java中JVM虚拟机内存模型详细说明
JVM的内部结构如下图:
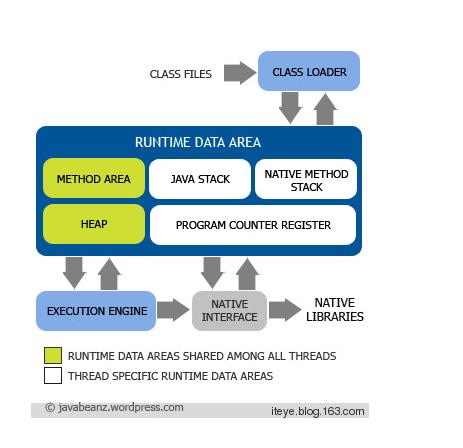
一个优秀Java程序员,必须了解Java内存模型、GC工作原理,以及如何优化GC的性能、与GC进行有限的交互,有一些应用程序对性能要求较高,例如嵌入式系统、实时系统等,只有全面提升内存的管理效率,才能提高整个应用程序的性能。
本文将从JVM内存模型、GC工作原理,以及GC的几个关键问题进行探讨,从GC角度提高Java程序的性能。
1 java内存分为:
程序计数器(当前线程所执行字节码的行号指示器,字节码解释器要通过改变这个计数器的值来选择下一条字节码指令,分支、循环、异常处理等。每条线程都有一条独立的程序计数器,属于线程私有的内存区)、
java虚拟机栈(也是线私有的,存储局部变量、操作栈,每个方法执行时创建一个栈帧,执行过程就是栈的出栈入栈操作)、
本地方法栈(执行native方法)、
年轻代堆(eden、from survivor、to survivor)、年老代堆(经过几次垃圾回收,保存下来的)、
持久代堆(也叫方法区,保存常量池和类型数据信息,不会被回收)、
直接内存(使用native方法直接分配堆外内存,再通过堆内的DirectByteBuffer作为这块内存的引用进行操作)
2 对象访问有两种:通过句柄池和直接通过指针,句柄池的好处是垃圾回收后,不需要改变对象引用,只要改变句柄引用;直接指针的好处是效率较高。
引用《深入java虚拟机第二章》
解释了minor gc和major gc,和两个survivor区之于复制收集算法的意义
3 jvm内存机制
java内存中的四种引用解析,强引用、弱引用、软引用、虚引用
4 垃圾回收算法
4.1 引用计数,效率高,但是无法解决无用对象循环引用的问题。及时引用计数大于0,但却不可用。
4.2 根对象可达,java虚拟机使用的方式。可以作为根对象的有:虚拟机栈帧中引用的对象,方法区中(持久区)类静态属性引用的对象(类静态属性在创建实例之前就已经为这个属性分配好空间,创建好实例,在所有的类实例中共享),方法区中常量引用的对象(比如常量字符串),本地方法栈中引用的对象(native方法)。
4.3 引用强度,强(即传统理解的引用,obj=new obj()),软(softReference,在内存溢出之前,GC会将这部分纳入回收范围,进行二次回收,如果还是没有足够内存,那么OOM),弱(weakReference,一旦GC进行回收,无论内存是否充足都会被回收),虚(有虚引用不会影响生命周期,无法通过虚引用来获得一个对象,唯一作用是对象被回收时能得到一个系统通知,PhantomReference)
4.4 对象在回收之前会调用仅有一次finalize(),可以在finalize中自救,把自己被引用。只有当对象覆盖finalize()方法才会被放入执行finalize()的队列。不建议使用这个,可以用try{} finally代替。
4.5 java回收算法
标记清除法,效率低下,会产生内存碎片。
复制收集算法,较为主流的算法,分区,eden,survivor,将未被回收的对象移动到survivor区,然后一次性清理eden区。这种算法适用于对象存活率不高的情况,要牺牲一部分分配空间,一般来说eden:survivor=8:1。
当对象存活率很高的时候,复制收集算法的效率会出现问题,所以有了标记-整理算法。把所有存活对象整理到一端,再把另一端直接清理掉。
分代算法,java内存一般都分为新生代和年老代,根据两个区域对象存活率的特点,分别采用了复制-收集算法和标记-清理(标记-整理)算法。
4.6 垃圾收集器
serial收集器,单线程收集。很可恶,会停掉其他用户线程。糟糕的用户体验。但是适用于client端,因为产生的垃圾量少,回收快,几十毫秒解决。
parNew收集器,和serial一样。区别是收集时采用多线程机制。
