spark编程入门-idea环境搭建
原文引自:http://blog.csdn.net/huanbia/article/details/69084895
1、环境准备
idea采用2017.3.1版本。
创建一个文件a.txt

2、构建maven工程
点击File->New->Project…
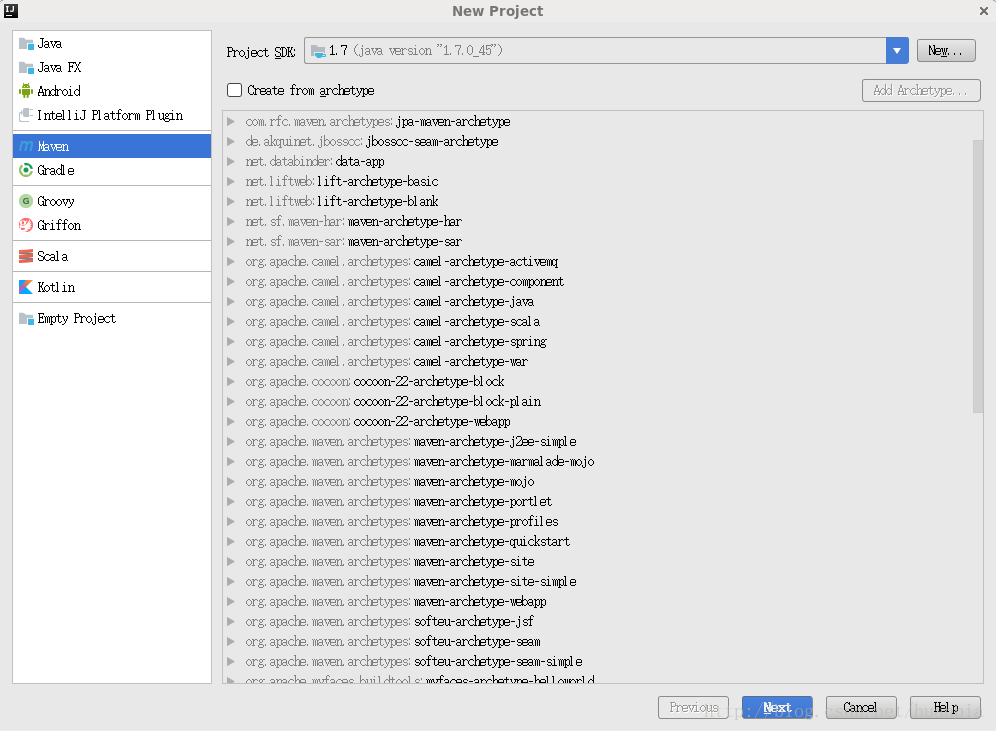
点击Next,其中GroupId和ArtifactId可随意命名

点击Next
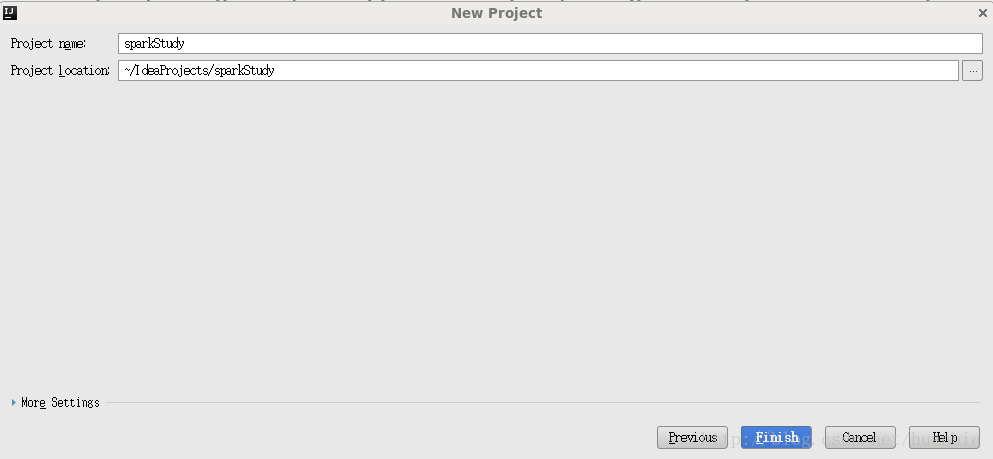
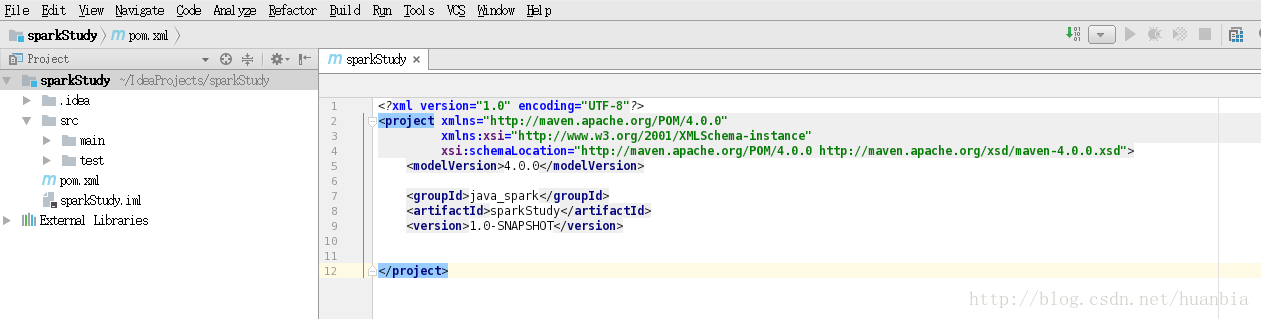
点击Finish,出现如下界面:
3、书写wordCount代码
请在pom.xml中的version标签后追加如下配置
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>1.6.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.10</artifactId>
<version>1.6.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.10</artifactId>
<version>1.6.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.10</artifactId>
<version>1.6.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka_2.10</artifactId>
