使用neo4j-import工具导入数据
从Neo4j2.2版本开始,系统就自带了一个大数据量的导入工具:neo4j-import,可支持并行、可扩展的大规模csv数据导入(本例版本为:3.4.7版本)
1.前提条件
关闭neo4j
无法在原有数据库添加,只能重新生成一个数据库
导入文件格式为csv
2.参数说明
--into:数据库名称
--id-type string 指明生成节点、关系的主键类型为string类型
--bad-tolerance:能容忍的错误数据条数(即超过指定条数程序直接挂掉),默认1000
--multiline-fields:是否允许多行插入(即有些换行的数据也可读取)
--nodes:插入节点
--relationships:插入关系
3.例子
node.csv
id:ID(Company),name
100000001,戴上国
100000003,戴治宇
100000004,游振武
relation_header.csv
:START_ID(Company),relation,type:IGNORE,:END_ID(Company)

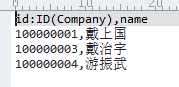
relation.csv
714362,股东,法人股东,100409508
6769709,股东,法人股东,114116132
3560046,股东,法人股东,107407670
20109212,股东,法人股东,134342172
20657888,股东,法人股东,135224137
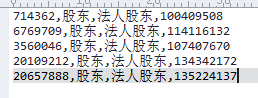
neo4j-import --multiline-fields=true --bad-tolerance=1000000 --into graph.db --id-type string --nodes:person node.csv --relationships:related relation_header.csv,relation.csv

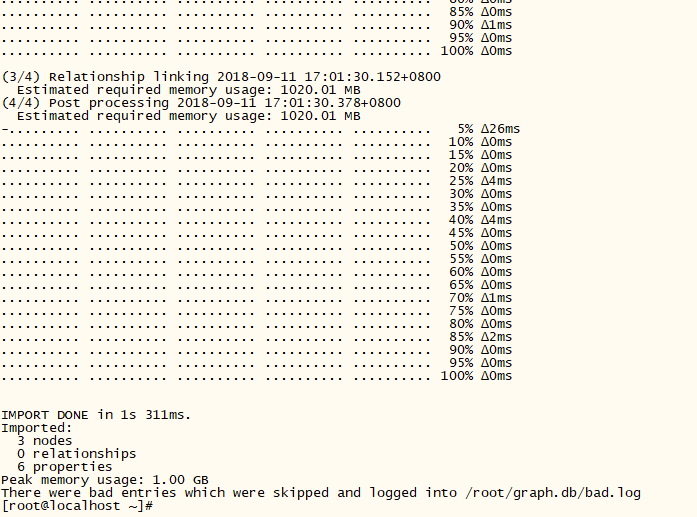
运行完成后可以在看到在当前目录下生成了graph.db,将其放入data/databases,覆盖原有数据库(必须先关闭数据库),启动运行即可

