Java笔记(六)列表和队列
列表和队列
一)ArrayList
1.基本原理
ArrayList是一个泛型容器。内部会有一个数组elementData,一般会有预留空间
有一个整数记录实际的元素个数。
private transient Object[] elementData;
private int size;
2.迭代
1)foreach:
foreach的背后,编译器会把它转换为:
Iterator<Integer> it = intList.iterator();
while(it.hasNext()){
System.out.println(it.next());
}
只要对象实现了Iterable接口,就可以使用foreach语法。
另外除了iterator()方法,ArrayList还提供了两个返回Iterator的方法:
public ListIterator<E> listIterator() //返回的迭代从0开始
public ListIterator<E> listIterator(int index) //返回的迭代从指定的index开始
ListIterator扩展了Iterator接口:
public interface ListIterator<E> extends Iterator<E> {
boolean hasPrevious();
E previous();
int nextIndex();
int previousIndex();
void set(E e);
void add(E e);
}
2)迭代的陷阱
1)在迭代的时候调用容器的删除方法:
public class Test {
public static void main(String[] args) {
Integer[] arr = new Integer[] {1, 2, 3, 111, 666, 999};
ArrayList<Integer> list = new ArrayList<Integer>(Arrays.asList(arr));
remove(list); //java.util.ConcurrentModificationException 并发修改异常
}
private static void remove(ArrayList<Integer> list) {
for (Integer i : list) {
if (i < 100) list.remove(i);
}
}
}
因为迭代器内部会维护一些索引位置相关的数据,要求在迭代的
过程中,容器不能发生结构性变化(添加、删除和插入元素),
否则索引的位置就失效了。解决办法:
private static void remove2(ArrayList<Integer> list) {
Iterator<Integer> it = list.iterator();
while (it.hasNext()) {
if (it.next() < 100) {
it.remove();
}
}
}
3)迭代的原理
略
4)迭代器的优势
从封装的思路上讲,迭代器封装了各种数据组织方式的迭代操作,提供了简单一致的接口。
3.ArrayList实现的接口
1)Collection
Collection表示一个数据集合,数据间没有位置或顺序的概念。
public interface Collection<E> extends Iterable<E> {
int size();
boolean isEmpty();
boolean contains(Object o);
Iterator<E> iterator();
Object[] toArray();
<T> T[] toArray(T[] a);
boolean add(E e);
boolean remove(Object o);
boolean containsAll(Collection<?> c);
boolean addAll(Collection<? extends E> c);
boolean removeAll(Collection<?> c);
boolean retainAll(Collection<?> c);
void clear();
boolean equals(Object o);
int hashCode();
}
2)List
List表示有顺序或者位置的数据集合,它扩展了Collection。
boolean addAll(int index, Collection<? extends E> c);
E get(int index);
E set(int index, E element);
void add(int index, E element);
E remove(int index);
int indexOf(Object o);
int lastIndexOf(Object o);
ListIterator<E> listIterator();
ListIterator<E> listIterator(int index);
List<E> subList(int fromIndex, int toIndex);
这些方法都与位置有关。
3)RandomAccess
public interface RandomAccess {
}
居然没有定义任何代码,这种没有任何代码的接口称为标记接口,用于声明类的一种属性。
这里实现了RandomAccess接口的类表示可以随机访问,可随机访问就是具备类似数组数组
那样的特性,数据在内存中是连续存放的,根据索引值就可以定位到具体的元素,访问效率高。
有没有声明该接口有什么关系呢?主要用于一些通用的算法代码中,它可以根据这个声明而选择
效率更高的实现。
4.ArrayList的其他方法
