Redis缓存设计与性能优化
Redis我们一般是用作缓存,扛并发;或者用于某些特定的业务场景,比如前面说到redis各种数据类型的使用场景以及redis的哨兵和集群模式。
这里主要整理了下redis用作缓存,存在的一些问题,以及改善方案。
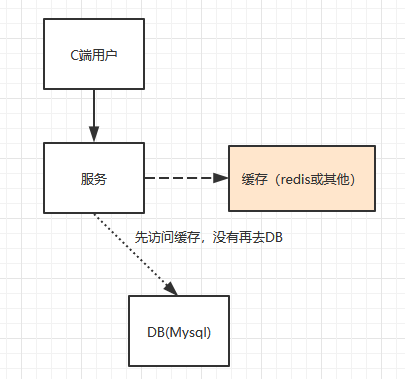
简单的流程就像这个样子,一般请先到缓存区获取,如果缓存没有再到后端的数据库去查询。
1.缓存穿透
缓存穿透是指,是指查询一个根本不存在数据,这样缓存层里面没有,就会去访问后面的存储层了。如果有大量的这种恶意请求过来,都打向后面的存储层。显然我们的存储层是扛不住这样的压力。这样缓存就失去了保护后面存储的意义了。
解决方案:
1.缓存空对象
对于缓存穿透,可以采用缓存空对象,第一次进来缓存和DB都没有,就存个空对象到缓存里面。但是如果大批量的恶意请求过来,这样做就会导致缓存的key暴增,显然不是一个很好的方案。
2.布隆过滤器
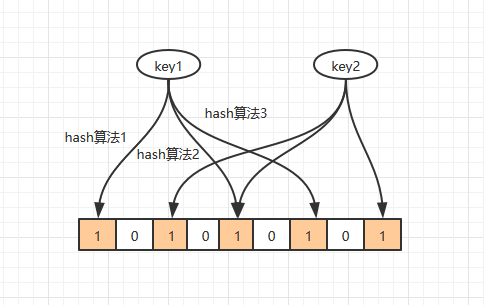
对于不存在的数据布隆过滤器一般都能够过滤掉,不让请求再往后端发送。当布隆过滤器说某个值存在时,这个值可能不存在;但是它说不存在时,那就肯定不存在。布隆过滤器是一个大型的位数组和几个不一样的无偏 hash 函数。所谓无偏就是能够把元素的hash值算得比较均匀。向布隆过滤器中添加 key 时,会使用多个hash 函数对key进行hash分别算得一个整数索引值然后对位数组长度进行取模运算得到一个位置,每个hash函数都会算得一个不同的位置。再把位数组的这几个位置都置为 1 就 完成了 add 操作。
向布隆过滤器询问 key 是否存在时,跟 add 一样,也会把 hash 的几个位置都算出来,看看位数组中这几个位置是否都为1,只要有一个位为0,那么说明布隆过滤器中这个key肯定不存在。但是都是 1,这并不能说明这个key就一定存在,只是极有可能存在,因为这些位被置为1可能是因为其它的key存在所致。
guvua包布隆过滤器的使用,导包
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
</dependency>
伪代码:
public void bloomFilterTest() {
BloomFilter<CharSequence> bloomFilter = BloomFilter.create(
Funnels.stringFunnel(Charset.forName("UTF-8")),
1000, //期望存入的数据个数
0.001);//误差率
//添加到布隆过滤器
String[] keys = new String[1000];
for (String key: keys) {
bloomFilter.put(key);
}
String key = "key";
boolean exist = bloomFilter.mightContain(key);
if (!exist) {
return;
}
//todo 存在才去缓存获取
}
可以看到这个类里面有很多的hash算法:com.google.common.hash.Hashing
redisson也有布隆过滤器的实现。
2.缓存失效
由于大批量的key同时失效,导致,大量的请求同时打向数据库,造成数据库压力过大,甚至直接挂掉。我们在批量写入缓存的时候,设置超时时间,可以是一个固定时间+随机时间方式来生成,这样就可以错开失效时间。更加保险的方案可以加分布式锁,拿到锁的才去访问数据库。
3.缓存雪崩
缓存雪崩是指缓存层挂掉之后,所有请求都打向数据库,数据库扛不住,也可能挂掉,就导致对应的服务也挂掉,也会影响上游的调用服务。这样的级联问题。就像雪崩最开始一小片,然后越来越大,导致整个服务崩溃。
解决方案:
1.保证缓存层的高可用性,比如redis哨兵或者redis集群。
2.各依赖服务之间做限流,熔断,降级等,比如Hystri,阿里的sentinel
4.缓存一致性
引入缓存之后,随之而来的问题就是当DB数据更新时,缓存中的数据就会与db数据不一致。所以数据修改时是先更新缓存还是先更新DB?
