sqoop工具从oracle导入数据2
sqoop工具从oracle导入数据
sqoop工具是hadoop下连接关系型数据库和Hadoop的桥梁,支持关系型数据库和hive、hdfs,hbase之间数据的相互导入,可以使用全表导入和增量导入
从RDBMS中抽取出的数据可以被MapReduce程序使用,也可以被类似Hive的工具使用;得到分析结果后sqoop可以将结果导回数据库,供其他客户端使用
sqoop安装

解压然后配置环境变量即可
从oracle向HDFS导入数据
原理:
1)在导入之前,sqoop使用jdbc来检查将要导入的表,检索出表中所有的列及数据类型,然后将这些类型映射为java类型,在mapreduce中将使用对应的java类型保存字段的值。sqoop的代码生成器使用这些信息来 创建对应的类,用于保存从表中抽取的记录
2)不需要每次都导入整张表,可以在查询中加入where子句,来限定需要导入的记录
导入:
遍历oracle的表:
sqoop list-tables --connect jdbc:oracle:thin:@192.168.**.**:**:**--username **--password=**
导入oracle中的表:
sqoop import --connect jdbc:oracle:thin:@192.168.**.**:**:**--username **--password **--table ENTERPRISE -m 1 --target-dir /user/root --direct-split-size 67108864
其中split-size指定导入的HDFS路径与导入的文件大小限制
注意:1. 默认情况下会使用4个map任务,每个任务都会将其所导入的数据写到一个单独的文件中,4个文件位于同一目录,本例中 -m1表示只使用一个map任务
2. 文本文件不能保存为二进制字段,并且不能区分null值和字符串值"null"
