win10+pyspark+pycharm+anaconda单机环境搭建
一、工具准备
1. jdk1.8
2. scala
3. anaconda3
4. spark-2.3.1-bin-hadoop2.7
5. hadoop-2.8.3
6. winutils
7. pycharm
二、安装
1. jdk安装
oracle官网下载,安装后配置JAVA_HOME、CLASS_PATH,bin目录追加到PATH,注意:win10环境下PATH最好使用绝对路径!下同!

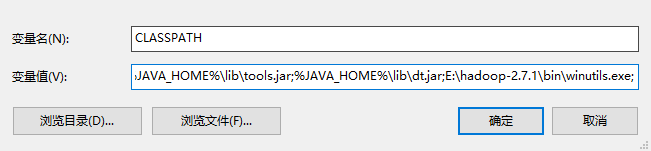
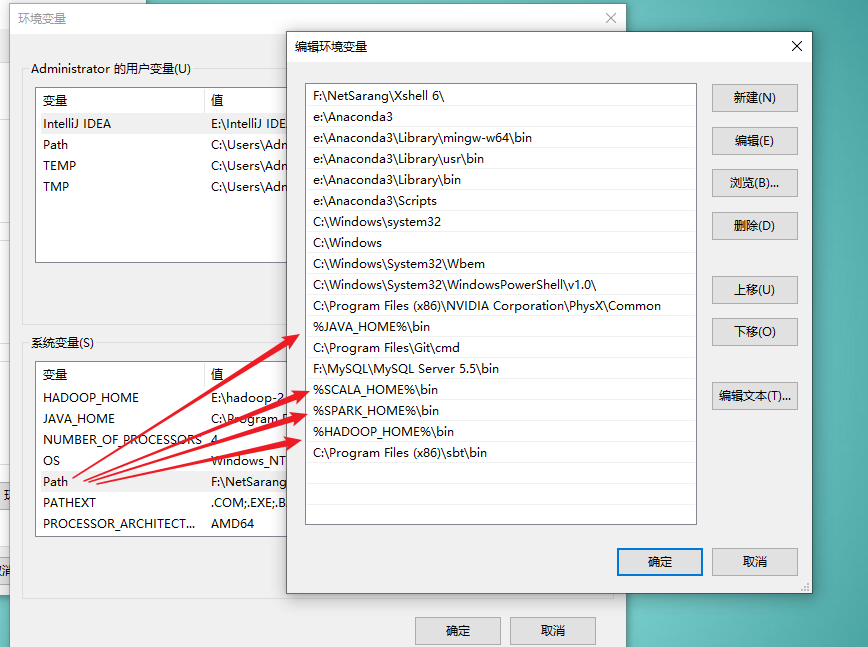
2. scala安装
官网下载,安装后配置SCALA_HOME,bin目录追加到PATH(上图包含)

3. anaconda3安装
官网下载,安装时注意在“追加到PATH”复选框打钩
4. spark安装
官网下载压缩包,解压缩后配置SPARK_HOME,bin目录追加到PATH(上图包含)
5. hadoop安装
官网下载版本>=spark对应hadoop版本,解压缩后配置HADOOP_HOME,bin目录追加到PATH(上图包含)
6. winutils安装
下载地址:https://github.com/steveloughran/winutils,按hadoop版本对应下载
7. pycharm安装
下载付费版本,使用lanyu注册码激活,注意按照提示添加域名解析到hosts文件
三、处理python相关
- 将pyspark文件夹(在spark-2.3.1-bin-hadoop2.7\python目录)复制到anaconda3\Lib\site-packages目录下
- 将winutils解压缩后用对应版本的bin目录替换hadoop下的bin目录
- conda install py4j
- 进入hadoop\bin目录下,以管理员方式打开cmd,输入命令:winutils.exe chmod 777 c:\tmp\Hive,若提示错误,检查Hive目录是否存在,若不存在,则手动创建,再重新执行命令
四、验证
打开pycharm,使用anaconda中的python作为解释器,输入以下代码并运行:
from pyspark import SparkContext
sc = SparkContext('local')
doc = sc.parallelize([['a', 'b', 'c'], ['b', 'd', 'd']])
words = doc.flatMap(lambda d: d).distinct().collect()
word_dict = {w: i for w, i in zip(words, range(len(words)))}
word_dict_b = sc.broadcast(word_dict)
def wordCountPerDoc(d):
dict = {}
wd = word_dict_b.value
for w in d:
if wd[w] in dict:
dict[wd[w]] += 1
else:
dict[wd[w]] = 1
return dict
print(doc.map(wordCountPerDoc).collect())
print("successful!")
