入门大数据---Spark部署模式与作业提交
一、作业提交
1.1 spark-submit
Spark 所有模式均使用 spark-submit 命令提交作业,其格式如下:
./bin/spark-submit \
--class <main-class> \ # 应用程序主入口类
--master <master-url> \ # 集群的 Master Url
--deploy-mode <deploy-mode> \ # 部署模式
--conf <key>=<value> \ # 可选配置
... # other options
<application-jar> \ # Jar 包路径
[application-arguments] #传递给主入口类的参数
需要注意的是:在集群环境下,application-jar 必须能被集群中所有节点都能访问,可以是 HDFS 上的路径;也可以是本地文件系统路径,如果是本地文件系统路径,则要求集群中每一个机器节点上的相同路径都存在该 Jar 包。
1.2 deploy-mode
deploy-mode 有 cluster 和 client 两个可选参数,默认为 client。这里以 Spark On Yarn 模式对两者进行说明 :
- 在 cluster 模式下,Spark Drvier 在应用程序的 Master 进程内运行,该进程由群集上的 YARN 管理,提交作业的客户端可以在启动应用程序后关闭;
- 在 client 模式下,Spark Drvier 在提交作业的客户端进程中运行,Master 进程仅用于从 YARN 请求资源。
1.3 master-url
master-url 的所有可选参数如下表所示:
| Master URL | Meaning |
|---|---|
local |
使用一个线程本地运行 Spark |
local[K] |
使用 K 个 worker 线程本地运行 Spark |
local[K,F] |
使用 K 个 worker 线程本地运行 , 第二个参数为 Task 的失败重试次数 |
local[*] |
使用与 CPU 核心数一样的线程数在本地运行 Spark |
local[*,F] |
使用与 CPU 核心数一样的线程数在本地运行 Spark 第二个参数为 Task 的失败重试次数 |
spark://HOST:PORT |
连接至指定的 standalone 集群的 master 节点。端口号默认是 7077。 |
spark://HOST1:PORT1,HOST2:PORT2 |
如果 standalone 集群采用 Zookeeper 实现高可用,则必须包含由 zookeeper 设置的所有 master 主机地址。 |
mesos://HOST:PORT |
连接至给定的 Mesos 集群。端口默认是 5050。对于使用了 ZooKeeper 的 Mesos cluster 来说,使用 mesos://zk://... 来指定地址,使用 --deploy-mode cluster 模式来提交。 |
yarn |
连接至一个 YARN 集群,集群由配置的 HADOOP_CONF_DIR 或者 YARN_CONF_DIR 来决定。使用 --deploy-mode 参数来配置 client 或 cluster 模式。 |
下面主要介绍三种常用部署模式及对应的作业提交方式。
二、Local模式
Local 模式下提交作业最为简单,不需要进行任何配置,提交命令如下:
# 本地模式提交应用
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local[2] \
/usr/app/spark-2.4.0-bin-hadoop2.6/examples/jars/spark-examples_2.11-2.4.0.jar \
100 # 传给 SparkPi 的参数
spark-examples_2.11-2.4.0.jar 是 Spark 提供的测试用例包,SparkPi 用于计算 Pi 值,执行结果如下:

三、Standalone模式
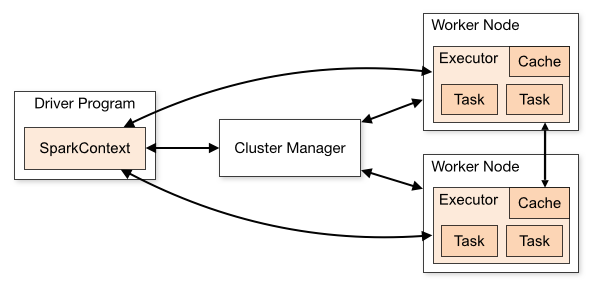
Standalone 是 Spark 提供的一种内置的集群模式,采用内置的资源管理器进行管理。下面按照如图所示演示 1 个 Mater 和 2 个 Worker 节点的集群配置,这里使用两台主机进行演示:
- hadoop001: 由于只有两台主机,所以 hadoop001 既是 Master 节点,也是 Worker 节点;
- hadoop002 : Worker 节点。
3.1 环境配置
首先需要保证 Spark 已经解压在两台主机的相同路径上。然后进入 hadoop001 的 ${SPARK_HOME}/conf/ 目录下,拷贝配置样本并进行相关配置:
# cp spark-env.sh.template spark-env.sh
在 spark-env.sh 中配置 JDK 的目录,完成后将该配置使用 scp 命令分发到 hadoop002 上:
# JDK安装位置
JAVA_HOME=/usr/java/jdk1.8.0_201
3.2 集群配置
在 ${SPARK_HOME}/conf/ 目录下,拷贝集群配置样本并进行相关配置:
# cp slaves.template slaves
指定所有 Worker 节点的主机名:
# A Spark Worker will be started on each of the machines listed below.
hadoop001
hadoop002
这里需要注意以下三点:
- 主机名与 IP 地址的映射必须在
/etc/hosts文件中已经配置,否则就直接使用 IP 地址; - 每个主机名必须独占一行;
- Spark 的 Master 主机是通过 SSH 访问所有的 Worker 节点,所以需要预先配置免密登录。
3.3 启动
使用 start-all.sh 代表启动 Master 和所有 Worker 服务。
./sbin/start-master.sh
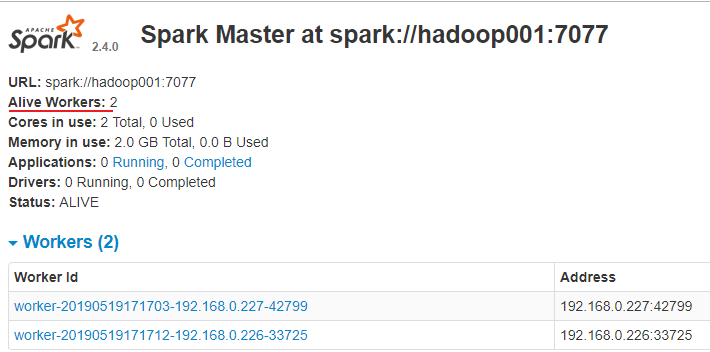
访问 8080 端口,查看 Spark 的 Web-UI 界面,,此时应该显示有两个有效的工作节点:
3.4 提交作业
# 以client模式提交到standalone集群
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop001:7077 \
--executor-memory 2G \
--total-executor-cores 10 \
/usr/app/spark-2.4.0-bin-hadoop2.6/examples/jars/spark-examples_2.11-2.4.0.jar \
100
# 以cluster模式提交到standalone集群
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://207.184.161.138:7077 \
--deploy-mode cluster \
--supervise \ # 配置此参数代表开启监督,如果主应用程序异常退出,则自动重启 Driver
--executor-memory 2G \
--total-executor-cores 10 \
/usr/app/spark-2.4.0-bin-hadoop2.6/examples/jars/spark-examples_2.11-2.4.0.jar \
100
3.5 可选配置
在虚拟机上提交作业时经常出现一个的问题是作业无法申请到足够的资源:
Initial job has not accepted any resources;
check your cluster UI to ensure that workers are registered and have sufficient resources

这时候可以查看 Web UI,我这里是内存空间不足:提交命令中要求作业的 executor-memory 是 2G,但是实际的工作节点的 Memory 只有 1G,这时候你可以修改 --executor-memory,也可以修改 Woker 的 Memory,其默认值为主机所有可用内存值减去 1G。

关于 Master 和 Woker 节点的所有可选配置如下,可以在 spark-env.sh 中进行对应的配置:
| Environment Variable(环境变量) | Meaning(含义) |
|---|---|
SPARK_MASTER_HOST |
master 节点地址 |
SPARK_MASTER_PORT |
master 节点地址端口(默认:7077) |
SPARK_MASTER_WEBUI_PORT |
master 的 web UI 的端口(默认:8080) |
SPARK_MASTER_OPTS |
仅用于 master 的配置属性,格式是 "-Dx=y"(默认:none),所有属性可以参考官方文档:spark-standalone-mode |
SPARK_LOCAL_DIRS |
spark 的临时存储的目录,用于暂存 map 的输出和持久化存储 RDDs。多个目录用逗号分隔 |
SPARK_WORKER_CORES |
spark worker 节点可以使用 CPU Cores 的数量。(默认:全部可用) |
SPARK_WORKER_MEMORY |
spark worker 节点可以使用的内存数量(默认:全部的内存减去 1GB); |
SPARK_WORKER_PORT |
spark worker 节点的端口(默认: random(随机)) |
SPARK_WORKER_WEBUI_PORT |