3. 执行上面的命令后会生成一个ENTERPRISE.java文件,可以通过ls ENTERPRISE.java查看,代码生成是sqoop导入过程的必要部分,sqoop在将源数据库中的数据写到HDFS前,首先会用生成的代码将其进行反序列化
在MapReduce下查看:
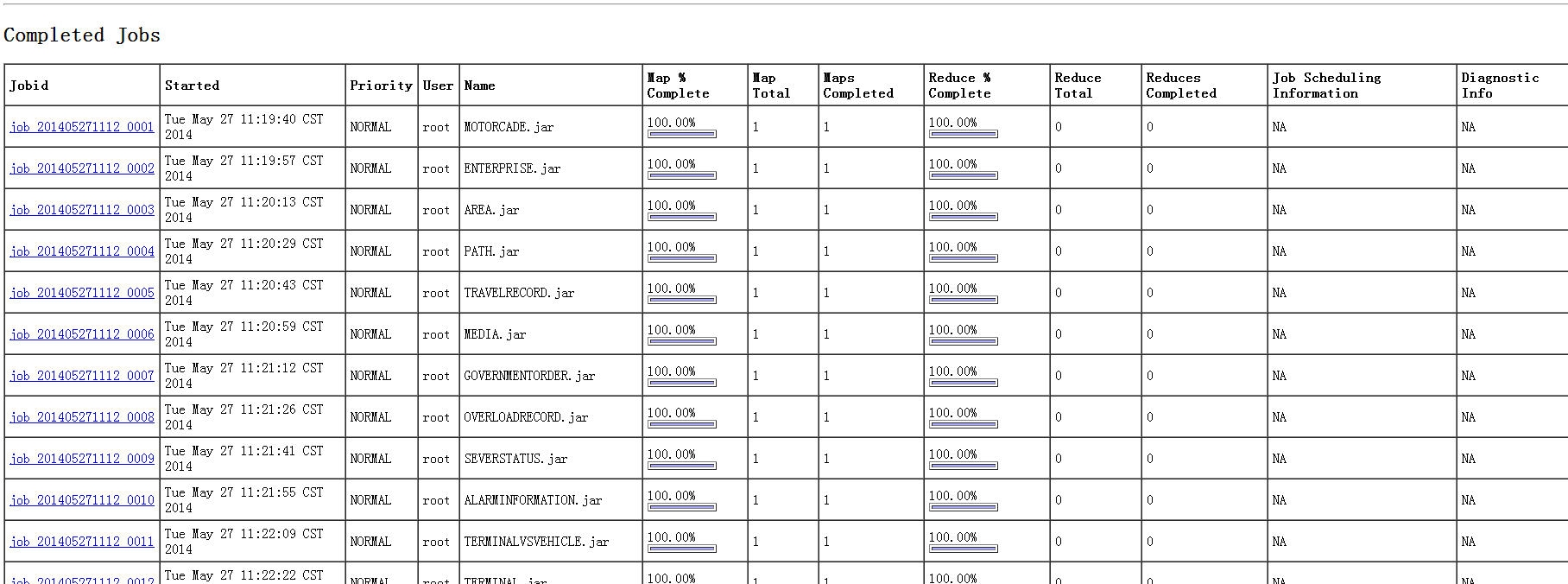
在namenode下查看:
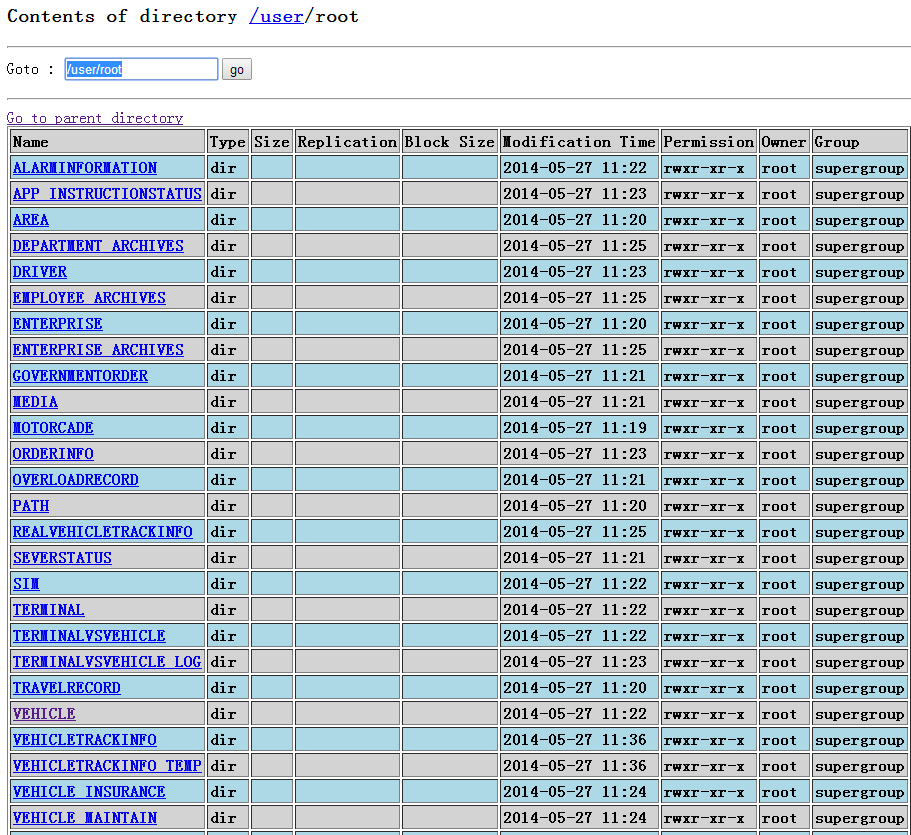
查看VEHICLE表:
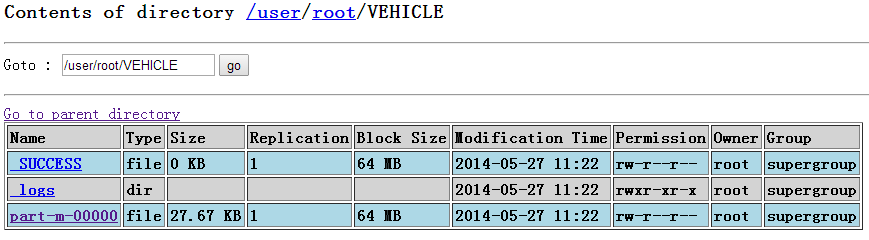
查看part-m-00000中数据

oralce中每条记录对应上面一行数据
数据导出
使用export可将hdfs中数据导入到远程数据库中
eg:
export --connect jdbc:oracle:thin:@192.168.**.**:**:**--username **--password=** -m1 table VEHICLE--export-dir /user/root/VEHICLE
向Hbase导入数据
eg:
sqoop import --connect jdbc:oracle:thin:
@192.168.**.**:**:**--username **--password=**--m 1 --table VEHICLE --hbase-create-table --hbase-table VEHICLE --hbase-row-key ID --column-family VEHICLEINFO --split-by ID
sqoop工具从oracle导入数据2的更多相关文章
- 使用sqoop工具从oracle导入数据
sqoop工具是hadoop下连接关系型数据库和Hadoop的桥梁,支持关系型数据库和hive.hdfs,hbase之间数据的相互导入,可以使用全表导入和增量导入 从RDBMS中抽取出的数据可以被Ma ...
