Python全栈开发记录_第二篇(文件操作及三级菜单栏增删改查)
python3文件读写操作(本篇代码大约100行)
- f = open(xxx.txt, "r", encoding="utf-8") 不写“r”(只读)默认是只读方式打开,可以改成“w”(只写,覆盖写,若没有则创建),"a"(只追加写),操作系统有自己的编码,open在打开文件的时候默认使用操作系统的编码(win7\8--->gbk,mac/linux---->utf-8),所以为了避乱乱码可以使用encoding="utf-8"
- f.read(5) 从开头开始读5个字符,中文和英文数字都算是一个字符
- f.write() 多次使用的话就一直在后面写入内容,紧挨着
- f.readline() 按行读,读出来之后除了内容还会打印换行符,所以中间还会空一行
- f.readlines() 将文件所有行读出来存在列表中,按行存储
- for i in f: 这种是常用的循环读取文件内容的办法,因为for循环会把f做成迭代器,这样在读大文件的时候不会像readlines那样直接全部读取到内存中,而是一行一行取,想下面就是读取的时候在第N行需要修改
f = open("test1.txt", "r", encoding="utf-8") #以utf-8编码格式打开文件
n = 0 #设定行数
for i in f:
n+=1
if n == 5: #当读到第五行时,就在第五行后面加上test字符串
i = ''.join((i,"test"))
print(i.strip())
f.close() - f.tell() 返回文件读取目前光标所在的位置(python3中如果是utf-8的中文,一个中文代表三个位置,加入读“刘”,f.read(1)就能读出来了,但是f.tell()会显示3)
- f.seek(n,2) 从位置2开始偏移n
- f.flush() 方法是用来刷新缓冲区的,即将缓冲区中的数据立刻写入文件,同时清空缓冲区,不需要是被动的等待输出缓冲区写入。
import time,sys
for i in range(30): #print是默认调用了sys.stdout.write()方法将输出打印到控制台
sys.stdout.write("*") #sys.stdout的形式就是print的一种默认输出格式,等于print "%VALUE%"
sys.stdout.flush() #强制刷新缓冲区,立刻进行打印,如果没有这一句就会一直在缓存里面,等到30*0.1秒后一次打印,进度条可以用这样的方式打印
time.sleep(0.1) #这两个程序效果是一样的
for i in range(30):
print("*",end="",flush=True)
time.sleep(0.1) - f.truncate(size) truncate()方法用于截断文件,如果指定了可选参数 size,则表示截断文件为 size 个字符。 如果没有指定 size,则从当前位置起截断;截断之后 size 后面的所有字符被删除。f.truncate(5)表示只保留5个字符,后面的全部删除
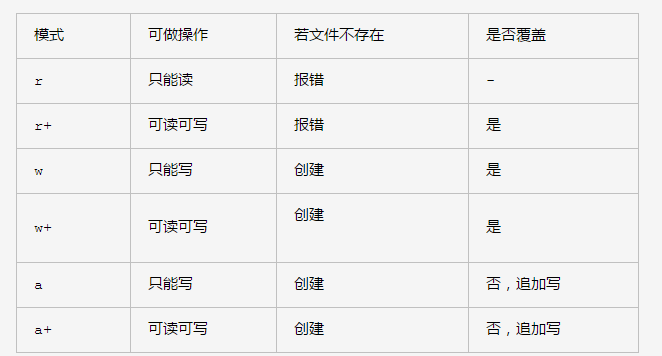
- 文件读写模式总结:从别人博客截来的,感觉总结的不错,注意下,r+(如果直接写文件,则从顶部开始写,覆盖之前此位置的内容,如果先读后写,则会在文件最后追加内容。),而w+是清空覆盖重新写
其他方法:
- fileno() 方法返回一个整型的文件描述符
- isatty() 方法检测文件是否连接到一个终端设备,如果是返回 True,否则返回 False。
文件需要修改的话需要重写新的文件,在写到新的文件的时候可以修改内容(没啥别的办法)。类似下面代码就是这个过程:
f_read = open("test.txt", "r", encoding="utf-8") #以utf-8格式读取出来,不然中文会乱码
f_write = open("test1.txt", "w", encoding="utf-8") #以utf-8格式打开写入,不然写入中文会乱码
number = 0
for i in f_read:
number += 1
#第五行加上喔喔喔喔四个字
if number == 5:
i = ''.join((i.strip(), "喔喔喔喔\n"))
f_write.write(i)
f_write.close()
f_read.close()
with open(xxx) as f这种表达会自动帮你close文件,推荐使用这种方式。刚刚上面的方式可以改写为如下,功能是一样的:
with open("test.txt", "r", encoding="utf-8") as f_read, open("test1.txt", "w", encoding="utf-8") as f_write: #同时管理多个文件对象
number = 0
for i in f_read:
number += 1
#第五行加上喔喔喔喔四个字
if number == 5:
i = ''.join((i.strip(), "喔喔喔喔\n"))
f_write.write(i)
第一篇我们实现过三级菜单的操作,现在这里我们将三级菜单存人文本中,然后可以对菜单进行增删改操作:
