pytorch中如何使用DataLoader对数据集进行批处理
最近搞了搞minist手写数据集的神经网络搭建,一个数据集里面很多个数据,不能一次喂入,所以需要分成一小块一小块喂入搭建好的网络。
pytorch中有很方便的dataloader函数来方便我们进行批处理,做了简单的例子,过程很简单,就像把大象装进冰箱里一共需要几步?
第一步:打开冰箱门。
我们要创建torch能够识别的数据集类型(pytorch中也有很多现成的数据集类型,以后再说)。
首先我们建立两个向量X和Y,一个作为输入的数据,一个作为正确的结果:

随后我们需要把X和Y组成一个完整的数据集,并转化为pytorch能识别的数据集类型:

我们来看一下这些数据的数据类型:

可以看出我们把X和Y通过Data.TensorDataset() 这个函数拼装成了一个数据集,数据集的类型是【TensorDataset】。
好了,第一步结束了,冰箱门打开了。
第二步:把大象装进去。
就是把上一步做成的数据集放入Data.DataLoader中,可以生成一个迭代器,从而我们可以方便的进行批处理。

DataLoader中也有很多其他参数:
dataset:Dataset类型,从其中加载数据
batch_size:int,可选。每个batch加载多少样本
shuffle:bool,可选。为True时表示每个epoch都对数据进行洗牌
sampler:Sampler,可选。从数据集中采样样本的方法。
num_workers:int,可选。加载数据时使用多少子进程。默认值为0,表示在主进程中加载数据。
collate_fn:callable,可选。
pin_memory:bool,可选
drop_last:bool,可选。True表示如果最后剩下不完全的batch,丢弃。False表示不丢弃。
好了,第二步结束了,大象装进去了。
第三步:把冰箱门关上。
好啦,现在我们就可以愉快的用我们上面定义好的迭代器进行训练啦。
在这里我们利用print来模拟我们的训练过程,即我们在这里对搭建好的网络进行喂入。

