[Search Engine] 搜索引擎技术之网络爬虫

随着互联网的大力发展,互联网称为信息的主要载体,而如何在互联网中搜集信息是互联网领域面临的一大挑战。网络爬虫技术是什么?其实网络爬虫技术就是指的网络数据的抓取,因为在网络中抓取数据是具有关联性的抓取,它就像是一只蜘蛛一样在互联网中爬来爬去,所以我们很形象地将其称为是网络爬虫技术。其中网络爬虫也被称为是网络机器人或者是网络追逐者。
网络爬虫技术是搜索引擎架构中最为根本的数据技术,通过网络爬虫技术,我们可以将互联网中数以百亿计的网页信息保存到本地,形成一个镜像文件,为整个搜索引擎提供数据支撑。
1. 网络爬虫技术基本工作流程和基础架构
网络爬虫获取网页信息的方式和我们平时使用浏览器访问网页的工作原理是完全一样的,都是根据HTTP协议来获取,其流程主要包括如下步骤:
1)连接DNS域名服务器,将待抓取的URL进行域名解析(URL------>IP);
2)根据HTTP协议,发送HTTP请求来获取网页内容。
一个完整的网络爬虫基础框架如下图所示:
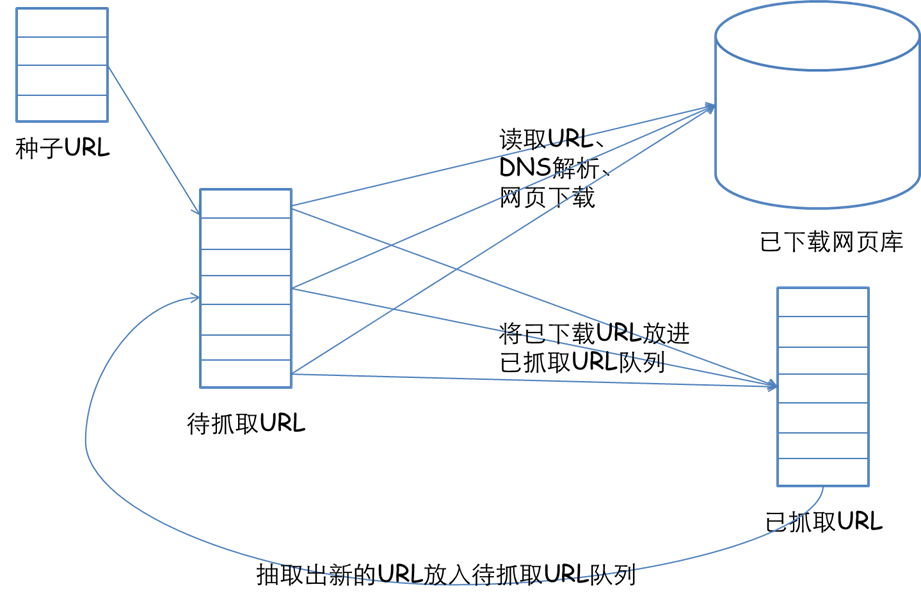
整个架构共有如下几个过程:
1)需求方提供需要抓取的种子URL列表,根据提供的URL列表和相应的优先级,建立待抓取URL队列(先来先抓);
