sql server 分区(上)
分区发展历程
基于表的分区功能为简化分区表的创建和维护过程提供了灵活性和更好的性能。追溯到逻辑分区表和手动分区表的功能.
二.为什么要进行分区
为了改善大型表以及具有各种访问模式的表的可伸缩性和可管理性。
大型表除了大小以数百 GB 计算,甚至以 TB 计算的指标外,还可以是无法按照预期方式运行的数据表,运行成本或维护成本超出预定要求。例如发生性能问题、阻塞问题、备份。
三. 分区的概念
分区范围
分区范围是指在要分区的表中,根据业务选择表中的关键字段做为分区边界条件,
分区后,数据所在的具体位置至关重要,这样才能在需要时只访问相应的分区。
注意分区是指数据的逻辑分离,不是数据在磁盘上的物理位置, 数据的位置由文件组来决定,所以一般建议一个分区对应一个文件组。
分区键
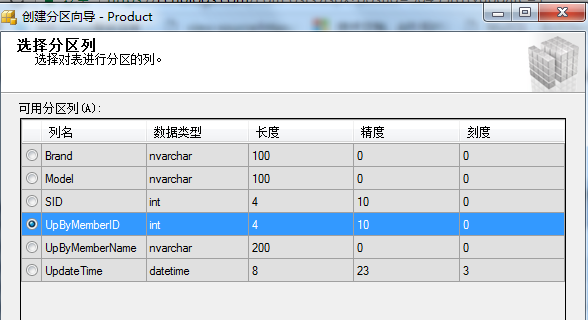
在我下面的演示中,有一个库存表,我选择了UpByMemberID(会员ID) 作为分区键。 对表和索引进行分区的第一步就是定义分区的关键数据。
索引分区
除了对表的数据集进行分区之外,还可以对索引进行分区, 使用相同的函数对表及其索引进行分区通常可以优化性能
在下面的第六步中有创建分区索引。
三.创建分区实现
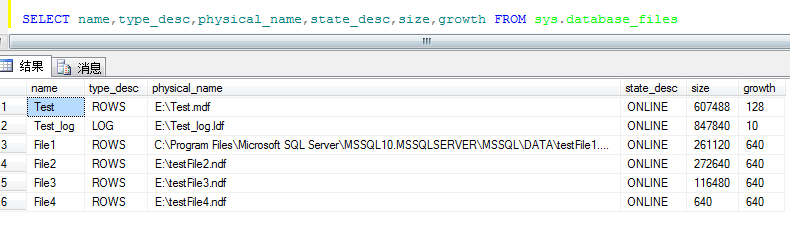
在test库 添加四个文件组, 用于存储每个分区的数据,这里有四个文件组对应四个分区
多个文件组是为了有助于优化性能和维护,应使用文件组分离数据。文件组的数目一定程度上由硬件资源决定:一般情况下,文件组数最好与分区数相同,
并且这些文件组通常位于不同的磁盘上(演示有条有限,只在一个磁盘上做逻辑盘存放)。
--第一步:创建四个文件组
alter database test add filegroup ByIdGroup1
alter database test add filegroup ByIdGroup2
alter database test add filegroup ByIdGroup3
alter database test add filegroup ByIdGroup4
--第二步: 创建四个ndf文件,对应到各文件组中,FILENAME文件存储路径
ALTER DATABASE test ADD FILE(
NAME='File1',
FILENAME='C:\Program Files\Microsoft SQL Server\MSSQL10.MSSQLSERVER\MSSQL\DATA\testFile1.ndf',
SIZE=5MB,
FILEGROWTH=5MB)
TO FILEGROUP ByIdGroup1 ALTER DATABASE test ADD FILE(