worker 的 web UI 的 Port(端口)(默认:8081) |
SPARK_WORKER_DIR |
worker 运行应用程序的目录,这个目录中包含日志和暂存空间(default:SPARK_HOME/work) |
SPARK_WORKER_OPTS |
仅用于 worker 的配置属性,格式是 "-Dx=y"(默认:none)。所有属性可以参考官方文档:spark-standalone-mode |
SPARK_DAEMON_MEMORY |
分配给 spark master 和 worker 守护进程的内存。(默认: 1G) |
SPARK_DAEMON_JAVA_OPTS |
spark master 和 worker 守护进程的 JVM 选项,格式是 "-Dx=y"(默认:none) |
SPARK_PUBLIC_DNS |
spark master 和 worker 的公开 DNS 名称。(默认:none) |
三、Spark on Yarn模式
Spark 支持将作业提交到 Yarn 上运行,此时不需要启动 Master 节点,也不需要启动 Worker 节点。
3.1 配置
在 spark-env.sh 中配置 hadoop 的配置目录的位置,可以使用 YARN_CONF_DIR 或 HADOOP_CONF_DIR 进行指定:
YARN_CONF_DIR=/usr/app/hadoop-2.6.0-cdh5.15.2/etc/hadoop
# JDK安装位置
JAVA_HOME=/usr/java/jdk1.8.0_201
3.2 启动
必须要保证 Hadoop 已经启动,这里包括 YARN 和 HDFS 都需要启动,因为在计算过程中 Spark 会使用 HDFS 存储临时文件,如果 HDFS 没有启动,则会抛出异常。
# start-yarn.sh
# start-dfs.sh
3.3 提交应用
# 以client模式提交到yarn集群
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
--executor-memory 2G \
--num-executors 10 \
/usr/app/spark-2.4.0-bin-hadoop2.6/examples/jars/spark-examples_2.11-2.4.0.jar \
100
# 以cluster模式提交到yarn集群
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
--executor-memory 2G \
--num-executors 10 \
/usr/app/spark-2.4.0-bin-hadoop2.6/examples/jars/spark-examples_2.11-2.4.0.jar \
100
入门大数据---Spark部署模式与作业提交的更多相关文章
- 入门大数据---Spark整体复习
一. Spark简介 1.1 前言 Apache Spark是一个基于内存的计算框架,它是Scala语言开发的,而且提供了一站式解决方案,提供了包括内存计算(Spark Core),流式计算(Spar ...
- 入门大数据---Spark简介
一.简介 Spark 于 2009 年诞生于加州大学伯克利分校 AMPLab,2013 年被捐赠给 Apache 软件基金会,2014 年 2 月成为 Apache 的顶级项目.相对于 MapRedu ...
- Spark学习之路(五)—— Spark运行模式与作业提交
一.作业提交 1.1 spark-submit Spark所有模式均使用spark-submit命令提交作业,其格式如下: ./bin/spark-submit \ --class <main- ...
- Spark 系列(五)—— Spark 运行模式与作业提交
一.作业提交 1.1 spark-submit Spark 所有模式均使用 spark-submit 命令提交作业,其格式如下: ./bin/spark-submit \ --class <ma ...
- 入门大数据---Spark开发环境搭建
一.安装Spark 1.1 下载并解压 官方下载地址:http://spark.apache.org/downloads.html ,选择 Spark 版本和对应的 Hadoop 版本后再下载: 解压 ...
