HDFS(Hadoop Distributed File System)的组件架构概述
1.hadoop1.x和hadoop2.x区别
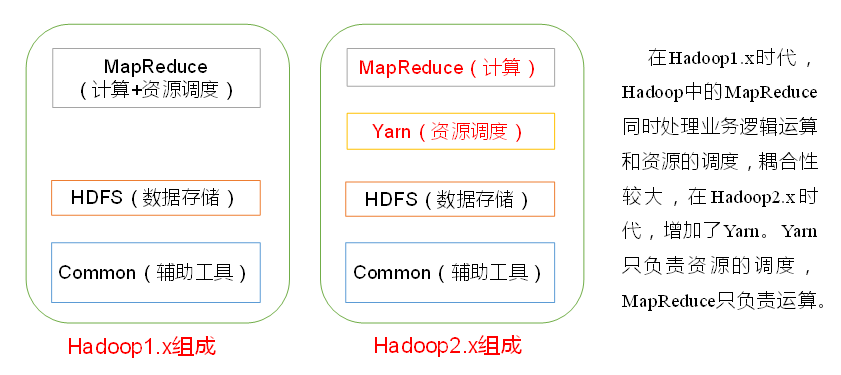
2.组件介绍
HDFS架构概述
1)NameNode(nn):
存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间,副本数,文件权限),以及每个文件的块列表和块所在的DataNode等.
2)DataNode(dn):
在本地文件系统存储文件块数据,以及块数据的校验和.
3)SecondaryNameNode(2nn):
用来监控HDFS状态的辅助后台程序,每隔一段时间获取DHFS元数据的快照.
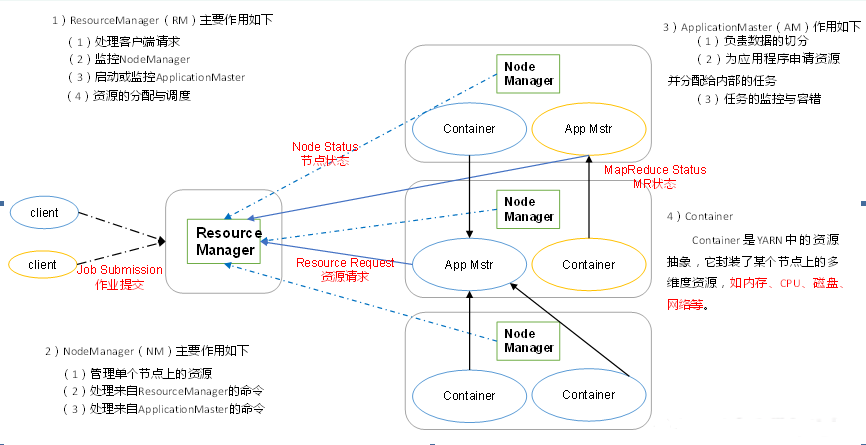
YARN架构概述
1)ResourceManager(RM):
处理客户端请求
监控NodeManager
启动或监控ApplicationMaster
资源的分配与调度
2)NodeManager(NM):
管理单个节点上的资源
处理来自ResourceManger的命令
处理来自ApplicationMaster的命令
3)ApplicationMaster(AM):
负责数据的切分
为应用程序申请资源并分配给内部的任务
任务的监控与容错
4)Container:
Container是YARN的资源抽象,它封装了某个节点上的多维度资源,如内存,CPU,磁盘,网络等
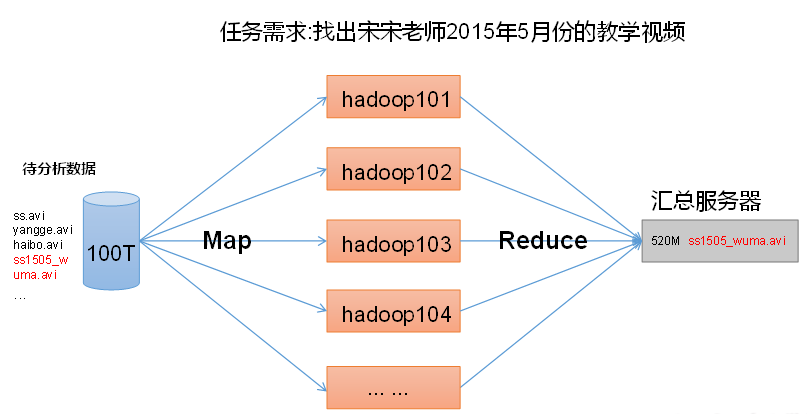
MapReduce架构概述
MapReduce将计算过程分为两个阶段:Map和Reduce
1)Map阶段并行处理输入数据
2)Reduce阶段对Map结果进行汇总
3.大数据技术生态体系
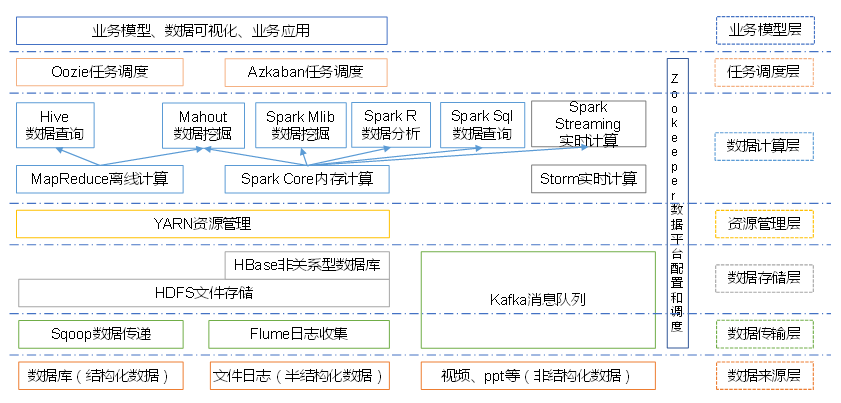
图中涉及的技术名词解释如下:
1)Sqoop:Sqoop是一款开源的工具,主要用于在Hadoop、Hive与传统的数据库(MySql)间进行数据的传递,可以将一个关系型数据库(例如:MySQL,Oracle 等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
2)Flume:Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
3)Kafka:Kafka是一种高吞吐量的分布式发布订阅消息系统,有如下特性:
(1)通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能。