NAME='File2',
FILENAME='E:\testFile2.ndf',
SIZE=5MB,
FILEGROWTH=5MB)
TO FILEGROUP ByIdGroup2 ALTER DATABASE test ADD FILE(
NAME='File3',
FILENAME='E:\testFile3.ndf',
SIZE=5MB,
FILEGROWTH=5MB)
TO FILEGROUP ByIdGroup3 ALTER DATABASE test ADD FILE(
NAME='File4',
FILENAME='E:\testFile4.ndf',
SIZE=5MB,
FILEGROWTH=5MB)
TO FILEGROUP ByIdGroup4
执行完成后,查看如下图所示:
--第三步:创建分区函数(每个分区的边界值)
每个会员统计的产品数
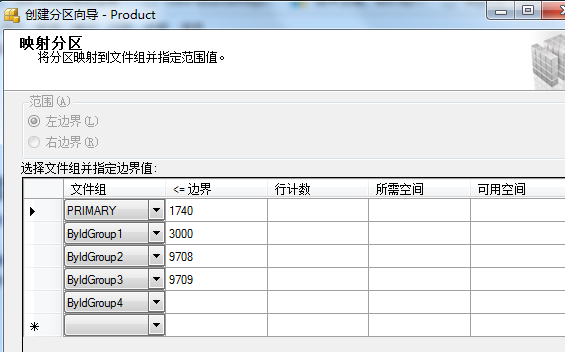
--record: 126797 Partition1 --PRIMARY
SELECT COUNT(1) FROM dbo.Product WHERE UpByMemberID<=1740
--record: 90882 Partition2
SELECT COUNT(1) FROM dbo.Product WHERE UpByMemberID>1740 AND UpByMemberID<=3000
--record: 4999999 Partition3
SELECT COUNT(1) FROM dbo.Product WHERE UpByMemberID>3000 AND UpByMemberID<=9708
--record: 4999999 Partition4
SELECT COUNT(1) FROM dbo.Product WHERE UpByMemberID>9708 AND UpByMemberID<=9709
--record: 2018464 Partition5 ---ByIdGroup4
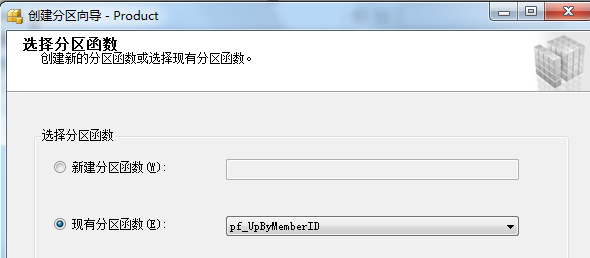
SELECT COUNT(1) FROM dbo.Product WHERE UpByMemberID>9709 CREATE PARTITION FUNCTION pf_UpByMemberID(int)
AS RANGE LEFT FOR VALUES (1740,3000,9708,9709)
执行完后如下图所示:
--第四步:创建分区方案
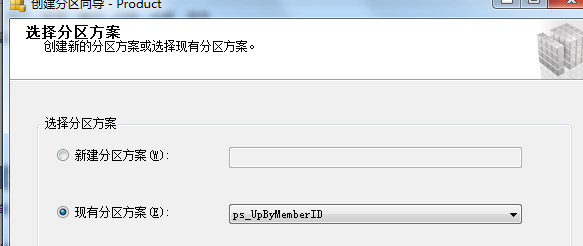
CREATE PARTITION SCHEME ps_UpByMemberID