输出的结果是:
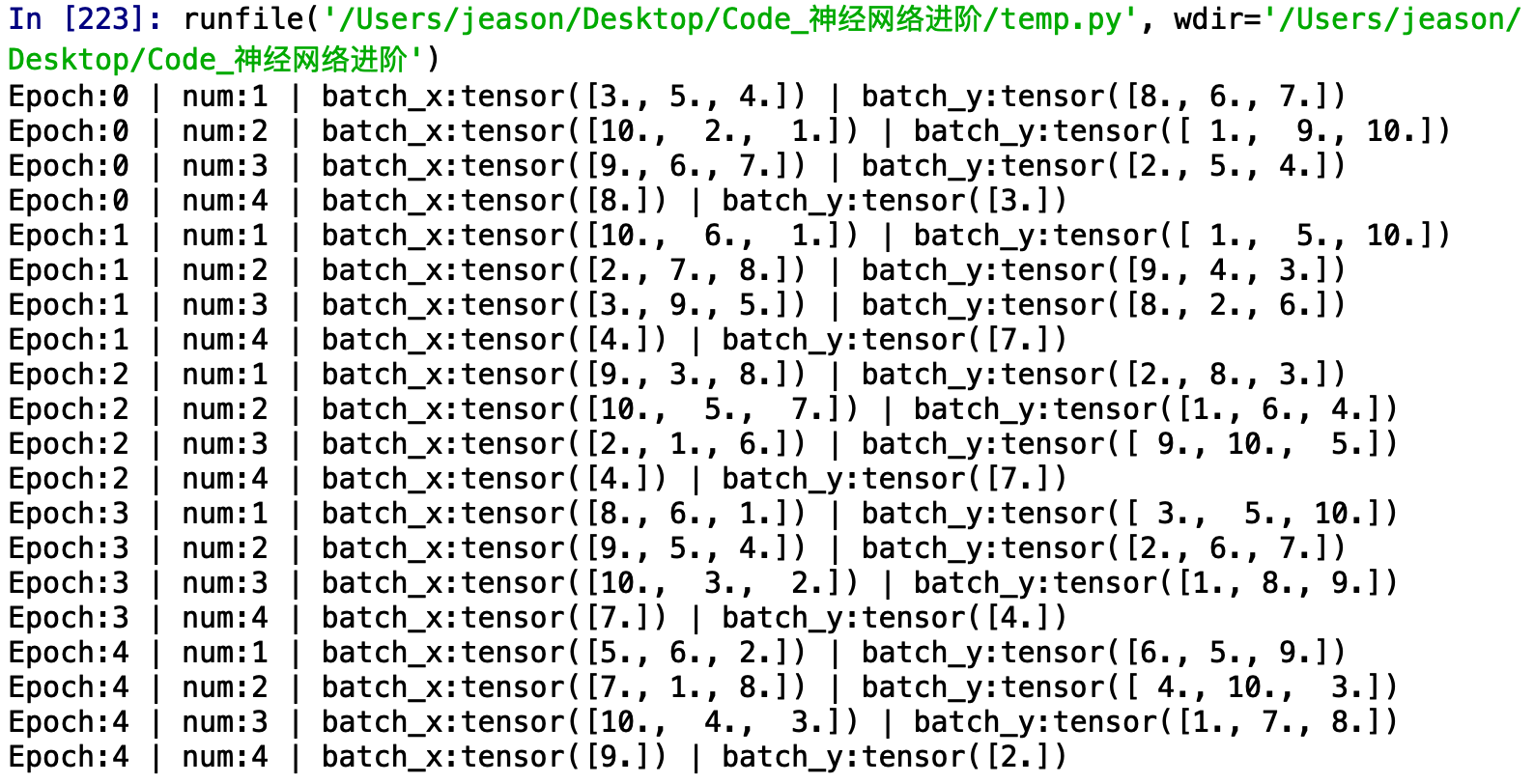
可以看到,我们一共训练了所有的数据训练了5次。数据中一共10组,我们设置的mini-batch是3,即每一次我们训练网络的时候喂入3组数据,到了最后一次我们只有1组数据了,比mini-batch小,我们就仅输出这一个。
此外,还可以利用python中的enumerate(),是对所有可以迭代的数据类型(含有很多东西的list等等)进行取操作的函数,用法如下:
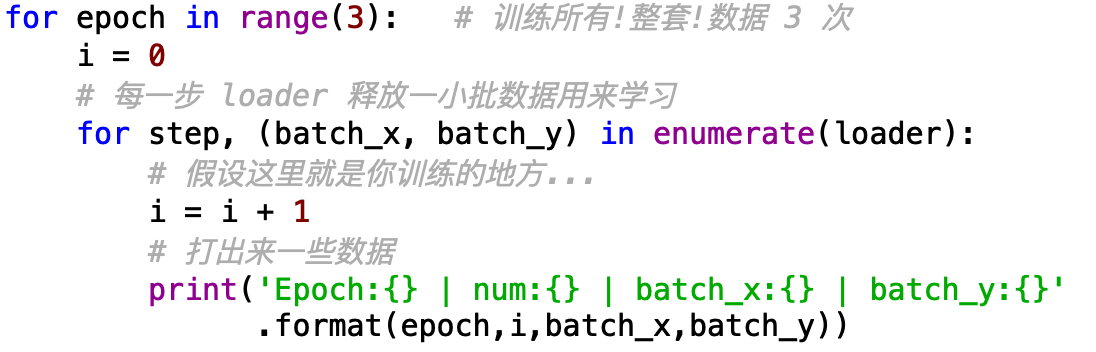
好啦,现在冰箱门就关上啦,(*^__^*)
pytorch中如何使用DataLoader对数据集进行批处理的更多相关文章
- pytorch Dataset数据集和Dataloader迭代数据集
import torch from torch.utils.data import Dataset,DataLoader class SmsDataset(Dataset): def __init__ ...
- pytorch中DataLoader, DataSet, Sampler之间的关系
转自:https://mp.weixin.qq.com/s/RTv0cUWvc0kuXBeNoXVu_A 自上而下理解三者关系 首先我们看一下DataLoader.__next__的源代码长什么样,为 ...
- PyTorch中的MIT ADE20K数据集的语义分割
PyTorch中的MIT ADE20K数据集的语义分割 代码地址:https://github.com/CSAILVision/semantic-segmentation-pytorch Semant ...
- pytorch中tensorboardX的用法
在代码中改好存储Log的路径 命令行中输入 tensorboard --logdir /home/huihua/NewDisk1/PycharmProjects/pytorch-deeplab-xce ...
- 转pytorch中训练深度神经网络模型的关键知识点
版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.csdn.net/weixin_42279044/articl ...
- [深度学习] pytorch利用Datasets和DataLoader读取数据
本文简单描述如果自定义dataset,代码并未经过测试(只是说明思路),为半伪代码.所有逻辑需按自己需求另外实现: 一.分析DataLoader train_loader = DataLoader( ...
- 第五章——Pytorch中常用的工具
2018年07月07日 17:30:40 __矮油不错哟 阅读数:221 1. 数据处理 数据加载 ImageFolder DataLoader加载数据 sampler:采样模块 1. 数据处理 ...
- pytorch加载语音类自定义数据集
pytorch对一下常用的公开数据集有很方便的API接口,但是当我们需要使用自己的数据集训练神经网络时,就需要自定义数据集,在pytorch中,提供了一些类,方便我们定义自己的数据集合 torch.u ...