如果先更新缓存,然后更新DB失败,那么下一个请求过来读取的缓存数据不是最新的。而我们实际上最终数据肯定都是以DB为准的。
先更新db 在更新缓存,这是在更新DB的时候来的请求读取的数据也是不是最新的
淘汰缓存——更新DB——重新刷进缓存,在更新db是来的请求在缓存没有数据,就会去请求DB,如果并发 可能操作多各请求去写DB,那么就需要加锁了
加锁——淘汰缓存——更新DB——重新刷进缓存,这样相对而言就比较保险了
5.bigkey问题
Bigkey是什么?在redis中,一个字符串最大512MB;hash,list,set,zset可以存储2^31 - 1 个元素。
一般来说字符串超过10kb,其他的几种元素个数不要超过5000个。
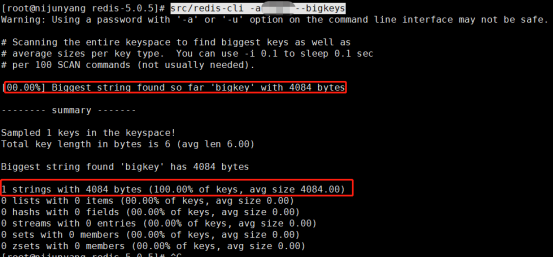
可以使用src/redis-cli --bigkeys 来查看bigkey,我这里设置了一个30多K的字符串,看下扫描结果,扫除了一个字符串类型的bigkey,4084字节。
Bigkey有哪些危害。一是删除时阻塞其他请求,比如一个bigkey,平时都没什么,但是设置了过期时间,到期了删除时,可能就会阻塞其他请求,4.0之后可以开启lazyfree-lazy- expire yes来异步删除;二是造成网络拥堵,比如一个key数据量达到1MB,假设并发量1000,这个时候获取它就会产生1000MB的流量,千兆网卡,峰值的速率也才128MB/S,并不是扛不住并发,而是会占用大量网络带宽。
对于很大list,set这些,我们可以将数据拆分,生成一个系列的的key去存放数据。如果是redis集群这些key自然就可以分到不同的小主从上面去,如果是单机,那么可以自己实现一个路由算法,来如何获取这一系列key中的某一个。
6. 客户端使用
1.避免多个服务使用一个redis实例,如果实在有,可以看下将业务拆分,把这些公共数据服务化。
2.使用连接池,控制有效连接,同时也提高效率。连接池重要参数设置:
1 maxActive 资源池中最大连接数 默认值8
2 maxIdle 资源池允许最大空闲 的连接数 默认值8
3 minIdle 资源池确保最少空闲 的连接数 默认值0
4 blockWhenExhausted 当资源池用尽后,调用者是否要等待。只有当为true时,下面的maxWaitMillis才会生效,默认值true 建议使用默认值
5 maxWaitMillis 当资源池连接用尽后,调用者的最大等待时间(单位为毫秒) -1:表示永不超时 不建议使用默认值
6 testOnBorrow 向资源池借用连接时是否做连接有效性检测(ping),无效连接会被移除 默认值false 业务量很大时候建议 设置为false(多一次 ping的开销)。
7 testOnReturn 向资源池归还连接时是否做连接有效性检测(ping),无效连接会被移除 默认值false 业务量很大时候建议 设置为false(多一次 ping的开销)。
8 jmxEnabled 是否开启jmx监控,可用于监控 默认值true 建议开启,但应用本身也要开启
前面三个参数相对而言更重要,单独拎出来再说下:
最大连接数maxActive:
可以从业务希望的并发量,客户端执行时间,redis资源设置(应用个数(集群部署多少个实例) * maxActive <= maxclients(redis最大连接数,redis配置中设置的)),等因素考虑。
比如一次客户端执行时间2ms,那么一个连接的QPS就是500,业务期望的QPS是3000,那么理论上连接池大小3000/500=60个,实际上考虑其他影响,一般设置比理论值稍微大点。但这个值不是越大越好,一方面连接太多占用客户端和服务端资源,另一方面对 于Redis这种高 QPS的服务器,一个大命令的阻塞即使设置再大资源池仍然会无济于事。
最大空闲连接数maxIdle:
maxIdle实际上才是业务需要的最大连接数,空闲的连接造好放在那儿,进来一个请求就可以直接拿来用了。maxActive是为了给出总量,所以maxIdle不要设置过小,否则会有当空闲连接不够,就会创建新的连接,又会有新的开销,最佳就是maxActive = maxIdle。这样就避免连接池伸缩带来的性能干扰。但是如果并发量不大或者maxActive设置过高,会导致不必要的连接资源浪费。一般推荐maxIdle可以设置为按上面的业务期望QPS计算出来的理论连接数,maxActive可以再放大一些。
最小空闲连接数minIdle:
至少保持多少空闲连接,在使用连接的过程中,如果连接数超过了minIdle,那么继续建立连接,如果超过了 maxIdle,当超过的连接执行完业务后会慢慢被移出连接池释放掉。
3.缓存预热
比如说上线一个抢购活动,肯定到点开始就会有很多人来请求了,这个时候就可以提前做数据的预热,既可以把连接池初始化好,也可以把数据放好。
Redis缓存设计与性能优化的更多相关文章
- Redis缓存设计及常见问题
Redis缓存设计及常见问题 缓存能够有效地加速应用的读写速度,同时也可以降低后端负载,对日常应用的开发至关重要.下面会介绍缓存使 用技巧和设计方案,包含如下内容:缓存的收益和成本分析.缓存更新策略的 ...