<version>1.6.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-graphx_2.10</artifactId>
<version>1.6.1</version>
</dependency>
<dependency>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>2.2-beta-5</version>
</dependency>
<dependency>
<groupId>commons-lang</groupId>
<artifactId>commons-lang</artifactId>
<version>2.3</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/java</sourceDirectory>
<testSourceDirectory>src/test/java</testSourceDirectory>
<plugins>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<maniClass></maniClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>exec-maven-plugin</artifactId>
<version>1.3.1</version>
<executions>
<execution>
<goals>
<goal>exec</goal>
</goals>
</execution>
</executions>
<configuration>
<executable>java</executable>
<includeProjectDependencies>false</includeProjectDependencies>
<classpathScope>compile</classpathScope>
<mainClass>com.dt.spark.SparkApps.App</mainClass>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId> <configuration>
<source>1.6</source>
<target>1.6</target>
</configuration>
</plugin>
</plugins>
</build>
点击右下角的Import Changes导入相应的包

点击File->Project Structure…->Moudules,将src和main都选为Sources文件
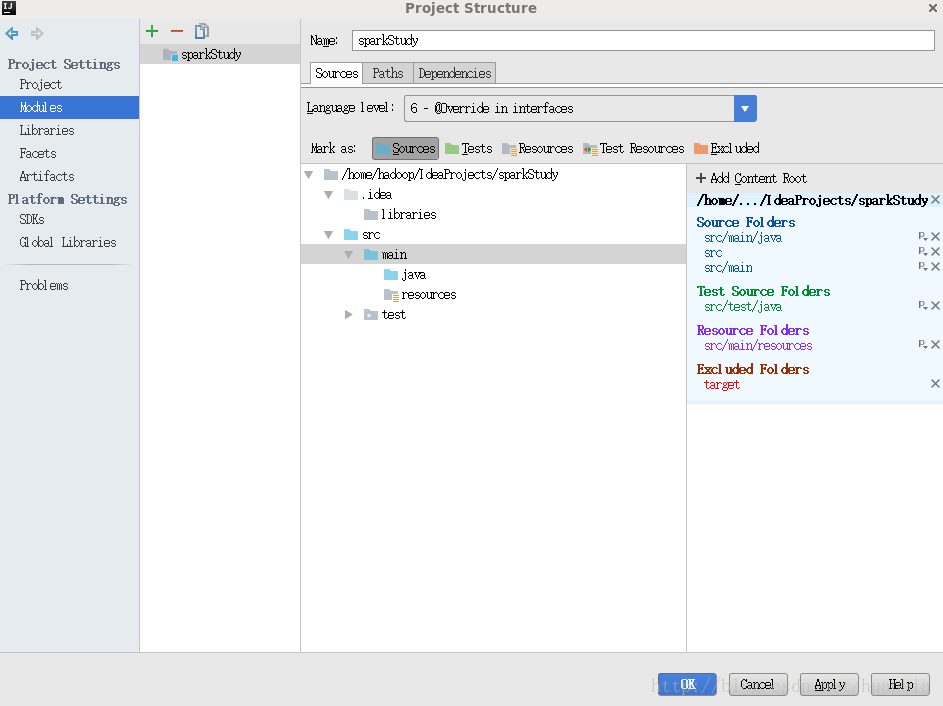
在java文件夹下创建SparkWordCount java文件
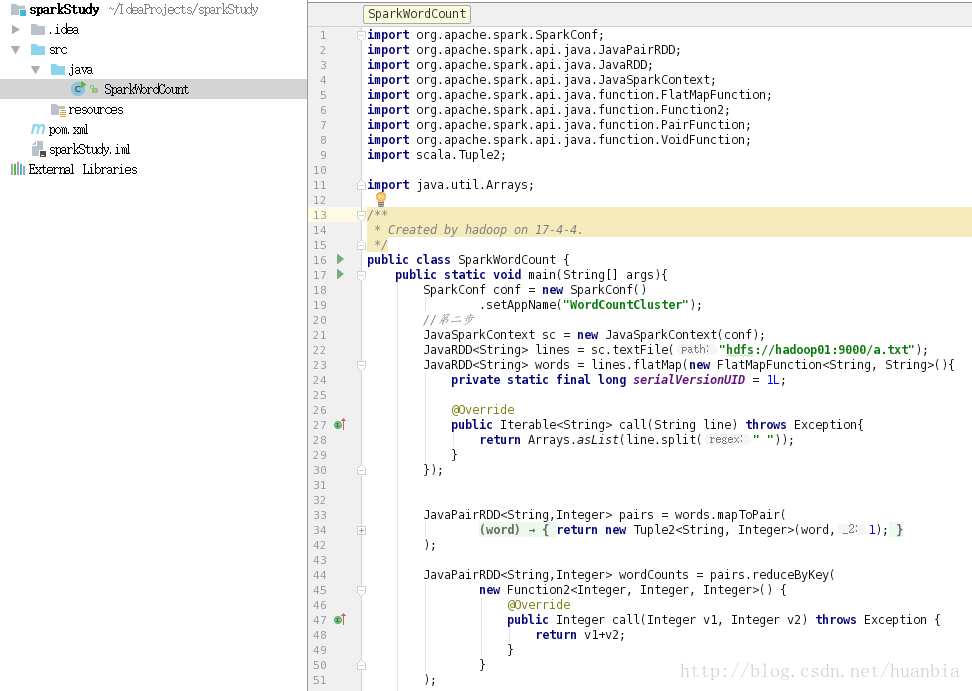
该文件代码为:
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction;
import scala.Tuple2; import java.util.Arrays; /**
* Created by hadoop on 17-4-4.
