(二)SQL Server分区创建过程
虽然分区有很多好处(一)SQL Server分区详解Partition,却不能随意使用;且不说分区管理的繁琐,只是跨分区带来的负面影响就需要我们好好分析是否有必要使用分区。一般分区创建的业务特点:用于统计、历史数据少使用、数据自增长、可能数据冗余大、数据量庞大插入量大。在确定是否合适使用分区前,需了解分区是如何创建的,分区的创建包括:
1、新建分区函数:确定分区的方式和界点。
2、新建文件和文件组:用于存放不同分区数据
3、新建分区架构:将分区行数制定的分区映射到文件组。
4、新建分区表或者分区索引
如下图所示:分区函数定义了分区的具体方式,分区架构使用分区函数和文件组,确定分区方案,表或索引就使用分区架构来实现分区。他们之间是使用关系,一对多的关系。
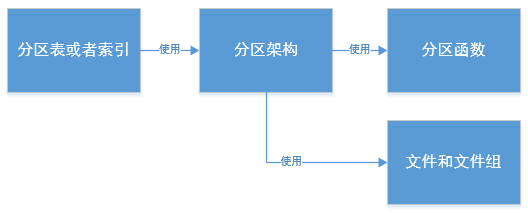
一、创建分区函数
分区函数定义如何根据某些列的值将表或索引的行映射到指定分区。分区函数制定了分区的方式。用作索引列时有效的所有数据类型都可以用作分区依据列,timestamp 除外。无法指定 ntext、text、image、xml、varchar(max)、nvarchar(max) 或 varbinary(max) 数据类型为分区依据列。基本语法如下所示:
CREATE PARTITION FUNCTION partition_function_name ( input_parameter_type )
AS RANGE [ LEFT | RIGHT ]
FOR VALUES ( [ boundary_value [ ,...n ] ] ) [ ; ]
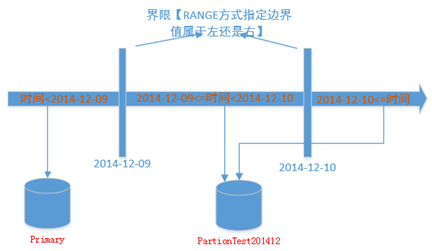
左/右界限RANGE [ LEFT | RIGHT ]
指定左右既是为了确定边界值处于左侧还是右侧。如下图所示RANGE RIGHT,则界限值属于右边。

/*新建分区函数*/
USE [PartionTest];
CREATE PARTITION FUNCTION [pf_PartionTest01] (datetime) AS RANGE right FOR VALUES ('2014-12-09', '2014-12-10' /*分区函数查询*/
SELECT
pf.name 分区函数名称
,CASE WHEN boundary_value_on_right=1 THEN 'RIGHT' ELSE 'LEFT' END 分区界限方式
,value 分区界限值
FROM sys.partition_functions pf
LEFT JOIN sys.partition_range_values prv ON prv.function_id = pf.function_id
ORDER BY boundary_id 查询结果如下:

注意:
1、业务上多数为使用Range Right ,将边界保留在最新分区,毕竟右为后期增长的数据;比如按每天分区的逻辑是将当天的数据存在当天的分区内,假如当天分区为2014-12-08 00:00.000, Range Right 将2014-12-08 00:00.000的数据归于2014-12-08当天,RANGE LEFT则只能将此界限时间归于2014-12-07。与逻辑存在一定差异。
2、既然有分区界限问题,在合并分区的时候,指定分区是向左还是向右合并?
二、创建分区架构
分区架构把分区函数指定的分区映射到文件组;
CREATE PARTITION SCHEME partition_scheme_name
AS PARTITION partition_function_name
[ ALL ] TO ( { file_group_name | [ PRIMARY ] } [ ,...n ] )[ ; ]
分区指定文件组要比分区划分边界多一个,分区架构指定了具体分区数据存放在哪个文件组上。如下图所示:
在创建分区架构之前若有必要需要创建特定的文件和文件组:
1、新建不同文件组若存放在不同逻辑磁盘可以提高io并发能力;
2、同时不同文件可以提高容灾的能力,在某个文件发生顺坏,其他文件可以继续使用。
3、分开文件存储,也可实现不同分区独立备份,提高了数据恢复速率。
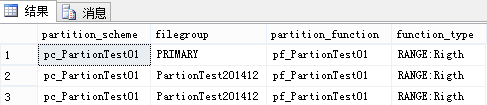
依据已经新建分区函数【pf_PartionTest01】和默认已有文件组,新建以下分区架构:
/*新建分区架构*/
USE [PartionTest];
CREATE PARTITION SCHEME [pc_PartionTest01] AS PARTITION [pf_PartionTest01] TO ('Primary', 'PartionTest201412', 'PartionTest201412')
/*分区架构查询*/
SELECT
ps.name partition_scheme,
ds.name filegroup,
pf.name partition_function,
pf.type_desc+':'+case when pf.boundary_value_on_right=0 then 'Left' else 'Rigth' end function_type
FROM sys.partition_schemes ps
JOIN sys.destination_data_spaces dds ON ps.data_space_id=dds.partition_scheme_id
JOIN sys.data_spaces ds ON dds.data_space_id=ds.data_space_id
JOIN sys.partition_functions pf ON ps.function_id=pf.function_id 结果如下图所示:
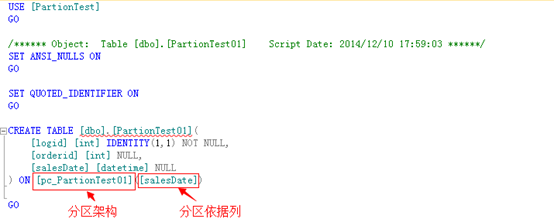
三、创建分区表
如下图所示,只要制定分区架构和分区依据列即可.