下面是menu1菜单:
{
"广东省":{
"深圳市":{
"罗湖区":{},
"福田区":{},
"南山区":{}
},
"广州市":{
"白云区":{},
"天河区":{},
"越秀区":{},
"番禺区":{}
},
"东莞市":{
"虎门镇":{},
"樟木头":{},
"常平镇":{},
"大岭山":{}
}
},
"湖南省":{
"长沙市":{
"雨花区":{},
"岳麓区":{},
"芙蓉区":{}
},
"株洲市":{
"天元区":{},
"沪松区":{}
},
"邵阳市":{
"新邵县":{},
"大祥区":{},
"武冈":{},
"隆回县":{}
}
}
}
下面是实现代码:
# -*- coding:utf-8 -*- '''
需求:
1、展示省市县(数据存在文件中)
2、对菜单实现可以增删改省市县 思路:
1、菜单存在文件里面,读取出来是str格式,通过eval(将字符串string对象转化为有效的表达式参与求值运算返回计算结果)转化成字典
2、对比原来的功能多了增加(add)、修改(change)、删除(delete)操作,这里就是多几个if判断
3、用户操作完之后呢,就需要修改完再以str格式写回文件内 ''' #第三版(实用版,通过文件存储信息然后操作) #通过读取文件读取菜单栏
with open("menu1", "r", encoding="utf-8") as f:
# str转化成字典
menu_dict = eval(f.read().strip()) #退出的标识位
flag = True #通过变量存储变化的菜单栏
current_menu = menu_dict #刚开始就是一级菜单栏 print(current_menu)
#通过列表记录以往的父级菜单
menu_list = [] while flag:
print(menu_list)
#打印菜单栏内容,跟current_menu有关
for menu in current_menu:
print(menu)
choice_menu = input("请选择需要查询的地区或增加(add)、修改(change)、删除(delete)操作,b返回上一层,q退出:").strip()
#查询
if choice_menu in current_menu:
#将父级菜单加入列表
menu_list.append(current_menu)
#变量存储子级菜单
current_menu = current_menu[choice_menu]
if not current_menu:
print("最后一层了")
#新增
elif choice_menu == "add":
menu_add = input("请输入要增加的内容:").strip()
if menu_add in current_menu:
print("你输入的已存在!")
else:
current_menu[menu_add] = {}
#修改
elif choice_menu == "change":
menu_old = input("请输入你要修改的内容:").strip()
if menu_old in current_menu:
menu_new = input("请输入你要修改为:")
current_menu[menu_new] = current_menu[menu_old]
current_menu.pop(menu_old)
else:
print("你输入要修改的内容不存在!")
#删除
elif choice_menu == "delete":
menu_delete = input("请输入要删除的内容:").strip()
if menu_delete in current_menu:
current_menu.pop(menu_delete)
else:
print("你要删除的内容不存在!")
#返回
elif choice_menu == 'b':
#如果列表记录无内容证明在第一层,所以就不需要执行返回上一层
if len(menu_list) == 0:continue
current_menu = menu_list.pop()
#退出
elif choice_menu == 'q':
flag = False
#如果在第三层直接退出,那么current_menu记录的肯定是第三层内容,所以我们需要拿到第一层所有菜单
if len(menu_list) == 0:
continue
else:
current_menu = menu_list[0]
else:
print("输入有误!") with open("menu1", "w", encoding="utf-8") as f:
#字典转成str写入
new_menu = str(current_menu)
f.write(new_menu)
Python全栈开发记录_第二篇(文件操作及三级菜单栏增删改查)的更多相关文章
- Python全栈开发记录_第一篇(循环练习及杂碎的知识点)
Python全栈开发记录只为记录全栈开发学习过程中一些难和重要的知识点,还有问题及课后题目,以供自己和他人共同查看.(该篇代码行数大约:300行) 知识点1:优先级:not>and 短路原则:a ...