AS PARTITION pf_UpByMemberID TO ([PRIMARY], [ByIdGroup1],[ByIdGroup2],[ByIdGroup3],[ByIdGroup4])
执行完后如下图所示:
--第五步:创建分区表
右击要分区的表-->存储-->创建分区-->选择分区列(这里UpByMemberID)-->选择分区函数
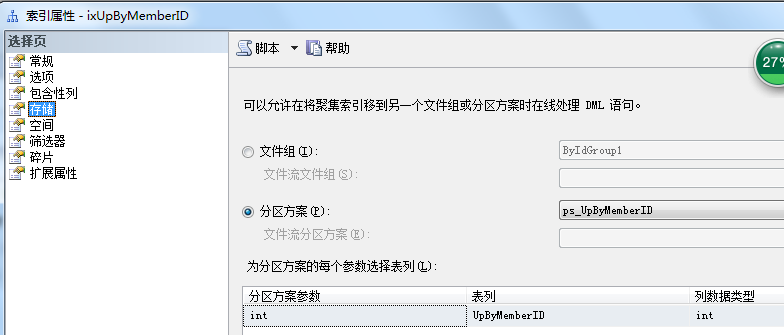
--第六步创建分区索引
CREATE NONCLUSTERED INDEX [ixUpByMemberID] ON [dbo].[Product]
(
[UpByMemberID] ASC
)
INCLUDE ( [Model]) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON)
GO
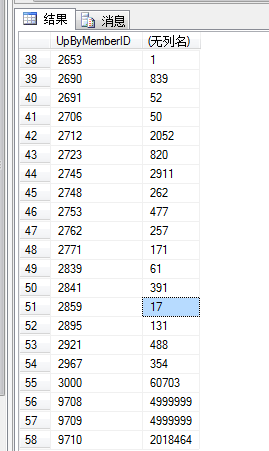
-- 最后 查看各分区有多少行数据
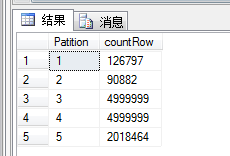
select $PARTITION.pf_UpByMemberID([UpByMemberID]) as Patition,COUNT(*) countRow from dbo.product
group by $partition.pf_UpByMemberID([UpByMemberID])
查出有五个分区(带主分区),以及各分区的数量
最后看下是否用了分区索引
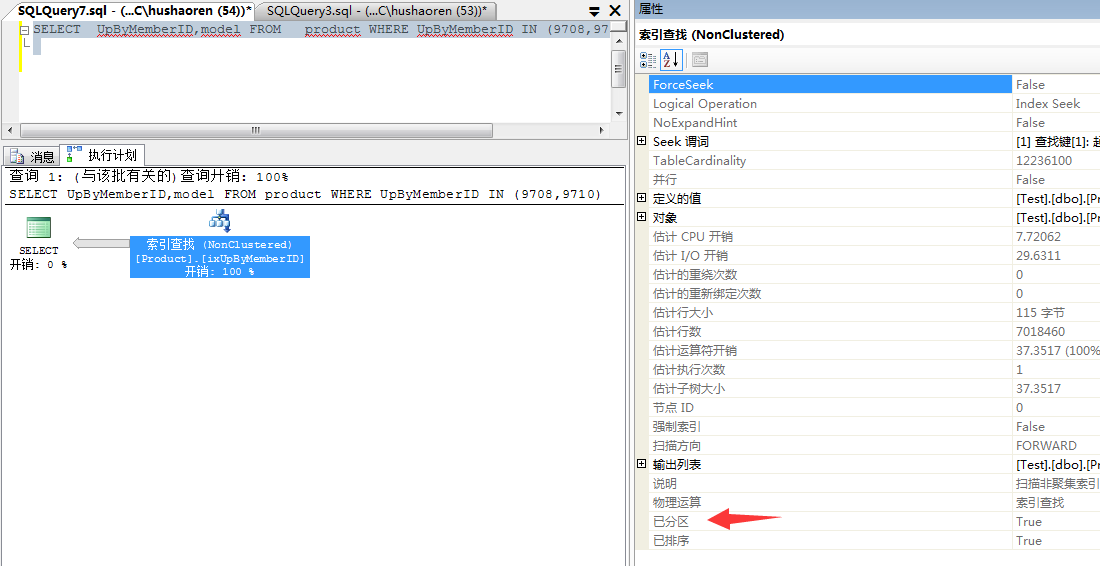
sql server 分区的优势:
- 当表和索引变得非常大时,分区可以将数据分为更小、更容易管理的部分。
- 减少索引维护时间。
- 常用的where条件字段做分区依据是较佳的。
- 并行操作获得更好的性能, 可以改善在极大型数据集(例如数百万行)中执行大规模操作的性能。
- 一般情况下,文件组数最好与分区数相同。文件组允许您将各个表放置到不同的物理磁盘上
sql server 分区(上)的更多相关文章
- (一)SQL Server分区详解Partition(目录)
一.SQL Server分区介绍 在SQL Server中,数据库的所有表和索引都视为已分区表和索引,默认这些表和索引值包含一个分区:也就是说表或索引至少包含一个分区.SQL Server中数据是按水 ...
- Sql Server 分区演练 【转】
Sql Server 分区演练 [转] 代码加注释,希望对初学者有用. USE [master]GOif exists (select * from sys.databases where name ...