2)根据待抓取URL队列的排序进行网页抓取;
3)将获取的网页内容和信息下载到本地的网页库,并建立已抓取URL列表(用于去重和判断抓取的进程);
4)将已抓取的网页放入到待抓取的URL队列中,进行循环抓取操作;
2. 网络爬虫的抓取策略
在爬虫系统中,待抓取URL队列是很重要的一部分。待抓取URL队列中的URL以什么样的顺序排列也是一个很重要的问题,因为这涉及到先抓取哪个页面,后抓取哪个页面的问题。而决定这些URL排列顺序的方法,叫做抓取策略。下面重点介绍几种常见的抓取策略:
1)深度优先遍历策略
深度优先遍历策略很好理解,这跟我们有向图中的深度优先遍历是一样的,因为网络本身就是一种图模型嘛。深度优先遍历的思路是先从一个起始网页开始抓取,然后对根据链接一个一个的逐级进行抓取,直到不能再深入抓取为止,返回上一级网页继续跟踪链接。
一个有向图深度优先搜索的实例如下所示:
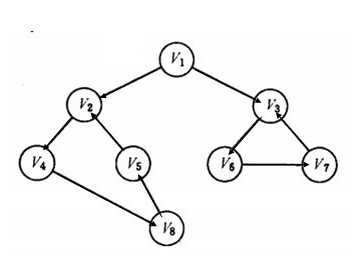

上图左图为一个有向图示意图,右图为深度优先遍历的搜索过程示意图。深度优先遍历的结果为:

2)广度优先搜索策略
广度优先搜索和深度优先搜索的工作方式正好是相对的,其思想为:将新下载网页中发现的链接直接插入待抓取URL队列的末尾。也就是指网络爬虫会先抓取起始网页中链接的所有网页,然后再选择其中的一个链接网页,继续抓取在此网页中链接的所有网页。