CMS收集器,可以让收集线程和用户线程并发执行,可惜的是作为年老代的收集器,只能和上面两个不靠谱的收集器一起配合使用。它是以最短停顿时间为目标的年老代收集器,使用mark-sweep算法(标记-清除)。回收步骤是初始标记(stop world),并发标记,重新标记(stop world),并发清除。stop world的时间很短,所以可以认为是用户线程并发的收集器。
parallel scavenge收集器,是并发收集器,可以和用户线程并存。可以通过参数控制吞吐量=用户线程时间/(用户时间+垃圾收集时间),前台程序适用低吞吐量,减少用户操作每次停顿的时间;而后台程序适用于高吞吐量,尽快完成后台的计算。也称作吞吐量优先收集器。该收集器还能设置自适应模式,会根据实际情况动态调整吞吐量。
serial old收集器和serial一样,用于年老代收集。使用标记整理算法。
parallel old收集器,用于和parallel scavenge配合使用的年老代收集器,是parallel scavenge的最佳搭档。
G1(garbage first)收集器,最前沿的,jdk1.6进入试用期。采用标记-整理算法,并且对新生区分区,分区有不同的优先级,优先收集内存较满的区域。有着很高的并发和较低的停顿,也算是敏捷的一种收集器。
5 基本经验
minor gc是运行在新生代的gc,major GC是运行在年老代的GC,比minor慢十倍。
大对象很有可能直接进入年老代,程序中尽量避免短命大对象(数组、列表)。
一次minor没被收集,从eden进入survivor,每过一次GC,survivor加一岁,直到N岁进入年老区。
根据GC的工作原理,我们可以通过一些技巧和方式,让GC运行更加有效率,更加符合应用程序的要求。一些关于程序设计的几点建议:
1)最基本的建议就是尽早释放无用对象的引用。大多数程序员在使用临时变量的时候,都是让引用变量在退出活动域(scope)后,自动设置为 null.我们在使用这种方式时候,必须特别注意一些复杂的对象图,例如数组,队列,树,图等,这些对象之间有相互引用关系较为复杂。对于这类对象,GC 回收它们一般效率较低。如果程序允许,尽早将不用的引用对象赋为null,这样可以加速GC的工作。
2)尽量少用finalize函数。finalize函数是Java提供给程序员一个释放对象或资源的机会。但是,它会加大GC的工作量,因此尽量少采用finalize方式回收资源。
3)如果需要使用经常使用的图片,可以使用soft应用类型。它可以尽可能将图片保存在内存中,供程序调用,而不引起OutOfMemory.
4)注意集合数据类型,包括数组,树,图,链表等数据结构,这些数据结构对GC来说,回收更为复杂。另外,注意一些全局的变量,以及一些静态变量。这些变量往往容易引起悬挂对象(dangling reference),造成内存浪费。
5)当程序有一定的等待时间,程序员可以手动执行System.gc(),通知GC运行,但是Java语言规范并不保证GC一定会执行。使用增量式GC可以缩短Java程序的暂停时间。
java中JVM虚拟机内存模型详细说明的更多相关文章
- 面试官:别的我不管,这个JVM虚拟机内存模型你必须知道
前言 说jvm的内存模型前先了解一下物理计算机的内存处理. 物理计算器上用户磁盘和cpu的交互,由于cpu读写速度速度远远大于磁盘的读写速度速度,所以有了内存(高速缓存区).但是随着cpu的发展,内存 ...
- jvm 虚拟机内存模型
来源:https://blog.csdn.net/A_zhenzhen/article/details/77917991?locationNum=8&fps=1 https://blog ...
- Java:JVM的内存模型
JVM内存模型 JVM内存模型可以分为两个部分,如下图所示,堆和方法区是所有线程共有的,而虚拟机栈,本地方法栈和程序计数器则是线程私有的. 1. 堆(Heap) 堆内存是所有线程共有的,可以分为两 ...
