FITTING A MODEL VIA CLOSED-FORM EQUATIONS VS. GRADIENT DESCENT VS STOCHASTIC GRADIENT DESCENT VS MINI-BATCH LEARNING. WHAT IS THE DIFFERENCE?
FITTING A MODEL VIA CLOSED-FORM EQUATIONS VS. GRADIENT DESCENT VS STOCHASTIC GRADIENT DESCENT VS MINI-BATCH LEARNING. WHAT IS THE DIFFERENCE?
In order to explain the differences between alternative approaches to estimating the parameters of a model, let's take a look at a concrete example: Ordinary Least Squares (OLS) Linear Regression. The illustration below shall serve as a quick reminder to recall the different components of a simple linear regression model:
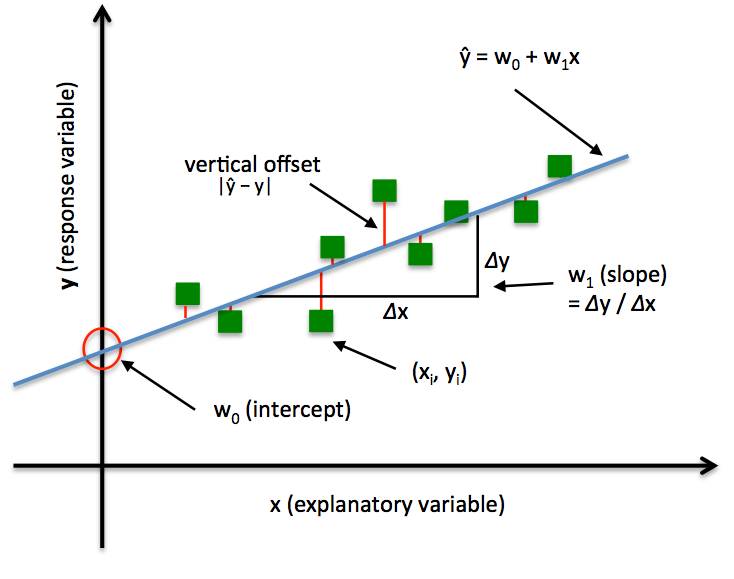
In Ordinary Least Squares (OLS) Linear Regression, our goal is to find the line (or hyperplane) that minimizes the vertical offsets. Or, in other words, we define the best-fitting line as the line that minimizes the sum of squared errors (SSE) or mean squared error (MSE) between our target variable (y) and our predicted output over all samples i in our dataset of size n.
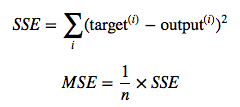
Now, we can implement a linear regression model for performing ordinary least squares regression using one of the following approaches:
- Solving the model parameters analytically (closed-form equations)
- Using an optimization algorithm (Gradient Descent, Stochastic Gradient Descent, Newton's Method, Simplex Method, etc.)
1) NORMAL EQUATIONS (CLOSED-FORM SOLUTION)
The closed-form solution may (should) be preferred for "smaller" datasets -- if computing (a "costly") matrix inverse is not a concern. For very large datasets, or datasets where the inverse of XTX may not exist (the matrix is non-invertible or singular, e.g., in case of perfect multicollinearity), the GD or SGD approaches are to be preferred. The linear function (linear regression model) is defined as:
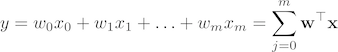
where y is the response variable, x is an m-dimensional sample vector, and w is the weight vector (vector of coefficients). Note that w0 represents the y-axis intercept of the model and therefore x0=1. Using the closed-form solution (normal equation), we compute the weights of the model as follows:
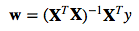
2) GRADIENT DESCENT (GD)
Using the Gradient Decent (GD) optimization algorithm, the weights are updated incrementally after each epoch (= pass over the training dataset).