四、创建索引分区:索引分区知识详解
(二)SQL Server分区创建过程的更多相关文章
- SQL SERVER分区详解(1-5)
转自: (五)SQL Server分区自动化案例 (四)SQL Server分区管理 (三)索引分区知识详解 (二)SQL Server分区创建过程 (一)SQL Se ...
- (一)SQL Server分区详解Partition(目录)
一.SQL Server分区介绍 在SQL Server中,数据库的所有表和索引都视为已分区表和索引,默认这些表和索引值包含一个分区:也就是说表或索引至少包含一个分区.SQL Server中数据是按水 ...
- sql server 分区(上)
分区发展历程 基于表的分区功能为简化分区表的创建和维护过程提供了灵活性和更好的性能.追溯到逻辑分区表和手动分区表的功能. 二.为什么要进行分区 为了改善大型表以及具有各种访问模式的表的可伸缩 ...
- 你所不知道的SQL Server数据库启动过程,以及启动不起来的各种问题的分析及解决技巧
目前SQL Server数据库作为微软一款优秀的RDBMS,其本身启动的时候是很少出问题的,我们在平时用的时候,很少关注起启动过程,或者很少了解其底层运行过程,大部分的过程只关注其内部的表.存储过程. ...
- SQL Server 触发器创建、删除、修改、查看示例
一﹕ 触发器是一种特殊的存储过程﹐它不能被显式地调用﹐而是在往表中插入记录﹑更新记录或者删除记录时被自动地激活.所以触发器可以用来实现对表实施复杂的完整性约`束. 二﹕ SQL Server为每个触发 ...
- (4.20)SQL Server数据库启动过程,以及启动不起来的各种问题的分析及解决技巧
转自:指尖流淌 https://www.cnblogs.com/zhijianliutang/p/4085546.html SQL Server数据库启动过程,以及启动不起来的各种问题的分析及解决技巧 ...
- SQL Server触发器创建、删除、修改、查看示例步骤
一﹕ 触发器是一种特殊的存储过程﹐它不能被显式地调用﹐而是在往表中插入记录﹑更新记录或者删除记录时被自动地激活.所以触发器可以用来实现对表实施复杂的完整性约`束. 二﹕ SQL Server为每个触发 ...
- 04Microsoft SQL Server 数据库创建,查看,使用,修改及删除
Microsoft SQL Server 数据库创建,查看,使用,修改及删除 创建数据库 创建普通数据库 USE [master] GO CREATE DATABASE [MyDataBase] -- ...
- SQL Server 数据库启动过程,以及启动不起来的各种问题的分析及解决技巧
目前SQL Server数据库作为微软一款优秀的RDBMS,其本身启动的时候是很少出问题的,我们在平时用的时候,很少关注起启动过程,或者很少了解其底层运行过程,大部分的过程只关注其内部的表.存储过程. ...
随机推荐
- [bootsrap]模态框使用例
<a href="#modal1" role="button" class="btn btn-primary btn-sm" data ...
- C#性能优化考虑的几个方向
装箱与拆箱 ArrayList's vs. generic List for primitive types and 64-bits 类型转换 GC 注意SOH对象应该较快,避免内存泄漏 注意LO ...
- Unix哲学
01. 模块原则:使用简洁的接口拼合简单的部件. 02. 清晰原则:清晰胜于机巧. 03. 组合原则:设计时考虑拼接组合. 04. 分离原则:策略同机制分离,接口同引擎分离. 05. 简洁原则:设计要 ...
- Python学习记录day5
title: Python学习记录day5 tags: python author: Chinge Yang date: 2016-11-26 --- 1.多层装饰器 多层装饰器的原理是,装饰器装饰函 ...
- 利用Caffe做回归(regression)
Caffe应该是目前深度学习领域应用最广泛的几大框架之一了,尤其是视觉领域.绝大多数用Caffe的人,应该用的都是基于分类的网络,但有的时候也许会有基于回归的视觉应用的需要,查了一下Caffe官网,还 ...
- TCP/IP四层模型和OSI七层模型
TCP/IP四层模型 TCP/IP是一组协议的代名词,它还包括许多协议,组成了TCP/IP协议簇.TCP/IP协议簇分为四层,IP位于协议簇的第二层(对应OSI的第三层),TCP位于协议簇的第三层(对 ...
- NOIP2003pj栈[卡特兰数]
题目背景 栈是计算机中经典的数据结构,简单的说,栈就是限制在一端进行插入删除操作的线性表. 栈有两种最重要的操作,即pop(从栈顶弹出一个元素)和push(将一个元素进栈). 栈的重要性不言自明,任何 ...
- BZOJ1856[SCOI2010]字符串
Description lxhgww最近接到了一个生成字符串的任务,任务需要他把n个1和m个0组成字符串,但是任务还要求在组成的字符串中,在任意的前k个字符中,1的个数不能少于0的个数.现在lxhgw ...
- IIS部署站点相关经验总结
IIS部署站点相关经验总结 1.IIS和.net4.0安装是有先后顺序的,应该先安装.net framework 4.0,再安装IIS.如果按相反顺序安装的话,IIS中看不到4.0相关的东西,那么只能 ...
- Switch&NAT 测试
测试环境: PC1:Windows10 iperf3 PC2:Ubuntu iperf3 都装有千兆网卡,直连的iperf速度是935Mbps. 因为TXRX两个方向的数据是差不多的,下面的测试数据只 ...