044 HIVE中的几种排序
1、order by:全局排序
select * from emp order by sal;
对于一个reduce才有用。
2、sort by:对于每个reduce进行排序
set mapreduce.job.reduces=3;
这里设置了reduce为3。
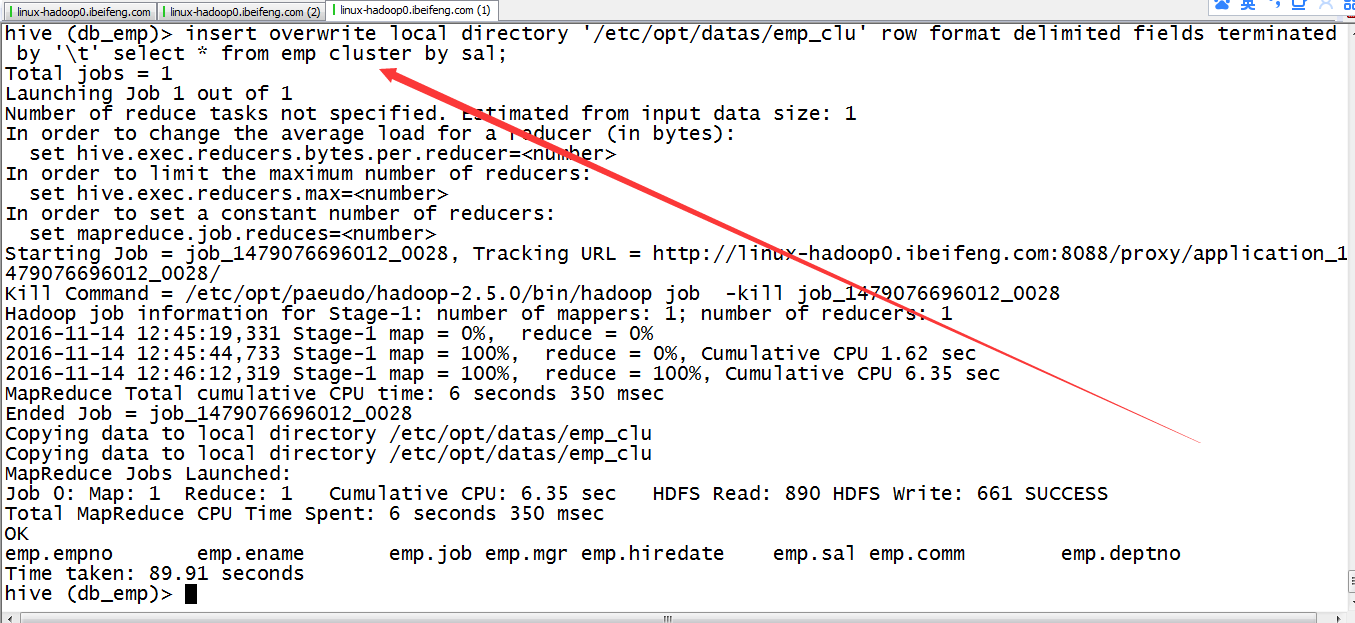
原本的结果放在控制台上,看的效果不是太清楚,所以将hive的结果到出到本文件。
insert overwrite local directory '/opt/datas/emp_sort' row format delimited fields terminated by '\t' select * from emp sort by sal;

结果:

3、distribute by :底层就是mapreduce 的分区,一般与sort by连用
先按照deptno进行分区,然后sort by每个reduce。
insert overwrite local directory '/opt/datas/emp_dis' row format delimited fields terminated by '\t' select * from emp distribute by deptno sort by sal;