The cost function J(⋅), the sum of squared errors (SSE), can be written as:
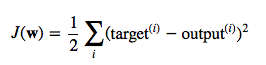
The magnitude and direction of the weight update is computed by taking a step in the opposite direction of the cost gradient
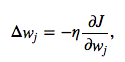
where η is the learning rate. The weights are then updated after each epoch via the following update rule:
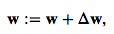
where Δw is a vector that contains the weight updates of each weight coefficient w, which are computed as follows:
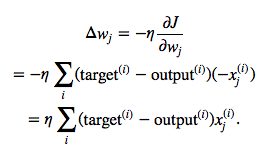
Essentially, we can picture GD optimization as a hiker (the weight coefficient) who wants to climb down a mountain (cost function) into a valley (cost minimum), and each step is determined by the steepness of the slope (gradient) and the leg length of the hiker (learning rate). Considering a cost function with only a single weight coefficient, we can illustrate this concept as follows:
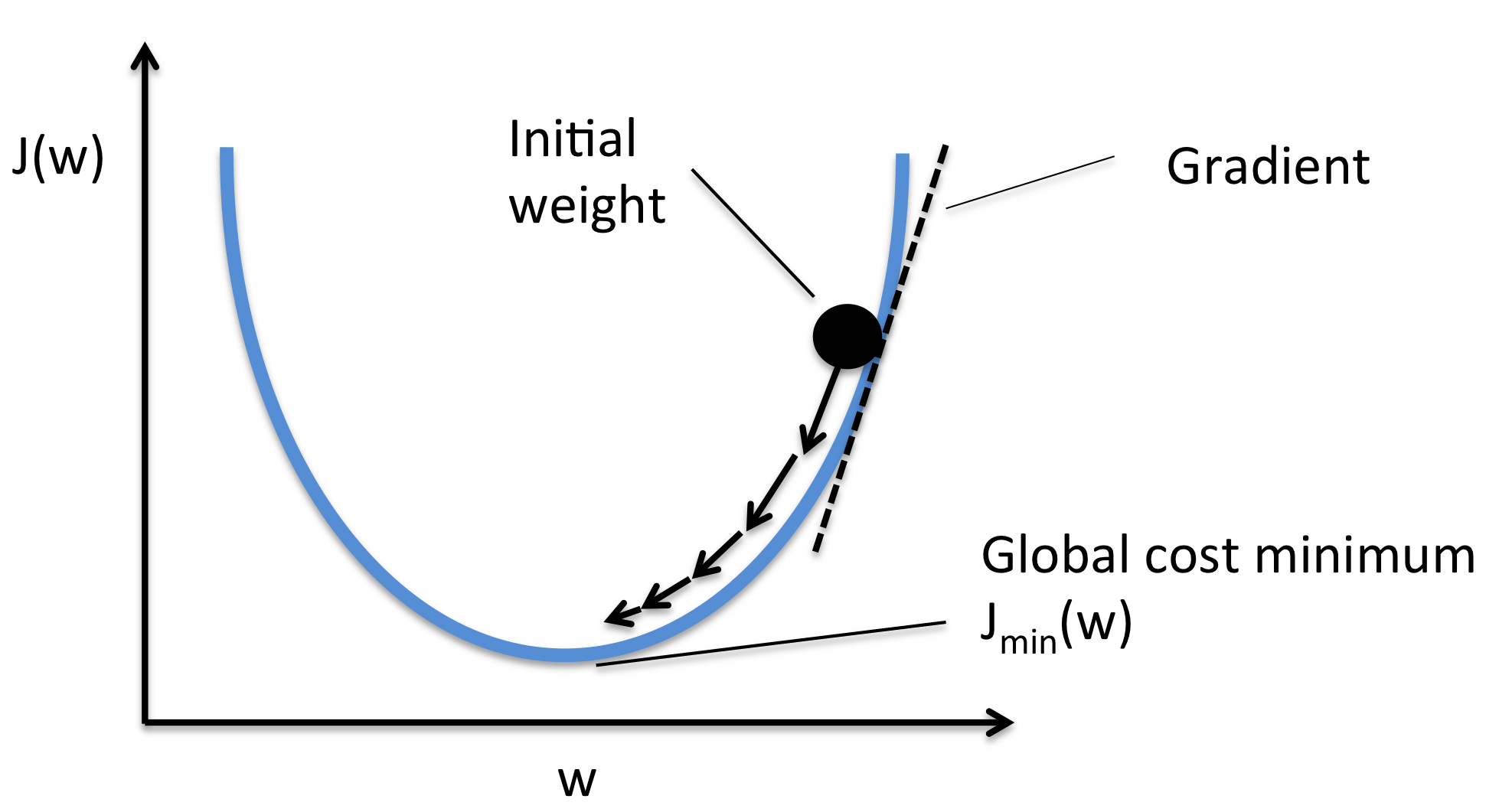
3) STOCHASTIC GRADIENT DESCENT (SGD)
In GD optimization, we compute the cost gradient based on the complete training set; hence, we sometimes also call itbatch GD. In case of very large datasets, using GD can be quite costly since we are only taking a single step for one pass over the training set -- thus, the larger the training set, the slower our algorithm updates the weights and the longer it may take until it converges to the global cost minimum (note that the SSE cost function is convex).