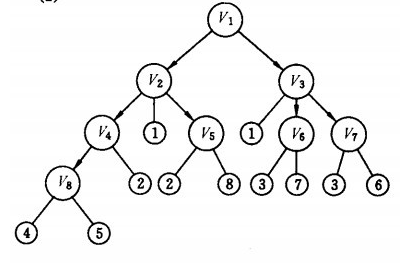
上图为上边实例的有向图的广度优先搜索流程图,其遍历的结果为:
v1→v2 →v3 →v4→ v5→ v6→ v7 →v8
从树的结构上去看,图的广度优先遍历就是树的层次遍历。
3)反向链接搜索策略
反向链接数是指一个网页被其他网页链接指向的数量。反向链接数表示的是一个网页的内容受到其他人的推荐的程度。因此,很多时候搜索引擎的抓取系统会使用这个指标来评价网页的重要程度,从而决定不同网页的抓取先后顺序。
在真实的网络环境中,由于广告链接、作弊链接的存在,反向链接数不能完全等他我那个也的重要程度。因此,搜索引擎往往考虑一些可靠的反向链接数。
4)大站优先策略
对于待抓取URL队列中的所有网页,根据所属的网站进行分类。对于待下载页面数多的网站,优先下载。这个策略也因此叫做大站优先策略。
5)其他搜索策略
一些比较常用的爬虫搜索侧率还包括Partial PageRank搜索策略(根据PageRank分值确定下一个抓取的URL)、OPIC搜索策略(也是一种重要性排序)。最后必须要指明的一点是,我们可以根据自己的需求为网页的抓取间隔时间进行设定,这样我们就可以确保我们基本的一些大站或者活跃的站点内容不会被漏抓。