- PyTorch中使用深度学习(CNN和LSTM)的自动图像标题
介绍 深度学习现在是一个非常猖獗的领域 - 有如此多的应用程序日复一日地出现.深入了解深度学习的最佳方法是亲自动手.尽可能多地参与项目,并尝试自己完成.这将帮助您更深入地掌握主题,并帮助您成为更好的深 ...
随机推荐
- Delphi+DBGrid导出Excel
uses ComObj; //DBGrid:指定的DBGrid;SaveFileName:要保存的文件名 function ExportDBGrid(DBGrid: TDBGrid; SaveFile ...
- UOJ #76 【UR #6】懒癌
确实是一道很不错的题啊. 题目链接 题意 感觉也没什么特别简洁的版本,大家直接看题面吧. 题解 我第一次看到这个类似问题的背景是疯狗,因此下面的题解不自觉的代入了...大家明白意思就好. 我们考虑对于 ...
- BZOJ1861[Zjoi2006]书架——非旋转treap
题目描述 小T有一个很大的书柜.这个书柜的构造有些独特,即书柜里的书是从上至下堆放成一列.她用1到n的正整数给每本书都编了号. 小T在看书的时候,每次取出一本书,看完后放回书柜然后再拿下一本.由于这些 ...
- PHP页面显示中文字符出现乱码
[出现问题] php页面显示中文字符出现乱码 [解决方法] 在php页面的代码前插入一行代码即可 header("Content-Type: text/html;charset=utf-8& ...
- 快乐的Lambda表达式(二)
转载:http://www.cnblogs.com/jesse2013/p/happylambda-part2.html 快乐的Lambda表达式 上一篇 背后的故事之 - 快乐的Lambda表达式( ...
- Python从入门到放弃系列(Django/Flask/爬虫)
第一篇 Django从入门到放弃 第二篇 Flask 第二篇 爬虫
- Codeforces Round #426 (Div. 2) A,B,C
A. The Useless Toy 题目链接:http://codeforces.com/contest/834/problem/A 思路: 水题 实现代码: #include<bits/st ...
- 【HDU 5363】Key Set(和为偶数的子集个数)
题 Description soda has a set $S$ with $n$ integers $\{1, 2, \dots, n\}$. A set is called key set if ...
- 【转】linux环境内存分配原理 malloc info
Linux的虚拟内存管理有几个关键概念: Linux 虚拟地址空间如何分布?malloc和free是如何分配和释放内存?如何查看堆内内存的碎片情况?既然堆内内存brk和sbrk不能直接释放,为什么不全 ...
- shell(1)-磁盘shell
查看硬盘的大小脚本[root@localhost ~]# vi repboot.sh#!/bin/bash# To show usage of /boot directory and mode of ...