*/
public class SparkWordCount {
public static void main(String[] args){
SparkConf conf = new SparkConf()
.setAppName("WordCountCluster");
//第二步
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<String> lines = sc.textFile("hdfs://hadoop01:9000/a.txt");
JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>(){
private static final long serialVersionUID = 1L; @Override
public Iterable<String> call(String line) throws Exception{
return Arrays.asList(line.split(" "));
}
}); JavaPairRDD<String,Integer> pairs = words.mapToPair(
new PairFunction<String, String, Integer>() { private static final long serialVersionUID = 1L; public Tuple2<String, Integer> call(String word) throws Exception {
return new Tuple2<String, Integer>(word,1);
}
}
); JavaPairRDD<String,Integer> wordCounts = pairs.reduceByKey(
new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1+v2;
}
}
); wordCounts.foreach(new VoidFunction<Tuple2<String, Integer>>() {
@Override
public void call(Tuple2<String, Integer> wordCount) throws Exception {
System.out.println(wordCount._1+" : "+ wordCount._2 );
}
}); sc.close(); }
}
打包:
执行
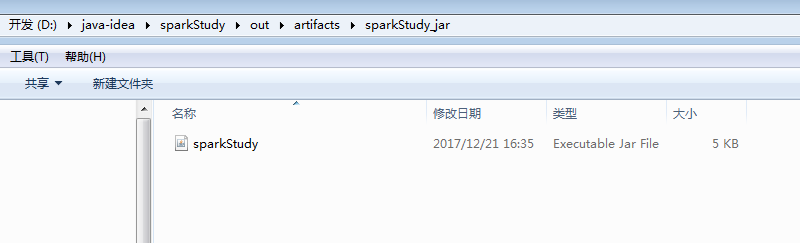
会在output目录下 生成可执行jar包 sparkStudy
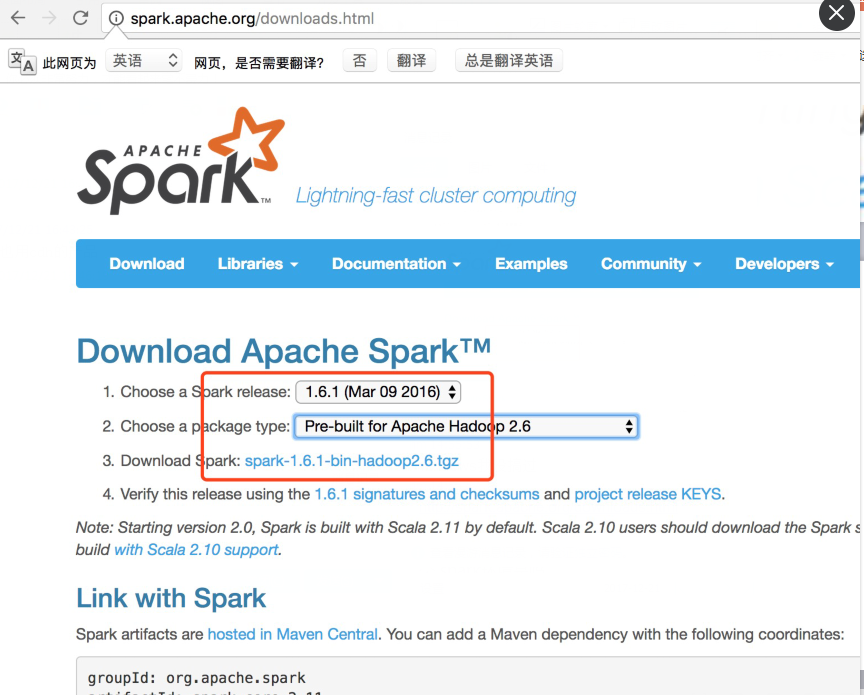
4、jar包上传到集群并执行
从spark官方网站 下载spark-1.6.1-bin-hadoop2.6.tgz
Spark目录:
bin包含用来和Spark交互的可执行文件,如Spark shell。
examples包含一些单机Spark job,可以研究和运行这些例子。
Spark的Shell:
Spark的shell能够处理分布在集群上的数据。
Spark把数据加载到节点的内存中,因此分布式处理可在秒级完成。
快速使用迭代式计算,实时查询、分析一般能够在shells中完成。
Spark提供了Python shells和Scala shells。
解压

这里需要先启动集群:
启动master: ./sbin/start-master.sh
启动worker: ./bin/spark-class org.apache.spark.deploy.worker.Worker spark://localhost:7077
这里的地址为:启动master后,在浏览器输入localhost:8080,查看到的master地址

启动成功后,jps查看进程:
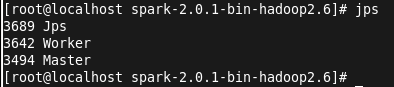
接下来执行提交命令,将打好的jar包上传到linux目录,jar包在项目目录下的out\artifacts下。