- 11.Redis缓存设计
11.Redis缓存设计11.1 缓存的收益和成本11.2 缓存更新策略11.3 缓存粒度控制11.4 穿透优化11.5 无底洞优化11.6 雪崩优化11.7 热点key重建优化11.8 本章重点回顾
- Python 基于python+mysql浅谈redis缓存设计与数据库关联数据处理
基于python+mysql浅谈redis缓存设计与数据库关联数据处理 by:授客 QQ:1033553122 测试环境 redis-3.0.7 CentOS 6.5-x86_64 python 3 ...
- MySQL性能调优与架构设计——第9章 MySQL数据库Schema设计的性能优化
第9章 MySQL数据库Schema设计的性能优化 前言: 很多人都认为性能是在通过编写代码(程序代码或者是数据库代码)的过程中优化出来的,其实这是一个非常大的误区.真正影响性能最大的部分是在设计中就 ...
- redis缓存设计
1:缓存技术和框架的重要性 互联网的一些高并发,高性能的项目和系统中,缓存技术是起着功不可没的作用.缓存不仅仅是key-value的简单存取,它在具体的业务场景中,还是很复杂的,需要很强的架构设计能力 ...
- MySQL性能调优与架构设计——第10章 MySQL数据库Schema设计的性能优化
第10章 MySQL Server性能优化 前言: 本章主要通过针对MySQL Server(mysqld)相关实现机制的分析,得到一些相应的优化建议.主要涉及MySQL的安装以及相关参数设置的优化, ...
- 第 9 章 MySQL数据库Schema设计的性能优化
前言: 很多人都认为性能是在通过编写代码(程序代码或者是数据库代码)的过程中优化出来的,其实这是一个非常大的误区.真正影响性能最大的部分是在设计中就已经产生了的,后期的优化很多时候所能够带来的改善都只 ...
- MySql(九):MySQL性能调优——Schema设计的性能优化
一.高效的模型设计 先了解下数据库设计的三大范式 第一范式:要求有主键,并且要求每一个字段原子性不可再分 第二范式:要求所有非主键字段完全依赖主键,不能产生部分依赖 第三范式:所有非主键字段和主键字段 ...
- 对WEB前端的几段思考(一)——界面设计和性能优化(整理中)
尽管我并非艺术出生,既没有任何设计基础,又没有较高艺术涵养,也深谙在短时间内创造一定艺术造诣并非易事,但是既然当初选择从事网站前端开发,我的目光不能仅停留在前端代码上.作为一名志向在前端领域发展的人员 ...
随机推荐
- 产品需求说明书 PRD模版
XXX产品需求说明书 [版本号:V+数字] 编 制: 日 期: 评 审: 日 期: 批 准: 日 期: 修订记录 版本 修订章节 修订内容 ...
- Introduction Of Gradient Descent
不是一个机器学习算法 是一种基于搜索的优化方法 作用:最小化一个损失函数 梯度上升法:最大化一个效用函数 import matplotlib.pyplot as plt import numpy as ...
- yii框架通过控制台命令创建定时任务
假设Yii项目路径为 /home/apps 1. 创建文件 /home/apps/web/protected/commands/console.php $yii = '/home/apps/frame ...
- swap和shm的区别
在使用docker的过程中,发现其有很多内存相关的命令,对其中的swap(交换内存)和shm(共享内存)尤其费解.于是查阅了一些资料,弄明白了二者的基本区别. swap 是一个文件,是使用硬盘空间的一 ...
- LeetCode~941.有效的山脉数组
941.有效的山脉数组 给定一个整数数组 A,如果它是有效的山脉数组就返回 true,否则返回 false. 让我们回顾一下,如果 A 满足下述条件,那么它是一个山脉数组: A.length > ...
- Kubernetes搭建过程中使用k8s.gcr.io、quay.io、docker.io的镜像加速
前言 因为众所周知的原因,在使用Kubernetes和docker的时候会出现一些镜像无法拉取或者速度较慢的情况,错误信息类似以下: [ERROR ImagePull]: failed to pull ...
- C++走向远洋——63(项目二2、两个成员的类模板)
*/ * Copyright (c) 2016,烟台大学计算机与控制工程学院 * All rights reserved. * 文件名:text.cpp * 作者:常轩 * 微信公众号:Worldhe ...
- 使用Taiko + Gauge进行自动化测试(一)
目录 初识Taiko 环境安装 尝试Taiko taiko 执行过程 结合Gauge编写用例 使用Gauge 总结 初识Taiko 先来了解一下什么是Taiko:"Taiko是一个免费的开源 ...
- idea导入 spring framework项目
准备的环境:gradle,idea 注意:gradle版本不一致会报各种错误,那么怎么查找依赖的版本呢? 首先在git上把spring framework项目拉取下来, 步骤一:复制URL路径 步骤二 ...
- 绕过Referer和Host检查
1.我们在尝试抓取其他网站的数据接口时,某些接口需要经过请求头中的Host和Referer的检查,不是指定的host或referer将不予返回数据,且前端无法绕过这种检查 此时通过后端代理解决 在vu ...