(2)高吞吐量:即使是非常普通的硬件Kafka也可以支持每秒数百万的消息。
(3)支持通过Kafka服务器和消费机集群来分区消息。
(4)支持Hadoop并行数据加载。
4)Storm:Storm用于“连续计算”,对数据流做连续查询,在计算时就将结果以流的形式输出给用户。
5)Spark:Spark是当前最流行的开源大数据内存计算框架。可以基于Hadoop上存储的大数据进行计算。
6)Oozie:Oozie是一个管理Hdoop作业(job)的工作流程调度管理系统。
7)Hbase:HBase是一个分布式的、面向列的开源数据库。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。
8)Hive:Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL查询功能,可以将SQL语句转换为MapReduce任务进行运行。其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
10)R语言:R是用于统计分析、绘图的语言和操作环境。R是属于GNU系统的一个自由、免费、源代码开放的软件,它是一个用于统计计算和统计制图的优秀工具。
11)Mahout:Apache Mahout是个可扩展的机器学习和数据挖掘库。
12)ZooKeeper:Zookeeper是Google的Chubby一个开源的实现。它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、分布式同步、组服务等。ZooKeeper的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
4.推荐系统项目架构

HDFS(Hadoop Distributed File System)的组件架构概述的更多相关文章
- Hadoop ->> HDFS(Hadoop Distributed File System)
HDFS全称是Hadoop Distributed File System.作为分布式文件系统,具有高容错性的特点.它放宽了POSIX对于操作系统接口的要求,可以直接以流(Stream)的形式访问文件 ...
- HDFS(Hadoop Distributed File System )hadoop分布式文件系统。
HDFS(Hadoop Distributed File System )hadoop分布式文件系统.HDFS有如下特点:保存多个副本,且提供容错机制,副本丢失或宕机自动恢复.默认存3份.运行在廉价的 ...