构造方法:
public ArrayList(int initialCapacity) //会初始化内部数组的大小,在知道元素长度的情况下,该构造方法可以避免重新分配和复制数组。
public ArrayList(Collection<? extends E> c) //复制一份数据到当前ArrayList中去
两个返回数组的方法:
public Object[] toArray()
public <T> T[] toArray(T[] a) //如果参数数组的长度足够,是复制数据到该数组,并返回值,不够就新建一个数组
另外需要注意Arrays中有一个静态方法asList可以将数组转换为List,例如:
Integer[] a = {1,2,3};
List<Integer> list = Arrays.asList(a);
该方法返回的List并不是ArrayList,而是Arrays的一个内部类,在这个内部类实现中,
内部用的数组就是传入的数组,没有拷贝,也不会动态改变大小,所以对数组的修改也会
反应到List中,对List调用add,remove方法会抛出异常。
要用ArrayList的完整方法应该:
List<Integer> list = new ArrayList<Integer>(Arrays.asList(a));
ArrayList还提供了两个方法,可以控制内部使用的数组的大小:
//确保数组的大小至少为minCapacity,如果预知数组较大,可以调用它以减少内存分配次数
public void ensureCapacity(int minCapacity)
//该方法会重新分配一个数组,大小刚好为实际内容的长度
//调用该方法可以节省数组占用的空间
public void trimToSize()
5.ArrayList特点分析
作为程序员,就是要理解每种数据结构的特点,根据场合的不同,选择不同的数据结构。
对于ArrayList它的内部是采用动态数组实现的,这就决定了:
1)可以随机访问,按照索引位置进行访问的效率很高,为O(1)
2)除非数组已经排序,否则按照内容查找的效率很低O(N)
3)append元素的效率还行,重新分配和复制数组的开销被平摊了,添加N个元素的效率为O(N)
4)插入和删除元素的效率低,因为要移动元素,效率为O(N)
5)不是线程安全的
二)LinkedList
1.用法
public LinkedList()
public LinkedList(Collection<? extends E> c)
除了实现List接口外,LinkedList还实现了队列接口Queue(先进先出,从头部删除元素,尾部添加元素)。
public interface Queue<E> extends Collection<E> {
boolean add(E e); //在尾部添加元素,队列满时抛出异常
boolean offer(E e); //在尾部添加元素,队列满时返回false
E remove(); //返回头部元素,并从队列中删除,队列为空时抛出异常
E poll(); //返回头部元素,并从队列中删除,队列为空时返回null
E element(); //返回头部元素,但不改变队列,队列为空时抛出异常
E peek(); //返回头部元素,但不改变队列,队列为空时返回null
}
其实LinkedList实现的是双端队列接口Dueue(双端队列可以当作栈使用,先进后出),
Dueue接口继承自队列接口Queue。Dueue的主要方法:
void push(E e);//入栈,即头部添加元素,栈满抛出异常
E pop();//出栈,返回头部元素,并从栈中删除,栈空抛异常
E peek();//查看栈头部元素,不修改栈,如果栈为空,返回null
所以双端队列即是队列,也是栈。栈只操作头部,队列两端都操作,但尾部
只添加,头部只查看和删除。此外双端队列还包括如下方法:
void addFirst(E e);
void addLast(E e);
E getFirst();
E getLast();
boolean offerFirst(E e);
boolean offerLast(E e);
E peekFirst();
E peekLast();
E pollFirst();
E pollLast();
E removeFirst();
E removeLast();
双端队列还有一个迭代器方法:
Iterator<E> descendingIterator();
2.实现原理
1)内部组成
它的内部实现是双向链表,每个元素都是单独存放的,
元素之间通过链链接在一起。为了表示链接关系需要
有一个节点的概念:
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
LinkedList的内部组成就是如下三个实例变量:
transient int size = 0; //链表长度
transient Node<E> first; //表示头节点
transient Node<E> last;//表示尾节点
LinkedList的所有public方法内部都是操作的这三个变量。
2)add方法
add方法代码:
public boolean add (E e) {
linkLast(e);
return true;
}
linkLast方法:
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
由此可以看出,于ArrayList不同LinkedList的内存是按需分配的,
不需要预先分配多余的内存,添加元素只需要分配新元素的空间,然后调节链接就可以了。
3)根据索引访问元素的get方法
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