运行结果:
[{0: 1, 1: 1, 2: 1}, {1: 1, 3: 2}]
successful!
本文为win10+pyspark+pycharm+anaconda的单机测试环境搭建。
win10+pyspark+pycharm+anaconda单机环境搭建的更多相关文章
- windows7 spark单机环境搭建及pycharm访问spark
windows7 spark单机环境搭建 follow this link how to run apache spark on windows7 pycharm 访问本机 spark 安装py4j ...
- [转载] Hadoop和Hive单机环境搭建
转载自http://blog.csdn.net/yfkiss/article/details/7715476和http://blog.csdn.net/yfkiss/article/details/7 ...
- win10子系统linux.ubuntu开发环境搭建
移步新博客... win10子系统linux.ubuntu开发环境搭建
- Kafka 0.7.2 单机环境搭建
Kafka 0.7.2 单机环境搭建当下载完Kafka后,进行解压,其目录结构如下: bin config contrib core DISCLAIMER examples lib lib_manag ...
- kafka单机环境搭建及其基本使用
最近在搞kettle整合kafka producer插件,于是自己搭建了一套单机的kafka环境,以便用于测试.现整理如下的笔记,发上来和大家分享.后续还会有kafka的研究笔记,依然会与大家分享! ...
- HBase单机环境搭建
在搭建HBase单机环境之前,首先你要保证你已经搭建好Java环境: $ java -version java version "1.8.0_51" Java(TM) SE Run ...
- Hadoop —— 单机环境搭建
一.前置条件 Hadoop的运行依赖JDK,需要预先安装,安装步骤见: Linux下JDK的安装 二.配置免密登录 Hadoop组件之间需要基于SSH进行通讯. 2.1 配置映射 配置ip地址和主机名 ...
- Solr单机环境搭建及部署
一.定义 官网的定义: Solr是基于Lucene构建的流行,快速,开放源代码的企业搜索平台.它具有高度的可靠性,可伸缩性和容错能力,可提供分布式索引,复制和负载平衡查询,自动故障转移和恢复,集中式配 ...
- hadoop单机环境搭建
[在此处输入文章标题] Hadoop单机搭建 1. 工具准备 1) Hadoop Linux安装包 2) VMware虚拟机 3) Java Linux安装包 4) Window 电脑一台 2. 开始 ...
随机推荐
- Syntax error: "(" unexpected shell里面的报错解决
author:headsen chen date : 2019-08-08 11:11:38 notice : 个人原创 Ubuntu上运行shell脚本总是报下面这个错误,在centos下面或者 ...
- Spark获取DataFrame中列的几种姿势--col,$,column,apply
1.doc上的解释(https://spark.apache.org/docs/2.1.0/api/java/org/apache/spark/sql/Column.html) df("c ...
- Java连接MongoDB报错“java.lang.IllegalArgumentException: clusterListener can not be null”的解决办法
我使用的MongoDB版本是3.6.9. 下面是一个很基础的示例代码,功能就是连接MongoDB: package com.zifeiy.snowflake.handle.etl.mongodb; i ...
- HTML布局水平导航条2制作
前两个博文导航条都不是铺满水平的浏览器的,很多导航条样式都是随着浏览器的移动,是100%.此外前两个博文导航条都是块状点击的,也就是给a标签加宽高,设置成块状显示,点击的时候不一定要点文字,只要点击该 ...
- SpringBoot学习笔记:动态数据源切换
SpringBoot学习笔记:动态数据源切换 数据源 Java的javax.sql.DataSource接口提供了一种处理数据库连接的标准方法.通常,DataSource使用URL和一些凭据来建立数据 ...
- Docker - 在CentOS7.5中升级Docker版本
1 - 检查当前版本 [root@localhost ~]# uname -a Linux localhost.localdomain 3.10.0-957.el7.x86_64 #1 SMP Thu ...
- 解释张量及TF的一些API
张量的定义 张量(Tensor)理论是数学的一个分支学科,在力学中有重要应用.张量这一术语起源于力学,它最初是用来表示弹性介质中各点应力状态的,后来张量理论发展成为力学和物理学的一个有力的数学工具.张 ...
- SELinux安全子系统的学习
SELinux(Security-Enhanced Linux)是美国国家安全局在 Linux 开源社区的帮助下开发的 一个强制访问控制(MAC,Mandatory Access Control)的安 ...
- python 工具的URL
Python取得大数据之后如何把数据图形化,之后让客户很清晰的看到你的结果 下面的图形化参照 matplotlib.3.0.2 https://matplotlib.org/gallery/index ...
- Ehcache配置文件ehcache.xml
<?xml version="1.0" encoding="UTF-8"?> <ehcache xmlns:xsi="http:// ...