- (二)SQL Server分区创建过程
虽然分区有很多好处(一)SQL Server分区详解Partition,却不能随意使用:且不说分区管理的繁琐,只是跨分区带来的负面影响就需要我们好好分析是否有必要使用分区.一般分区创建的业务特点:用于 ...
- SQL SERVER分区视图
借助SQL SERVER分区视图,可以对SQL中的表进行集中管理,下文将以实例的方式为您详解SQL SERVER分区视图,希望对您学习SQL数据库能有所帮助. SQL SERVER分区视图给我们提供了 ...
- 如何知道SQL Server机器上有多少个NUMA节点
如何知道SQL Server机器上有多少个NUMA节点 文章出处: How can you tell how many NUMA nodes your SQL Server has? http://i ...
- SQL Server服务器上需要导入Excel数据的必要条件
SQL Server服务器上需要导入Excel数据,必须安装2007 Office system 驱动程序:数据连接组件,或者Access2010的数据库引擎可再发行程序包,这样就不必在服务器上装Ex ...
- 009.Working with SQL Server LocalDB --【在sql server localdb 上操作数据】
Working with SQL Server LocalDB 在sql server localdb 上操作数据 2017-3-7 2 分钟阅读时长 本文内容 1.SQL Server Expres ...
- SQL SERVER分区详解(1-5)
转自: (五)SQL Server分区自动化案例 (四)SQL Server分区管理 (三)索引分区知识详解 (二)SQL Server分区创建过程 (一)SQL Se ...
- SQL Server分区键列必须是主键一部分
SQL Server分区键列必须是主键一部分. 必须把分区列包含在主键/唯一约束/唯一索引的键列中. USE tempdb GO -- 测试表 CREATE TABLE dbo.tb( id int, ...
随机推荐
- Linux - quota的举例说明
实作 Quota 流程-1:文件系统支持 [root@www ~]# df -h /home Filesystem Size Used Avail Use% Mounted on /dev/hda3 ...
- Windows2008修改密码策略简单介绍
Windows2008修改密码策略简单介绍 Windows的密码策略,确实是挺繁琐的,刚接触SharePoint2010,装的windows2008 R2,就遇到了改密码策略的问题. 打开本地安全策略 ...
- C# 设置Word文档背景(纯色/渐变/图片背景)
Word是我们日常生活.学习和工作中必不可少的文档处理工具.精致美观的文档能给人带来阅读时视觉上的美感.在本篇文章中,将介绍如何使用组件Free Spire.Doc for .NET(社区版)给Wor ...
- jQuery结合lhgdialog弹出窗口,关闭时出现没有权限错误
背景: 最近的项目,使用JQuery+lhgdialog窗口组件方式模拟弹窗,在关闭lhgdialog窗口时,出现以下错误: >jQuery没有权限 >调试时 w.readyState没有 ...
- MOOS学习笔记1——HelloWorld
MOOS学习笔记1--HelloWorld 例程 /* * @功能:通讯客户端的最简单程序,向MOOSDB发送名为"Greeting" * 数据"Hello", ...
- windows from 手风琴
public class OutlookBar : Panel { private int SelectedBandHeight { get; set; } public int ButtonHeig ...
- was上的应用程序部分启动的原因
最近几天为了方便联调,我把两个项目配置到was测试环境上,前几天还好好的,昨天忽然有一个项目反复安装后都呈现部分启动的状态,打开节点一看,偏偏没启动的那个节点就是我需要用的79节点. 这让我很郁闷,硬 ...
- 一个简单的例子搞懂ES6之Promise
ES5中实现异步的常见方式不外乎以下几种: 1. 回调函数 2. 事件驱动 2. 自定义事件(根本上原理同事件驱动相同) 而ES6中的Promise的出现就使得异步变得非常简单.promise中的异步 ...
- js中window对象的opener属性的一个坑
2018-05-08 17:48:33 今天我编写代码碰到了一个让我纠结了很久的坑,特别想在此说一下,让其他人避免我踏过的这个坑. 这个坑就是:在我自己写的子窗口中用opener属性却获取不到父窗口的 ...
- Node笔记一
什么是javascript? --脚本语言 --运行在浏览器中 --一般用来做客户端页面的交互 javascript运行环境 --运行在浏览器内核中的JS引擎 浏览器这种javascript可以做什么 ...