3. 网络爬虫更新策略
尽管搜索引擎针对于某个查询条件能够返回数量巨大的结果,但是用户往往只关注前几页结果。因此,抓取系统可以优先更新那些现实在查询结果前几页中的网页,而后再更新那些后面的网页。这种更新策略也是需要用到历史信息的。用户体验策略保留网页的多个历史版本,并且根据过去每次内容变化对搜索质量的影响,得出一个平均值,用这个值作为决定何时重新抓取的依据。
3)聚类抽样策略
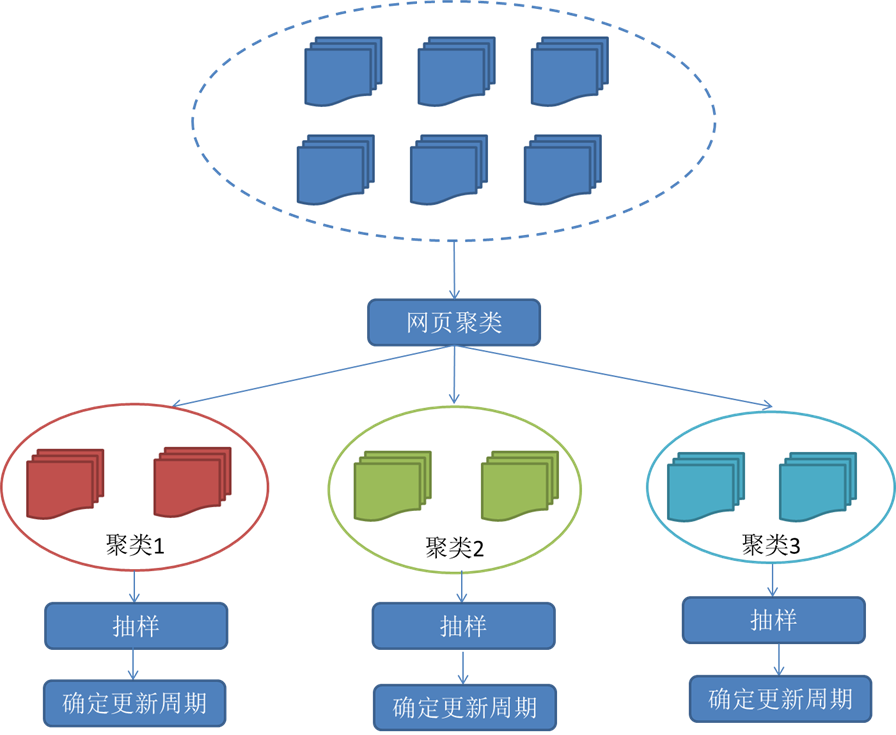
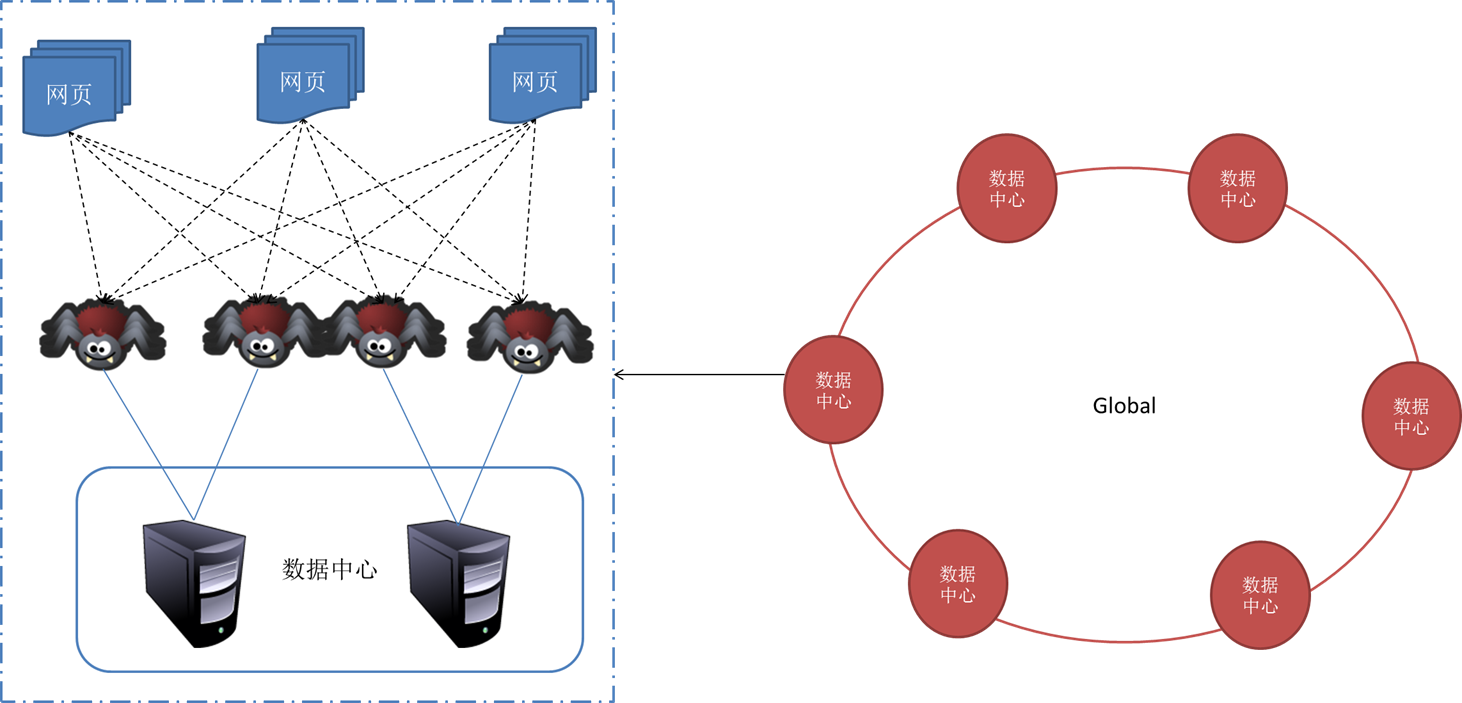
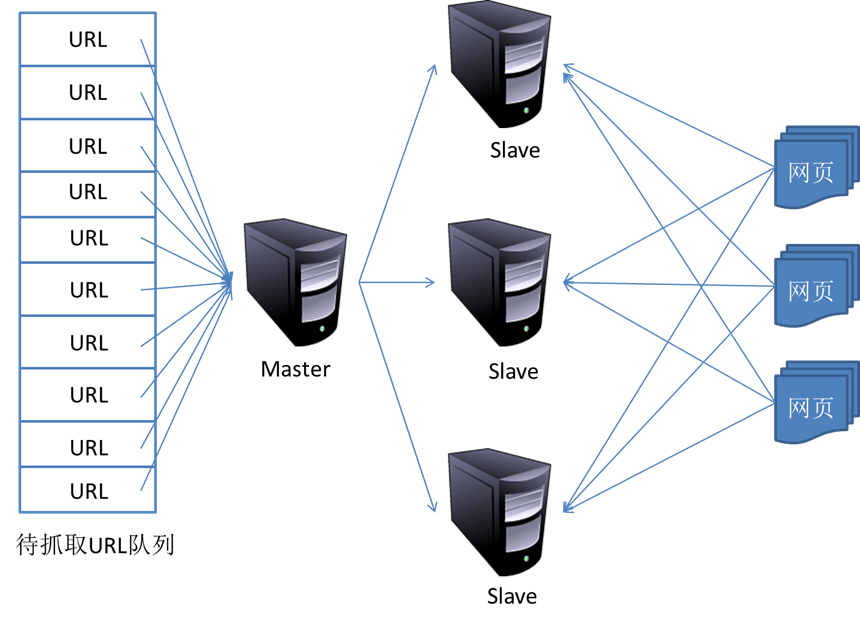
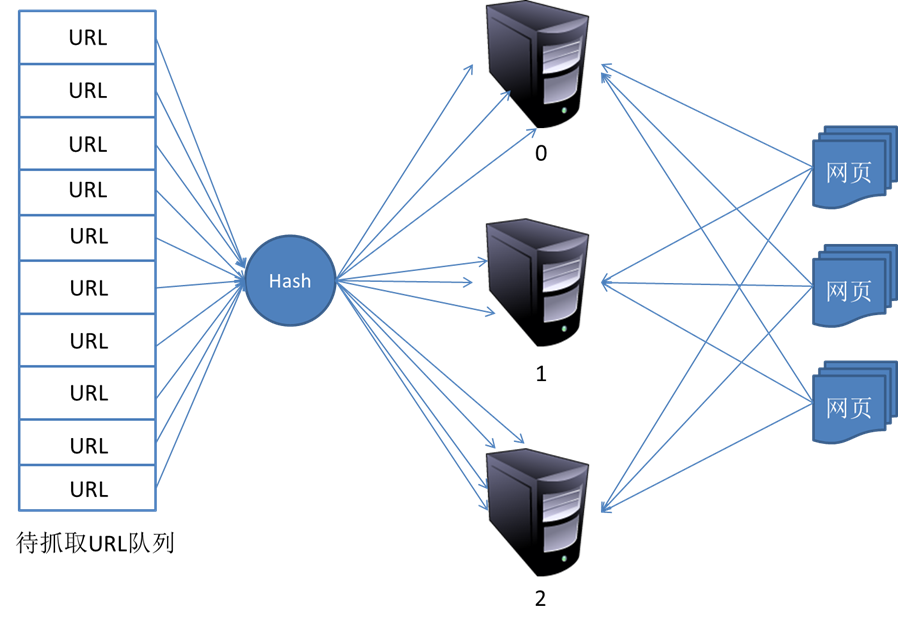
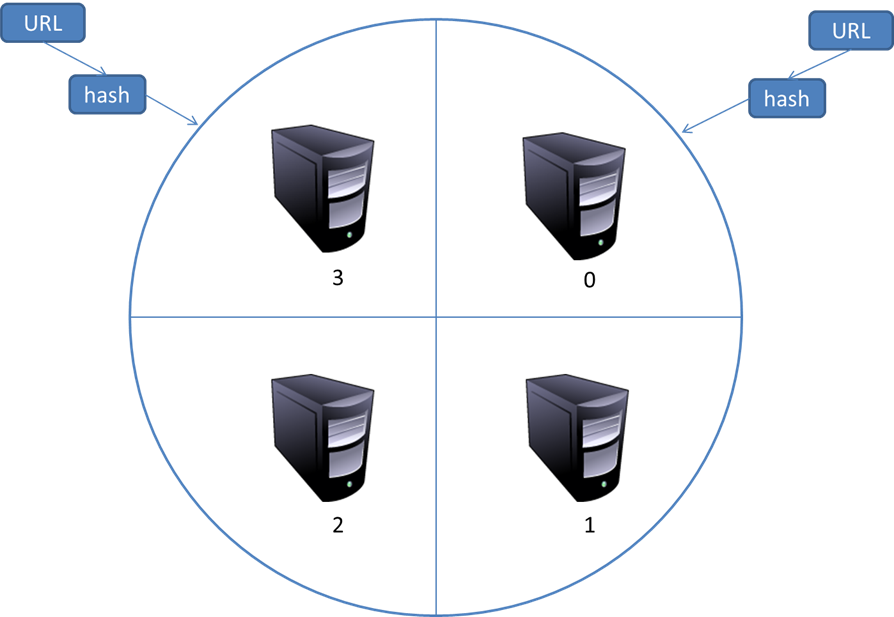
4. 分布式抓取系统结构
一般来说,抓取系统需要面对的是整个互联网上数以亿计的网页。单个抓取程序不可能完成这样的任务。往往需要多个抓取程序一起来处理。一般来说抓取系统往往是一个分布式的三层结构。如图所示:
5. 参考内容