4、cluster by:等价于distribute by 与sort by的字段相同时
分区与排序都是一个字段,可以使用这个。
应该说,这个是上面的一种特殊情况,我感觉可能会用的少一些。
insert overwrite local directory '/opt/datas/emp_cls' row format delimited fields terminated by '\t' select * from emp cluster by sal;
044 HIVE中的几种排序的更多相关文章
- Hive 中的四种排序详解,再也不会混淆用法了
Hive 中的四种排序 排序操作是一个比较常见的操作,尤其是在数据分析的时候,我们往往需要对数据进行排序,hive 中和排序相关的有四个关键字,今天我们就看一下,它们都是什么作用. 数据准备 下面我们 ...
- HIVE中的几种排序
1.order by:全局排序 select * from emp order by sal; 2.sort by:对于每个reduce进行排序 set mapreduce.job.reduces=3 ...
- 061 hive中的三种join与数据倾斜
一:hive中的三种join 1.map join 应用场景:小表join大表 一:设置mapjoin的方式: )如果有一张表是小表,小表将自动执行map join. 默认是true. <pro ...
- Hive中的三种不同的数据导出方式介绍
问题导读:1.导出本地文件系统和hdfs文件系统区别是什么?2.带有local命令是指导出本地还是hdfs文件系统?3.hive中,使用的insert与传统数据库insert的区别是什么?4.导出数据 ...
- hive中的一种假NULL现象
使用hive时,我们偶尔会遇到这样的问题,当你将结果输出到屏幕时,查出的数据往往显示为null,但是当你将结果输出到文本时,却显示为空(即未填充),这是为什么呢? 在hive中有一种假NULL,它看起 ...
- java数组中的三种排序方法中的冒泡排序方法
我记得我大学学java的时候,怎么就是搞不明白这三种排序方法,也一直不会,现在我有发过来学习下这三种方法并记录下来. 首先说说冒泡排序方法:冒泡排序方法就是把数组中的每一个元素进行比较,如果第i个元素 ...
- Hive中的一种假NULL
Hive中有种假NULL,它看起来和NULL一摸一样,但是实际却不是NULL. 例如如下这个查询: hive> desc ljn004; OK a string Time taken ...
- Hive中的4种Join方式
common join 普通join,性能较差,存在Shuffle map join 适用情况:大表join小表时,做不等值join 原理:将小表数据广播到各个节点,存储在内存中,在map阶段直接jo ...
- C语言中的七种排序算法
堆排序: void HeapAdjust(int *arraydata,int rootnode,int len) { int j; int t; *rootnode+<len) { j=*ro ...
随机推荐
- C# print2flash3文件转化
1.下载print2flash3 并且安装print2flash3 2.转换工具类 (1)需要导入using Print2Flash3; 这个程序集 using System; using Syste ...
- $_SERVER 当前信息
连接:https://www.cnblogs.com/mafeng/p/5868117.html $_SERVER['HTTP_ACCEPT_LANGUAGE']//浏览器语言 $_SERVER['R ...
- luogu P1641 [SCOI2010]生成字符串
传送门 代码极短 \(O(n^2)\)dp是设\(f_{i,j,k}\)表示前\(i\)位,放了\(j\)个1,后面还可以接着放\(k\)个0的方案,转移的话,如果放0,\(k\)就要减1,反之放了1 ...
- 给父元素与子元素分别设置visibility注意点
由于机顶盒的终端特性原因,不能用display:hidden去做隐藏,就选择了visibility:hidden. 在这里遇到一个现象: 给父元素设置了hidden,但是里面的子元素依然可见.以为只是 ...
- iOS视频流开发(2)—视频播放
承上篇,本篇文章主要介绍iOS视频播放需要用到的类.以及他们的使用场景和开发中遇到的问题. MPMoviePlayerViewController MP简介 iOS提供MPMoviePlayerCon ...
- Python3实现从文件中读取指定行的方法
from:http://www.jb51.net/article/66580.htm 这篇文章主要介绍了Python3实现从文件中读取指定行的方法,涉及Python中linecache模块操作文件的使 ...
- 【干货】从windows注册表读取重要信息-----这种技能非常重要,占电子取证的70%
也就是说,当我拿着U盘启动盘,从你电脑里面拷贝了注册表的几个文件,大部分数据就已经到我手中了.一起来感受一下吧. 来源:Unit 6: Windows File Systems and Registr ...
- C语言中,float在内存中的储存方式
浮点型变量在计算机内存中占用4字节(Byte),即32-bit. 遵循IEEE-754格式标准. 一个浮点数由2部分组成:底数m 和 指数e. ±mantissa × 2exponent (注意,公式 ...
- C# 多种方式连接Oracle。
废话不多说直接正题: 首先我们先在Oracle数据库下建了一个用户叫做lisi,密码为lisi,在这个用户下建立一张表叫做“USERS”,在这个表下新增三个数据. 方式一:利用OleDb连接Oracl ...
- 源码编译安装nginx1.4.7
传统上基于进程或线程模型架构的web服务通过每进程或每线程处理并发连接请求,这势必会在网络和I/O操作时产生阻塞,其另一个必然结果则是对内存或CPU的利用率低下.生成一个新的进程/线程需要事先备好其运 ...