使用neo4j-import工具导入数据的更多相关文章
- 使用neo4j图数据库的import工具导入数据 -方法和注意事项
背景 最近我在尝试存储知识图谱的过程中,接触到了Neo4j图数据库,这里我摘取了一段Neo4j的简介: Neo4j是一个高性能的,NOSQL图形数据库,它将结构化数据存储在网络上而不是表中.它是一个嵌 ...
- importTSV工具导入数据到hbase
1.建立目标表test,确定好列族信息. create'test','info','address' 2.建立文件编写要导入的数据并上传到hdfs上 touch a.csv vi a.csv 数据内容 ...
- SQLSERVER数据库中批量导入数据的几种方法
第一:使用Select Into 语句 如果企业数据库都是采用SQL Server数据库的话,则可以利用select into语句实现数据的导入. select into语句的作用是把数据从另外一个数 ...
- 批量导入数据表(oracle)
批量导入数据表(oracle) 1.登陆plsql 2.找到菜单栏 工具>>导入数据>>新增图标(会提示选择*.csv文件) 选择如上图所示 3.选择数据并导入 4.下图为执行 ...
- Neo4j ETL工具快速上手:简化从关系数据库到图数据库的数据迁移
注:本文系从https://medium.com/neo4j/tap-into-hidden-connections-translating-your-relational-data-to-graph ...
- neo4j批量导入数据的两种解决方案
neo4j批量导入数据有两种方法,第一种是使用cypher语法中的LOAD CSV,第二种是使用neo4j自带的工具neo4j-admin import. LOAD CSV 导入的文件必须是csv文件 ...
- 使用sqoop工具从oracle导入数据
sqoop工具是hadoop下连接关系型数据库和Hadoop的桥梁,支持关系型数据库和hive.hdfs,hbase之间数据的相互导入,可以使用全表导入和增量导入 从RDBMS中抽取出的数据可以被Ma ...
- sqoop工具从oracle导入数据2
sqoop工具从oracle导入数据 sqoop工具是hadoop下连接关系型数据库和Hadoop的桥梁,支持关系型数据库和hive.hdfs,hbase之间数据的相互导入,可以使用全表导入和增量导入 ...
- Nebula Exchange 工具 Hive 数据导入的踩坑之旅
摘要:本文由社区用户 xrfinbj 贡献,主要介绍 Exchange 工具从 Hive 数仓导入数据到 Nebula Graph 的流程及相关的注意事项. 1 背景 公司内部有使用图数据库的场景,内 ...
随机推荐
- 【BZOJ4591】[SHOI2015]超能粒子炮·改 (卢卡斯定理)
[BZOJ4591][SHOI2015]超能粒子炮·改 (卢卡斯定理) 题面 BZOJ 洛谷 题解 感天动地!终于不是拓展卢卡斯了!我看到了一个模数,它是质数!!! 看着这个东西就感觉可以递归处理. ...
- [luogu4568][bzoj2763][JLOI2011]飞行路线
题目描述 Alice和Bob现在要乘飞机旅行,他们选择了一家相对便宜的航空公司.该航空公司一共在n个城市设有业务,设这些城市分别标记为00到n-1,一共有m种航线,每种航线连接两个城市,并且航线有一定 ...
- pyEcharts
例子: from pyecharts import Line line = Line("我的第一个图表", "这里是副标题",width="800px ...
- POJ1088(记忆搜索加dp)
滑雪 Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 106415 Accepted: 40499 Description ...
- SQLite 学习笔记(一)
(1)创建数据库 在命令行中切换到sqlite.exe所在的文件夹 在命令中键入sqlite3 test.db;即可创建了一个名为test.db的数据库 由于此时的数据库中没有任何表及 ...
- configParse模块(二十七)
configparser用于处理特定格式的文件,其本质上是利用open来操作文件. # 注释1 ; 注释2 [section1] # 节点 k1 = v1 # 值 k2:v2 # 值 [section ...
- Java使用SFTP和FTP两种连接方式实现对服务器的上传下载 【我改】
[]如何区分是需要使用SFTP还是FTP? []我觉得: 1.看是否已知私钥. SFTP 和 FTP 最主要的区别就是 SFTP 有私钥,也就是在创建连接对象时,SFTP 除了用户名和密码外还需要知道 ...
- Apache模块 mod_proxy
转: Apache模块 mod_proxy 转自http://www.php100.com/manual/apache2/mod/mod_proxy.html Apache模块 mod_proxy 说 ...
- springboot配置多环境
https://www.cnblogs.com/jason0529/p/6567373.html Spring的profiles机制,是应对多环境下面的一个解决方案,比较常见的是开发和测试环境的配 ...
- 【清北学堂2018-刷题冲刺】Contest 9
前几天本蒟蒻一直在颓废所以这篇题解咕了很久,而且最后一个题目不太会,最终也没完成,非常惭愧. 写这些题目收获相当大.后面的日子呢,我会继续着手刷NOIP题目和Codeforces题目. 到这里就 ...