[Search Engine] 搜索引擎技术之网络爬虫的更多相关文章
- [Search Engine] 搜索引擎技术之查询处理
我们之前从开发者的角度谈了一些有关搜索引擎的技术,其实对于用户来说,我们不需要知道网络爬虫到底是怎样爬取网页的,也不需要知道倒排索引是什么,我们只需要输入我们的查询词query,然后能够得到我们想要的 ...
- [Search Engine] 搜索引擎技术之倒排索引
倒排索引是搜索引擎中最为核心的一项技术之一,可以说是搜索引擎的基石.可以说正是有了倒排索引技术,搜索引擎才能有效率的进行数据库查找.删除等操作. 1. 倒排索引的思想 倒排索引源于实际应用中需要根据属 ...
- [Search Engine] 搜索引擎分类和基础架构概述
大家一定不会多搜索引擎感到陌生,搜索引擎是互联网发展的最直接的产物,它可以帮助我们从海量的互联网资料中找到我们查询的内容,也是我们日常学习.工作和娱乐不可或缺的查询工具.之前本人也是经常使用Googl ...
- nutch从搜索引擎到网络爬虫
人物介绍 姓名:DougCutting 个人名望:开发出开源全文检索引擎工具包Lucene. 个人简介/主要荣誉:除了 Lucene,还开发了著名的网络爬虫工具 Nutch,分布式系统基础架构Hado ...
