部署及使用 HBase是一种分布式.面向列的NoSQL数据库,基于HDFS存储,以表的形式存储数据,表由行和列组成,列划分到列族中.HBase ...
- hbase-2.0.4集群部署
hbase-2.0.4集群部署 1. 集群节点规划: rzx1 HMaster,HRegionServer rzx2 HRegionServer rzx3 HRegionServer 前提:搭建好ha ...
- kubeadm部署kubernetes-1.12.0 HA集群-ipvs
一.概述 主要介绍搭建流程及使用注意事项,如果线上使用的话,请务必做好相关测试及压测. 1.基础环境准备 系统:ubuntu TLS 16.04 5台 docker-ce:17.06.2 kubea ...
- Hadoop2.X分布式集群部署
本博文集群搭建没有实现Hadoop HA,详细文档在后续给出,本次只是先给出大概逻辑思路. (一)hadoop2.x版本下载及安装 Hadoop 版本选择目前主要基于三个厂商(国外)如下所示: 基于A ...
- 新闻实时分析系统-Hadoop2.X分布式集群部署
(一)hadoop2.x版本下载及安装 Hadoop 版本选择目前主要基于三个厂商(国外)如下所示: 1.基于Apache厂商的最原始的hadoop版本, 所有发行版均基于这个版本进行改进. 2.基于 ...
随机推荐
- java关键知识汇总
1.泛型理解 2.java或Java框架中常用的注解及其作用详解 3.三层架构和MVC的区别 4.jdk1.8手册(提取码:bidm) 5.Rocketmq原理&最佳实践 6.spring入门 ...
- 最简单的一个win32程序
#include <windows.h> HINSTANCE g_hInst = NULL; //2 窗口处理函数 LRESULT CALLBACK WndProc( HWND hWnd, ...
- python读取ubuntu系统磁盘挂载情况
磁盘挂载 利用df -h 的命令 此功能主要实现了python 命令行执行函数进行解析df 返回的数据 代码如下 : # liunx 系统获取 磁盘挂载的情况 代码 #!/usr/bin/pyt ...
- 8.Mapper动态代理
在前面例子中自定义 Dao 接口实现类时发现一个问题:Dao 的实现类其实并没有干什么 实质性的工作, 它仅仅就是通过 SqlSession 的相关 API 定位到映射文件 mapper 中相应 id ...
- 11.SpringMVC注解式开发-处理器方法的返回值
处理器方法的返回值 使用@Controller 注解的处理器的处理器方法,其返回值常用的有四种类型 1.ModelAndView 2.String 3.void 4.自定义类型对象 1.返回Model ...
- JavaSpring【三、Bean】
配置项 id bean的标识 class bean的类全名 scope bean的作用域 constructor-arg 构造注入 properties 设值注入 autowire 装配模式 lazy ...
- Codeforces 845G Shortest Path Problem?
http://codeforces.com/problemset/problem/845/G 从顶点1dfs全图,遇到环则增加一种备选方案,环上的环不需要走到前一个环上作为条件,因为走完第二个环可以从 ...
- sed交换任意两行
命令: sed -n 'A{h;n;B!{:a;N;C!ba;x;H;n};x;H;x};p' 文件名 解释: A.B分别是需要交换的行,C是B-1 其中,A.B.C可以是行号,也可以通过匹配模式,如 ...
- shell脚本读取文件值并进行比较
#!/bin/bash keyValue=$(cat /dev/mcu/keyValue) //从文件中获取键值,注意:变量名和等号之间不能有空格 if [ $keyValue == 9 ] //注意 ...
- 05_Redis_List命令
一:Redis 列表(List) -- LinkedList Redis列表是简单的字符串列表,按照插入顺序排序.你可以添加一个元素到列表的头部(左边)或者尾部(右边):一个列表最多可以包含 232 ...