- HDFS(Hadoop Distributed File System )
HDFS(Hadoop Distributed File System ) HDFS(Hadoop Distributed File System )Hadoop分布式文件系统.是根据google发表 ...
- HDFS分布式文件系统(The Hadoop Distributed File System)
The Hadoop Distributed File System (HDFS) is designed to store very large data sets reliably, and to ...
- HDFS(Hadoop Distributed File System )概述
目录 一.HDFS概述 二.HDFS特点 三.HDFS集群组成:主从架构---一个主节点,多个从节点 1. NameNode(名称节点 / 主节点)----- HDFS集群的管理者 2. DataNo ...
- HDFS体系结构:(Distributed File System)
分布式系统的大概图 服务器越来越多,客户端对服务器的管理就会越来越复杂,客户端如果是我们用户,就要去记住大量的ip. 对用户而言访问透明的就是分布式文件系统. 分布式文件系统最大的特点:数据存储在多台 ...
- Yandex Big Data Essentials Week1 Scaling Distributed File System
GFS Key Components components failures are a norm even space utilisation write-once-read-many GFS an ...
- Ceph: A Scalable, High-Performance Distributed File System译文
原文地址:陈晓csdn博客 http://blog.csdn.net/juvxiao/article/details/39495037 论文概况 论文名称:Ceph: A Scalable, High ...
- 5105 pa3 Distributed File System based on Quorum Protocol
1 Design document 1.1 System overview We implemented a distributed file system using a quorum based ...
随机推荐
- 在Eclipse上安装Spring Tool Suite
. 不装IDE会没有Spring bean configure file Spring Tool Suite是一个基于Eclipse IDE开发环境中的用于开发Spring应用程序的工具,提供了开箱即 ...
- Comet OJ - Contest #11 E ffort(组合计数+多项式快速幂)
传送门. 题解: 考虑若最后的总伤害数是s,那么就挡板分配一下,方案数是\(C_{s-1}^{n-1}\). 那么问题在于总伤害数很大,不能一个一个的算. \(C_{s-1}^{n-1}\)的OGF是 ...
- (转)OpenFire源码学习之十三:消息处理
转:http://blog.csdn.net/huwenfeng_2011/article/details/43417817 消息处理流程总揽(该图来源于互联网,图片很大,不过类容还是挺清楚的.不方便 ...
- MProtect使用小计【三】 – 权限管理
说明 本篇简单的说一下怎么样使用的VMProtect的权限管理功能,使我们的程序拥有注册码的功能.只用的注册版的程序才能执行指定的函数. 同样这个功能VMProtect也有例子位置在:安装目录\VMP ...
- install busybox时报error: storage size of ‘rlimit_fsize’ isn’t known struct rlimit rlimit_fsize
解决办法: 在busybox根目录下查找到文件:find -name libbb.h 在libbb.h.h中包含sys/resource.h 说明: 上述错误的原因是rlimit结构体未知,原因是相应 ...
- ajax 重复提交
1.一次点击事件触发两次请求,找到的原因是重复引用了同一个.js文件,后台返回来的数据是个页面,在这个页面里面又引用了.js,所以导致一次点击多次请求
- Bochs调试VirtualBox生成的VDI映像
将VDI映像转换成Bochs支持的img映像 1: vboxmanage clonehd source.vdi destination.img --format RAW 在bochsrc.txt中引用 ...
- 拾遗:Gentoo 使用笔记
零.使用 Git 源 mkdir /etc/portage/repos.conf cd !$ vi gentoo.conf [DEFAULT] main-repo = gentoo [gentoo] ...
- Quartz特点
运行环境 Quartz 可以运行嵌入在另一个独立式应用程序 Quartz 可以在应用程序服务器(或servlet容器)内被实例化,并且参与XA事务 Quartz 可以作为一个独立的程序运行(其自己的J ...
- WebServer Project-01-反射
简介 上网浏览网页,离不开服务器,客户请求页面,服务器响应页面,响应的内容是根据每个web请求来产生动态内容的,其内部即启动多个线程来产生不同内容.这种请求响应的交互,都是基于HTTP协议的. 当然现 ...