In Stochastic Gradient Descent (SGD; sometimes also referred to as iterative or on-line GD), we don't accumulate the weight updates as we've seen above for GD:
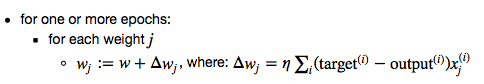
Instead, we update the weights after each training sample:

Here, the term "stochastic" comes from the fact that the gradient based on a single training sample is a "stochastic approximation" of the "true" cost gradient. Due to its stochastic nature, the path towards the global cost minimum is not "direct" as in GD, but may go "zig-zag" if we are visualizing the cost surface in a 2D space. However, it has been shown that SGD almost surely converges to the global cost minimum if the cost function is convex (or pseudo-convex)[1]. Furthermore, there are different tricks to improve the GD-based learning, for example:
An adaptive learning rate η Choosing a decrease constant d that shrinks the learning rate over time:
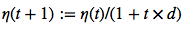
Momentum learning by adding a factor of the previous gradient to the weight update for faster updates:
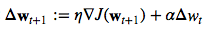
A NOTE ABOUT SHUFFLING
There are several different flavors of SGD, which can be all seen throughout the literature. Let's take a look at the three most common variants:
A)
- randomly shuffle samples in the training set
- for one or more epochs, or until approx. cost minimum is reached
- for training sample i
- compute gradients and perform weight updates
- for training sample i
- for one or more epochs, or until approx. cost minimum is reached
B)
- for one or more epochs, or until approx. cost minimum is reached
- randomly shuffle samples in the training set
- for training sample i
- compute gradients and perform weight updates
- for training sample i
- randomly shuffle samples in the training set
C)
- for iterations t, or until approx. cost minimum is reached:
- draw random sample from the training set
- compute gradients and perform weight updates
- draw random sample from the training set
In scenario A [3], we shuffle the training set only one time in the beginning; whereas in scenario B, we shuffle the training set after each epoch to prevent repeating update cycles. In both scenario A and scenario B, each training sample is only used once per epoch to update the model weights.
In scenario C, we draw the training samples randomly with replacement from the training set [2]. If the number of iterationst is equal to the number of training samples, we learn the model based on a bootstrap sample of the training set.
4) MINI-BATCH GRADIENT DESCENT (MB-GD)
Mini-Batch Gradient Descent (MB-GD) a compromise between batch GD and SGD. In MB-GD, we update the model based on smaller groups of training samples; instead of computing the gradient from 1 sample (SGD) or all n training samples (GD), we compute the gradient from 1 < k < n training samples (a common mini-batch size is k=50).
MB-GD converges in fewer iterations than GD because we update the weights more frequently; however, MB-GD let's us utilize vectorized operation, which typically results in a computational performance gain over SGD.
REFERENCES
- [1] Bottou, Léon (1998). "Online Algorithms and Stochastic Approximations". Online Learning and Neural Networks. Cambridge University Press. ISBN 978-0-521-65263-6
- [2] Bottou, Léon. "Large-scale machine learning with SGD." Proceedings of COMPSTAT'2010. Physica-Verlag HD, 2010. 177-186.
- [3] Bottou, Léon. "SGD tricks." Neural Networks: Tricks of the Trade. Springer Berlin Heidelberg, 2012. 421-436.
FITTING A MODEL VIA CLOSED-FORM EQUATIONS VS. GRADIENT DESCENT VS STOCHASTIC GRADIENT DESCENT VS MINI-BATCH LEARNING. WHAT IS THE DIFFERENCE?的更多相关文章
- Python之路-(Django(csrf,中间件,缓存,信号,Model操作,Form操作))
csrf 中间件 缓存 信号 Model操作 Form操作 csrf: 用 django 有多久,我跟 csrf 这个概念打交道就有久了. 每次初始化一个项目时都能看到 django.middlewa ...