- Apache Nutch v2.3 发布,Java实现的网络爬虫
http://www.oschina.net/news/59287/apache-nutch-2-3 Apache Nutch v2.3已经发布了,建议所有使用2.X系列的用户和开发人员升级到这个版本 ...
- Python网络爬虫实战:根据天猫胸罩销售数据分析中国女性胸部大小分布
本文实现一个非常有趣的项目,这个项目是关于胸罩销售数据分析的.是网络爬虫和数据分析的综合应用项目.本项目会从天猫抓取胸罩销售数据,并将这些数据保存到SQLite数据库中,然后对数据进行清洗,最后通过S ...
- 使用Java实现网络爬虫
网络爬虫 网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本. 另外一些不常使用的名字还有蚂蚁.自动索引.模 ...
- 【网络爬虫入门01】应用Requests和BeautifulSoup联手打造的第一条网络爬虫
[网络爬虫入门01]应用Requests和BeautifulSoup联手打造的第一条网络爬虫 广东职业技术学院 欧浩源 2017-10-14 1.引言 在数据量爆发式增长的大数据时代,网络与用户的沟 ...
- java之网络爬虫介绍
文章大纲 一.网络爬虫基本介绍二.java常见爬虫框架介绍三.WebCollector实战四.项目源码下载五.参考文章 一.网络爬虫基本介绍 1. 什么是网络爬虫 网络爬虫(又被称为网页蜘蛛, ...
随机推荐
- 【WPF系列】-TextBox常用知识点
DataBinding中更新数据源的时机 TextBox .Text 属性的默认 UpdateSourceTrigger 值为 LostFocus.这意味着如果应用程序的 TextBox 包含数据 ...
- EF with (LocalDb)V11.0
EF虽说对LocalDb支持的不错,但LocalDb有自身的缺陷(不想sqlite那样数据库文件可以像普通文件一样使用). LocalDb在一个计算机上会对数据库有唯一性约束,要求本机的localdb ...
- 并查集补集作法 codevs 1069 关押罪犯
1069 关押罪犯 2010年NOIP全国联赛提高组 时间限制: 1 s 空间限制: 128000 KB 题目等级 : 钻石 Diamond 题解 题目描述 Description ...
- BZOJ3223: Tyvj 1729 文艺平衡树 [splay]
3223: Tyvj 1729 文艺平衡树 Time Limit: 10 Sec Memory Limit: 128 MBSubmit: 3595 Solved: 2029[Submit][Sta ...
- python_爬虫一之爬取糗事百科上的段子
目标 抓取糗事百科上的段子 实现每按一次回车显示一个段子 输入想要看的页数,按 'Q' 或者 'q' 退出 实现思路 目标网址:糗事百科 使用requests抓取页面 requests官方教程 使用 ...
- android第一行代码-9.内容提供器
内容提供器(Content Provider)主要用于在不同的应用程序之间实现数据共享的功能, 内容提供器包括两部分:使用现有的内容提供器来读取和操作相应程序中的数据跟创建自己的内容提供器给我们程序的 ...
- Centos6安装Gitlab
安装参考 https://about.gitlab.com/downloads/ 可以从清华的镜像下载安装包, 注意区分自己用的是哪个发行版 https://mirror.tuna.tsinghua. ...
- sql server 排名函数:DENSE_RANK
一.需求 之前sql server 的排名函数用得最多的应该是RoW_NUMBER()了,我通常用ROW_NUMBER() + CTE 来实现分页:今天逛园,看到另一个内置排名函数还不错,自己顺便想了 ...
- DbUtility v3
DbUtility v3 历史 七年前,也就是2007年,我在博客园写了一篇博文,开源并发布了恐怕是我第一个开源项目,DbUtility.其设计的初衷就是为了简化ADO.NET繁琐的数据库访问过程,提 ...
- 微信快速开发框架(七)--发送客服信息,版本更新至V2.2 代码已更新至github
在V2版本发布的博文中,已经介绍了大多数Api的用法,同时也收到了很多意见,其中发布了几个修正版本,修改了几个bug,在此感谢大家的使用,有了大家的支持,相信快速开发框架会越来越好,也会越来越完善的. ...