//该方法检查索引的有效性
private void checkElementIndex(int index) {
if (!isElementIndex(index))
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
private boolean isElementIndex(int index) {
return index >= 0 && index < size;
}
Node<E> node(int index) {
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
由node方法可以看出,与ArrayList不同用索引获取元素效率很低。
4)根据内容查找
public int indexOf(Object o) {
int index = 0;
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null)
return index;
index++;
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item))
return index;
index++;
}
}
return -1;
}
效率同样也不高。
5)从中间插入元素
使用方法:
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}
可以看出,在中间插入元素,LinkedList需要按需分配内存,修改前驱和后继节点的链接,
虽然效率不高,但ArrayList可能需要分配额外的内存空间,且移动所有元素,相比效率更低。
6)删除元素
public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));
}
其他略。应该比ArrayList效率高。
3.LinkedList特点总结
1)按需分配,不需要预先分配很多空间
2)不可以随机访问(必须从头或尾顺着链接找),按索引访问效率低。O(N/2)
3)不管队列是否排列,只要是按内容查找,效率都比较低,必须逐个比较。O(N)
4)在两端添加,删除效率很高,为O(1)。
5)在中间插入、删除,要先定位,效率比较低,为O(N),但修改本身效率很高,为O(1)。
三)ArrayDeque
Java容器类中还有一个双端队列的实现类ArrayDeque,它是基于数组实现的。
该容器类主要解决了插入和删除元素效率低的问题。构造方法:
public ArrayDeque()
public ArrayDeque(int numElements) //numElement初始分配的最小元素个数
public ArrayDeque(Collection<? extends E> c)
主要实例变量:
private transient E[] elements;
private transient int head;
private transient int tail;
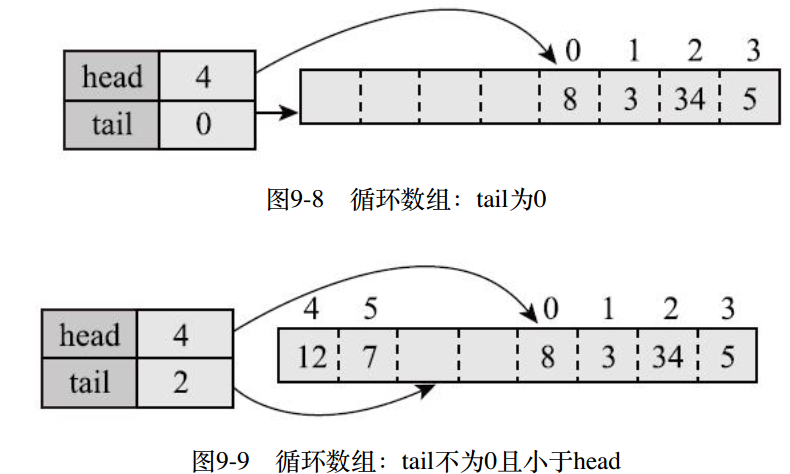
ArrayDeque的高效来源于head和tail这两个变量,这三个变量构建了循环数组。
1.循环数组
所谓循环数组,是指元素到数组尾后可以接着从数组头开始,
数组的长度、第一个和最后一个元素都与head和tail这两变量相关,具体说:
1)如果head和tail相同,则数组为空,长度为0;
2)如果tail大于head,则第一个元素为elements[head],最后一个元素为elements[tail-1]
长度为tail-head,元素索引为head,到tail-1;
3)如果tail小于head,且为0,则第一个元素为elements[head],
最后一个为elements[elements.length-1],元素索引从head到elements.length-1;
4)如果tail小于head,且大于0,则会形成循环,第一个元素为elements[head],
最后一个元素为elements[tail-1],元素索引从head到elements.length-1,然后从0到tail-1。

2.构造方法
默认构造方法:
public ArrayDeque() {
elements = new Object[16];
}
有参数的:
public ArrayDeque(int numElements) {
allocateElements(numElements);
}
allocateElements 作用:计算应该分配的数组长度。
最后一个构造函数:
public ArrayDeque(Collection<? extends E> c) {
allocateElements(c.size());
addAll(c);
}
各种方法实现细节略
3.ArrayDeque特定总结
1)在两端添加、删除元素的效率很高,添加N个效率为O(N);
2)根据元素内容查找和删除的效率比较低为O(N)
3)没有索引的概念,不能进行索引操作。
总之和LinkedList比较,如果只需要使用Deque接口的方法ArrayDeque效率更高。
如果需要经常在中间进行插入和删除或者要使用索引LinkedList更好。
另外,本节介绍的三种容器类型,按内容查找的效率都很低。
Java笔记(六)列表和队列的更多相关文章
- python学习笔记六——堆栈和队列
4.2.3 列表的查找.排序.反转 list列表可以进行添加.删除操作,此外List列表还提供了查找元素的方法.list列表的查找提供了两种方式,一种是使用index方法返回元素在列表中的位置,另一种 ...