- sqoop操作之ORACLE导入到HIVE
导入表的所有字段 sqoop import --connect jdbc:oracle:thin:@192.168.1.107:1521:ORCL \ --username SCOTT --passw ...
- oracle导入数据
oracle导入数据时候注意点: 1.imp system/admin@oracle9i file=E:\shujukuwenjian\2014-04-01.dmp fromuser=ptb_supe ...
- 使用SLT 工具从SAP导入数据到SAP HANA的监控
使用SLT工具从SAP导入数据到SAP HANA主要有两种方式监控, 一是在SAP SLT服务器上使用以下T-Code: IUUC_SYNC_MON MWBMON 二是在SAP HANA Studio ...
- sqoop操作之Oracle导入到HDFS
导入表的所有字段 sqoop import --connect jdbc:oracle:thin:@192.168.1.100:1521:ORCL \ --username SCOTT --passw ...
- 使用sqoop1.4.4从oracle导入数据到hive中错误记录及解决方案
在使用命令导数据过程中,出现如下错误 sqoop import --hive-import --connect jdbc:oracle:thin:@192.168.29.16:1521/testdb ...
- 通过工具SQLyog进行导入数据
可以通过工具SQLyog进行图形化导入数据. 1.准备好Excel表格 2.将excel表格数据导入到mysql数据库 (1)打开准备好的excel表,选择格式 另存为csv. (2)如果准备的exc ...
- 使用MongoDB命令工具导出、导入数据
Windows 10家庭中文版,MongoDB 3.6.3, 前言 在前面的测试中,已经往MongoDB的数据库中写入了一些数据.现在要重新测试程序,数据库中的旧数据需要被清理掉,可是,又想保存之前写 ...
- 使用sqoop往hdfs中导入数据供hive使用
sqoop import -fs hdfs://x.x.x.x:8020 -jt local --connect "jdbc:oracle:thin:@x.x.x.x:1521:testdb ...
随机推荐
- pt-online-schema-change 脚本化
mysql在线更改表可用工具 pt-online-schema-change 更改,或者用gh-ost更改.pt-online-schema-change 在原表创建索引,跟踪新插入的数据.gh-os ...
- MySQL的Root用户密码
缘由:最近北京市二环内大兴土木,各种挖沟埋线.忽而一纸通令周末断电,故多年不断电的服务器,便令人有了关机后是否还能正常启动的隐忧.其中一台较年迈的服务器中搭载有MySQL数据库.数据库内容本属于外包项 ...
- IDEA中解决Edit Configurations中没有tomcat Server选项的问题(附配置Tomcat)
1.点击File-->settings(Ctrl+Alt+S) 2.在弹出的窗口中的搜索框中输入appliation,然后选择下方的Plugins,再然后勾选左侧Installed中的如图所示的 ...
- u-boot-2016.01移植(一)
1.了解uboot: 阅读uboot源码顶层目录下的README.TXT可以提取如下信息: made to support booting of Linux images. //引导内核程 ...
- semcms 网站漏洞挖掘过程与安全修复防范
emcms是国内第一个开源外贸的网站管理系统,目前大多数的外贸网站都是用的semcms系统,该系统兼容许多浏览器,像IE,google,360极速浏览器都能非常好的兼容,官方semcms有php版本, ...
- GIT LFS 使用笔记
一.背景 由于git上传文件大小受限,所以我们需要使用GIT LFS对大小超过一定上限的大文件进行处理. 二.安装 linux上安装参见 https://askubuntu.com/questions ...
- webpack入门概念
一 概念 1 入口(entry) 入口起点(entry point)提示webpack 应该使用那个模块,来作为构建其内部依赖图得开始.进入入口七点后,webpack 会找出那些模块和库是入口起点(直 ...
- Excel拼接字符串
有时候,需要把一些Excel表格中的内容进行拼接,比如A4行的值是前面三行值的加起来.在Excel中可以使用&来进行这种操作.如果数据非常多,就可以使用这个来进行批量操作.
- Objective-C反射机制
oc反射机制有三个用途: 1.获得Class Class LoginViewController = NSClassFromString(@"LoginViewController" ...
- Android PopupWindow 疑难杂症之宽度WRAP_CONTENT
一直以来都觉得 Android 中的 PopupWindow 不好用.主要有以下两点:1.宽度不好控制2.位置不好控制 今天单说第1点. 由于应用有好几种国家的语言,加上各设备宣染效果不完全一样,对p ...