- Python全栈开发记录_第九篇(面向对象(类)的学习)
有点时间没更新博客了,今天就开始学习类了,今天主要是面向对象(类),我们知道面向对象的三大特性,那就是封装,继承和多态.内容参考该博客https://www.cnblogs.com/wupeiqi/p ...
- Python全栈开发记录_第七篇(模块_time_datetime_random_os_sys_hashlib_logging_configparser_re)
这一篇主要是学习python里面的模块,篇幅可能会比较长 模块的概念:在Python中,一个.py文件就称之为一个模块(Module). 模块一共三种: python标准库 第三方模块 应用程序自定义 ...
- Python全栈开发记录_第三篇(linux(ubuntu)的操作)
该篇幅主要记录linux的操作,常见就不记录了,主要记录一些不太常用.难用或者自己忘记了的点. 看到https://www.cnblogs.com/resn/p/5800922.html这篇幅讲解的不 ...
- Python全栈开发记录_第八篇(模块收尾工作 json & pickle & shelve & xml)
由于上一篇篇幅较大,留下的这一点内容就想在这里说一下,顺便有个小练习给大家一起玩玩,首先来学习json 和 pickle. 之前我们学习过用eval内置方法可以将一个字符串转成python对象,不过, ...
- Python全栈开发记录_第四篇(集合、函数等知识点)
知识点1:深拷贝和浅拷贝 非拷贝(=赋值:数据完全共享,内存地址一样,修改一个另一个也变化) 浅拷贝:数据半共享(复制其数据独立内存存放,但是只拷贝成功第一层)像[[1,2],3,4]如果修改列表中列 ...
- Python全栈开发记录_第六篇(生成器和迭代器)
说生成器之前先说一个列表生成式:[x for x in range(10)] ->[0,1,2....,9]这里x可以为函数(因为对python而言就是一个对象而已),range(10)也可 ...
- Python全栈开发记录_第五篇(装饰器)
单独记录装饰器这个知识点是因为这个知识点是非常重要的,必须掌握的(代码大约150行). 了解装饰器之前要知道三个知识点 作用域,上一篇讲到过顺序是L->E->G->B 高阶函数: 满 ...
- Python全栈开发记录_第十篇(反射及选课系统练习)
反射机制:反射就是通过字符串的形式,导入模块:通过字符串的形式,去模块中寻找指定函数,对其进行操作.也就是利用字符串的形式去对象(模块)中操作(查找or获取or删除or添加)成员,一种基于字符串的事件 ...
随机推荐
- java readProperties
@Deprecated public static Map<String, String> readProperties(String propertiesFile) { Properti ...
- Java 获取class method parameter name
package org.rx.util; import org.objectweb.asm.*; import java.io.IOException; import java.io.InputStr ...
- L330 Black hole picture captured for first time in space ‘breakthrough’
Black hole picture captured for first time in space ‘breakthrough’ Astronomers have captured the fir ...
- js 查找当前元素/this
function findTabTitle(pageId) { var $ele = null; $(".page-tabs-content").find("a.menu ...
- 【webdriver自动化】Python数据驱动工具DDT
一.Python数据驱动工具ddt 1. 安装 ddt pip install ddt DDT是 “Data-Driven Tests”的缩写 资料:http://ddt.readthedocs.i ...
- 由一次报错引发的对于Spring创建对象的理解
org.springframework.beans.factory.UnsatisfiedDependencyException: Error creating bean with name 'ent ...
- 【转载】 Deepmind星际争霸2平台使用第一轮-完成采矿
原文地址: https://blog.csdn.net/woaipichuli/article/details/78645999 ----------------------------------- ...
- Gym - 100783G:Playing With Geometry (几何 离散化 )
pro:给定规则的多边形,规则是指顶点都在整点上,而且是相互垂直的边的交点. 现在给定两个多边形A,B,问A,B缩小,旋转后是否可以变为同一个图形. sol:缩小的话,直接离散化即可,就可以去掉没用的 ...
- Redis之在Linux上安装和简单的使用
我只是一个搬运工 Redis之在Linux上安装和简单的使用https://blog.csdn.net/qq_20989105/article/details/76390367 一.安装gcc 1.R ...
- Flex布局-容器的属性
本文部分内容参考阮一峰大神博客,原文地址:http://www.ruanyifeng.com/blog/2015/07/flex-grammar.html Flex布局即弹性布局,使用起来十分方便灵活 ...