- JVM虚拟机内存模型以及GC机制
JAVA堆的描述如下: 内存由 Perm 和 Heap 组成. 其中 Heap = {Old + NEW = { Eden , from, to } } JVM内存模型中分两大块,一块是 NEW Ge ...
- Java中JVM虚拟机详解
1. 什么是JVM? JVM是Java Virtual Machine(Java虚拟机)的缩写,JVM是一种用于计算设备的规范,它是一个虚构出来的计算机,是通过在实际的计算机上仿真模拟各种计算机功能来 ...
- Java虚拟机内存模型及垃圾回收监控调优
Java虚拟机内存模型及垃圾回收监控调优 如果你想理解Java垃圾回收如果工作,那么理解JVM的内存模型就显的非常重要.今天我们就来看看JVM内存的各不同部分及如果监控和实现垃圾回收调优. JVM内存 ...
- Java中JVM内存结构
Java中JVM内存结构 线程共享区 方法区: 又名静态成员区域,包含整个程序的 class.static 成员等,类本身的字节码是静态的:它会被所有的线程共享和是全区级别的: 属于共享内存区域,存储 ...
- Java虚拟机 - 内存模型
本文主要介绍Java虚拟机的内存分布以及对象的创建过程. 一.Java虚拟机的内存分布 文章开始前读者需要了解Java虚拟机的运行时数据区是怎样划分的.如下图所示: 1.程序计数器(Program C ...
- Java虚拟机--内存模型与线程
Java虚拟机--内存模型与线程 高速缓存:处理器要与内存交互,如读取.存储运算结果,而计算机的存储设备和处理器的运算速度差异巨大,所以加入一层读写速度和处理器接近的高速缓存来作为内存和处理器之间的缓 ...
随机推荐
- Javascript十六种常用设计模式
单例模式 何为单例模式,就是无论执行多少次函数,都只会生成一个对象哈哈,看一个简单的demo function Instance(name) { this.name = name; } Instanc ...
- jenkins-gitlab-harbor-ceph基于Kubernetes的CI/CD运用(三)
从最基础镜像到业务容器 构建 [为gitlab项目部署做铺垫] 业务镜像设计规划 目录结构 # pwd /data/k8s/app/myapp # tree . . ├── dockerfile │ ...
- Servlet(一)----快速入门
## Servlet:server applet * 概念:运行在服务端的小程序 * servlet就是一个接口,定义了Java类被浏览器访问到(tomcat识别)的规则. * 将来我们自定义一 ...
- Mysql常用sql语句(二)- 操作数据表
21篇测试必备的Mysql常用sql语句,每天敲一篇,每次敲三遍,每月一循环,全都可记住!! https://www.cnblogs.com/poloyy/category/1683347.html ...
- Spark在Windows环境下的配置
1.下载 下载地址:http://spark.apache.org/downloads.html. 选择下面版本下载. 2.操作流程:https://blog.csdn.net/nxw_tsp/art ...
- 推荐 | 7个你最应该知道的机器学习相关github项目
欢迎大家关注我们的网站和系列教程:http://www.tensorflownews.com/,学习更多的机器学习.深度学习的知识! 磐石 目录: 介绍 Person Blocker(人体自动遮挡) ...
- 2020 | 可替代Selenium的测试框架Top15
本文首发于 微信公众号: 软测小生 Selenium是一种开源自动测试工具.它可以跨不同的浏览器和平台在Web应用程序上执行功能,回归,负载测试.Slenium是最好的工具之一,但确实有一些缺点. 业 ...
- Vue2.0 -- 钩子函数/ 过度属性/常用指令/以及Vue-resoure发送请求
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- java——构造器理解
构造器理解 什么是构造器 构造器也叫构造方法:用于对象的初始化: 写构造器注意事项 构造器名与类名一致:有返回值但是不能定义返回类型(返回值类型是本类,可以加一个空的return): 构造器的调用 通 ...
- C 最大公约数&最小公倍数
1.最大公约数 链接 如果有一个自然数a能被自然数b整除,则称a为b的倍数,b为a的约数.几个自然数公有的约数,叫做这几个自然数的公约数.公约数中最大的一个公约数,称为这几个自然数的最大公约数. 1 ...