- 入门大数据---Spark累加器与广播变量
一.简介 在 Spark 中,提供了两种类型的共享变量:累加器 (accumulator) 与广播变量 (broadcast variable): 累加器:用来对信息进行聚合,主要用于累计计数等场景: ...
- 入门大数据---Spark车辆监控项目
一.项目简介 这是一个车辆监控项目.主要实现了三个功能: 1.计算每一个区域车流量最多的前3条道路. 2.计算道路转换率 3.实时统计道路拥堵情况(当前时间,卡口编号,车辆总数,速度总数,平均速度) ...
- 《大数据Spark企业级实战 》
基本信息 作者: Spark亚太研究院 王家林 丛书名:决胜大数据时代Spark全系列书籍 出版社:电子工业出版社 ISBN:9787121247446 上架时间:2015-1-6 出版日期:20 ...
- 王家林 大数据Spark超经典视频链接全集[转]
压缩过的大数据Spark蘑菇云行动前置课程视频百度云分享链接 链接:http://pan.baidu.com/s/1cFqjQu SCALA专辑 Scala深入浅出经典视频 链接:http://pan ...
随机推荐
- Dubbo源码笔记-服务注册
今天来简单做一下Dubbo服务注册部分源码学习手记. 一.Dubbo配置解析 目前Dubbo最多的用法就是跟Spring集成,既然跟Spring集成,那么,Dubbo对象的实例化都将交由Spring统 ...
- Java实现 LeetCode 641 设计循环双端队列(暴力)
641. 设计循环双端队列 设计实现双端队列. 你的实现需要支持以下操作: MyCircularDeque(k):构造函数,双端队列的大小为k. insertFront():将一个元素添加到双端队列头 ...
- Java蓝桥杯 算法提高 九宫格
算法提高 9-1九宫格 时间限制:1.0s 内存限制:256.0MB 提交此题 问题描述 九宫格.输入1-9这9个数字的一种任意排序,构成3*3二维数组.如果每行.每列以及对角线之和都相等,打印1.否 ...
- Java实现完美洗牌算法
1 问题描述 有一个长度为2n的数组{a1,a2,a3,-,an,b1,b2,b3,-,bn},希望排序后变成{a1,b1,a2,b2,a3,b3,-,an,bn},请考虑有没有时间复杂度为O(n)而 ...
- Java实现 蓝桥杯 算法提高金属采集
问题描述 人类在火星上发现了一种新的金属!这些金属分布在一些奇怪的地方,不妨叫它节点好了.一些节点之间有道路相连,所有的节点和道路形成了一棵树.一共有 n 个节点,这些节点被编号为 1~n .人类将 ...
- java实现第六届蓝桥杯密文搜索
密文搜索 福尔摩斯从X星收到一份资料,全部是小写字母组成. 他的助手提供了另一份资料:许多长度为8的密码列表. 福尔摩斯发现,这些密码是被打乱后隐藏在先前那份资料中的. 请你编写一个程序,从第一份资料 ...
- 用js实现简单的抛物线运动
前言 老早就看过一些购物车的抛物线效果,也想自己凑热闹动手来实现一遍. 然后(lll¬ω¬) 书到用时方恨少,发现高中学到物理啊.数学啊,都忘光了,抛物线公式都忘了0 0. 顺手百度一波,从百度可知: ...
- linux下的mysql目录
/usr/bin 客户端程序和脚本[root@~ bin]# ls mysql*mysql mysqldump mysql_secure_installationmysqladmin mysqldum ...
- Python:三元表达式、列表推导式和生成器表达式
三元表达式 语法格式 如下: 为真时的结果 if 判断条件 else 为假时的结果 例子 name = input('姓名>>: ') res = '请进' if name == '张三' ...
- 素数筛 : Eratosthenes 筛法, 线性筛法
这是两种简单的素数筛法, 好不容易理解了以后写篇博客加深下记忆 首先, 这两种算法用于解决的问题是 : 求小于n的所有素数 ( 个数 ) 比如 这道题 在不了解这两个素数筛算法的同学, 可能会这么写一 ...