- 最大似然估计实例 | Fitting a Model by Maximum Likelihood (MLE)
参考:Fitting a Model by Maximum Likelihood 最大似然估计是用于估计模型参数的,首先我们必须选定一个模型,然后比对有给定的数据集,然后构建一个联合概率函数,因为给定 ...
- django 用model来简化form
django里面的model和form其实有很多地方有相同之处,django本身也支持用model来简化form 一般情况下,我们的form是这样的 from django import forms ...
- Django(八)下:Model操作和Form操作、序列化操作
二.Form操作 一般会创建forms.py文件,单独存放form模块. Form 专门做数据验证,而且非常强大.有以下两个插件: fields :验证(肯定会用的) widgets:生成HTML(有 ...
- Django(八)上:Model操作和Form操作
↑↑↑点上面的”+”号展开目录 Model和Form以及ModelForm简介 Model操作: 创建数据库表结构 操作数据库表 做一部分的验证 Form操作: 数据验证(强大) ModelForm ...
- day23 Model 操作,Form 验证以及序列化操作
Model 操作 1创建数据库表 定制表名: 普通索引: 创建两个普通索引,这样就会生成两个索引文件 联合索引: 为了只生成一个索引文件,才 ...
- [Angular2 Form] Reactive form: valueChanges, update data model only when form is valid
For each formBuild, formControl, formGroup they all have 'valueChanges' prop, which is an Observable ...
- 提高神经网络的学习方式Improving the way neural networks learn
When a golf player is first learning to play golf, they usually spend most of their time developing ...
- [C2P3] Andrew Ng - Machine Learning
##Advice for Applying Machine Learning Applying machine learning in practice is not always straightf ...
随机推荐
- Download the WDK, WinDbg, and associated tools
Download the WDK, WinDbg, and associated tools This is where you get your Windows Driver Kit (WDK) a ...
- angularjs中只显示选中的radio的值
angularjs中,只显示选中的radio的值.主要是相同的radio,name属性值要相同还有ng-model的值要相同,同时要指定value值.这样选中的时候就会在下面的div中显示选中的值了. ...
- How to get date from OAMessageDateFieldBean
OAMessageDateFieldBean dateFromBean = (OAMessageDateFieldBean)webBean.findChildRecursive("pRece ...
- MySQL server has gone away的解决方法
用Python写了一个http服务,需要从mysql读数据库,第一天还好好的,第二天突然不行了.报错如下: pymysql.err.OperationalError: (2006, 'MySQL se ...
- [CareerCup] 9.5 Permutations 全排列
9.5 Write a method to compute all permutations of a string. LeetCode上的原题,请参加我之前的博客Permutations 全排列和P ...
- 总体最小二乘(TLS)
对于见得多了的东西,我往往就习以为常了,慢慢的就默认了它的存在,而不去思考内在的一些道理.总体最小二乘是一种推广最小二乘方法,本文的主要内容参考张贤达的<矩阵分析与应用>. 1. 最小二乘 ...
- [转]细说MySQL Explain和Optimizer Trace简介
在开发过程中,对每个上线的SQL查询指纹(query figerprint)的质量都应有估算:而估算DB查询质量最直接的方法,就是分析其查询执行计划( Query Execution Plan ,即Q ...
- 【总结】学习Socket编写的聊天室小程序
1.前言 在学习Socket之前,先来学习点网络相关的知识吧,自己学习过程中的一些总结,Socket是一门很高深的学问,本文只是Socket一些最基础的东西,大神请自觉绕路. 传输协议 TCP:Tra ...
- 如何优雅的写一篇安利文-以Sugar ORM为例
前言 我最近喜欢把写的十分优美的技术文章叫做安利文.首先,文章必须是原创而非软广:其次,阅读之后不仅能快速吸纳技术要点并入门开发,还能感同身受的体会作者热情洋溢的赞美和急于分享心得体验的心情,让人感觉 ...
- -webkit-overflow-scrolling:touch iosBug
IOS8+ -webkit-overflow-scrolling:touch 会导致webview崩溃 解决方案 用js动态添加样式 比如: $("body").css(&qu ...