- Java笔记整理列表
整理Java相关知识点. 2018-11-20 1:Java入门学习 2:Java进阶
- Java笔记(六)……程序流程控制
判断结构 三种结构: 1: if(条件表达式) 2: { 3: 执行语句; 4: } 5: 6: if(条件表达式) 7: { 8: 执行语句; 9: } 10: else 11: { 12: 执行 ...
- java之jvm学习笔记六-十二(实践写自己的安全管理器)(jar包的代码认证和签名) (实践对jar包的代码签名) (策略文件)(策略和保护域) (访问控制器) (访问控制器的栈校验机制) (jvm基本结构)
java之jvm学习笔记六(实践写自己的安全管理器) 安全管理器SecurityManager里设计的内容实在是非常的庞大,它的核心方法就是checkPerssiom这个方法里又调用 AccessCo ...
- Java IO学习笔记六:NIO到多路复用
作者:Grey 原文地址:Java IO学习笔记六:NIO到多路复用 虽然NIO性能上比BIO要好,参考:Java IO学习笔记五:BIO到NIO 但是NIO也有问题,NIO服务端的示例代码中往往会包 ...
- java笔记整理
Java 笔记整理 包含内容 Unix Java 基础, 数据库(Oracle jdbc Hibernate pl/sql), web, JSP, Struts, Ajax Spring, E ...
- Java笔记 —— 继承
Java笔记 -- 继承 h2{ color: #4ABCDE; } a{ text-decoration: none!important; } a:hover{ color: red !import ...
- 转:最近5年133个Java面试问题列表
最近5年133个Java面试问题列表 Java 面试随着时间的改变而改变.在过去的日子里,当你知道 String 和 StringBuilder 的区别就能让你直接进入第二轮面试,但是现在问题变得越来 ...
- 近5年133个Java面试问题列表
Java 面试随着时间的改变而改变.在过去的日子里,当你知道 String 和 StringBuilder 的区别就能让你直接进入第二轮面试,但是现在问题变得越来越高级,面试官问的问题也更深入. 在我 ...
随机推荐
- axure--中继器
*****中继器-repeater*****1.结构:类似于MVC(增删查改)1)中继器数据集:可包括图片.文字.网址(页面)(右键添加,列名尽量使用英 文或拼音) 2)中继器格式:横向.纵向(是否换 ...
- PowerDesigner逆向生成MYSQL数据库表结构总结
由于日常数据建模经常使用PowerDesigner,使用逆向工程能更加快速的生成模型提高效率,所以总结使用如下: 1. 安装MYSQL的ODBC驱动 Connector/ODBC 5.1.1 ...
- java线程间的通信方式
1.同步 synchronized 2.轮询 while volatile 3.wait/notify机制 syncrhoized加锁的线程的Object类的wait()/notify()/not ...
- C#学习-构造函数
如果没有为类显式地定义一个构造函数,则C#编译器会自动生成一个函数体为空的默认无参的实例构造函数. 构造函数主要用于创建类的实例对象. 当调用构造函数创建一个对象时,构造函数会为对象分配内存空间,并初 ...
- Quartz.net 2.4.1 使用记录
项目需要开发一个调度任务工具,用于
- 移动端开发demo—移动端web相册(一)
本文主要是介绍开发移动端web相册这样一案例用到的前置知识. 一.移动端样式 移动端更接近手机原生的方式. 如下是一个angular mobile的demo的例子: 移动端demo做成这样的好处: 在 ...
- awk常见用法
awk作为linux字符搜索,结果统计的实用工具,其在linux日常运维中有着很多的巧妙运用.下面就来技术一下刚刚学到的技巧 #awk命令统计文件夹下所有文件大小 ls -l |awk 'BEGIN ...
- Python_str 的内部功能介绍
float: x.as_integer_ratio():把浮点型转换成分数最简比 x.hex():返回当前值的十六进制表示 x.fromhex():将十六进制字符串转换为浮点型 float与long的 ...
- 经典的XSS案例
在做安全审计的时候,通过常用的<script>alert(1)</script>无法发现该XSS
- 借助CSS Shapes实现元素滚动自动环绕iPhone X的刘海
CSS代码: .box { max-width: 414px; height: 480px; border: solid #000; margin: auto; overflow: auto; } . ...