提交作业: ./bin/spark-submit --master spark://localhost:7077 --class WordCount /home/lucy/learnspark.jar
可以在4040端口查看job进度:
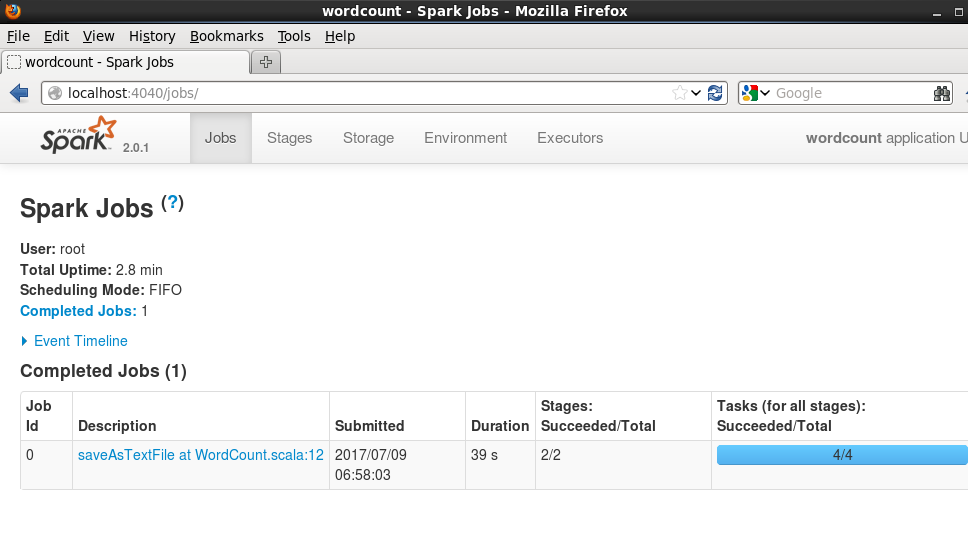
将执行的包上传到服务器上,封装执行的脚本。


然后执行脚本,执行结果如下:
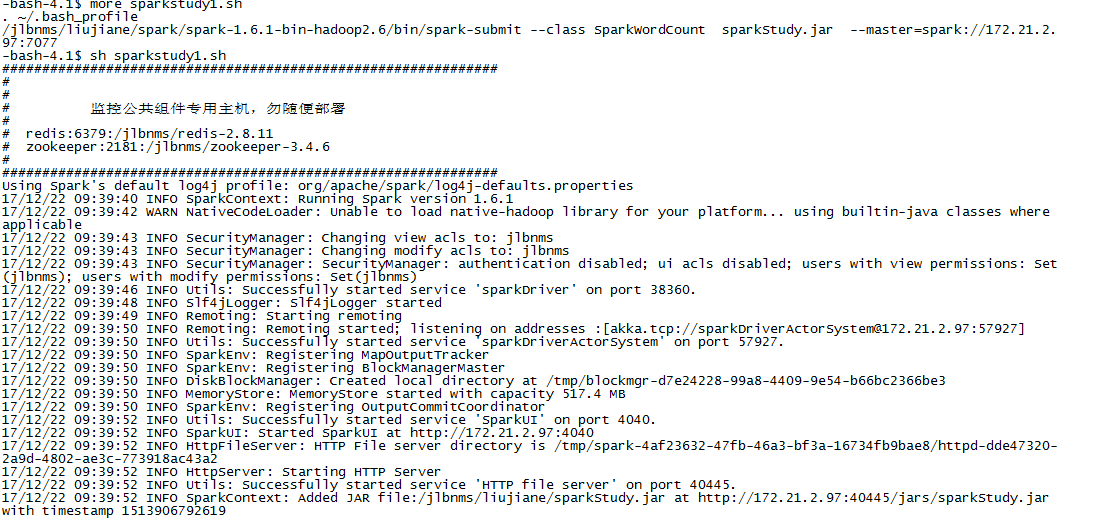
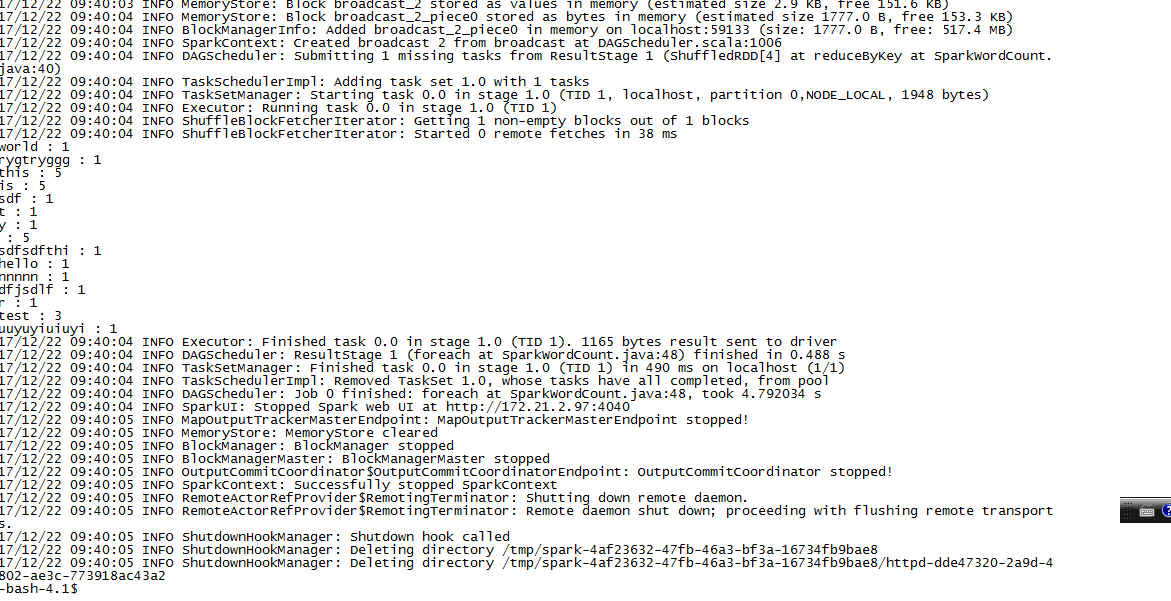
任务执行结束。
spark编程入门-idea环境搭建的更多相关文章
- Minecraft Forge编程入门一 “环境搭建”
什么是Forge Minecraft Forge is a Minecraft application programming interface (API) which allows almost ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十一)定制一个arvo格式文件发送到kafka的topic,通过Structured Streaming读取kafka的数据
将arvo格式数据发送到kafka的topic 第一步:定制avro schema: { "type": "record", "name": ...
- 大数据学习day18----第三阶段spark01--------0.前言(分布式运算框架的核心思想,MR与Spark的比较,spark可以怎么运行,spark提交到spark集群的方式)1. spark(standalone模式)的安装 2. Spark各个角色的功能 3.SparkShell的使用,spark编程入门(wordcount案例)
0.前言 0.1 分布式运算框架的核心思想(此处以MR运行在yarn上为例) 提交job时,resourcemanager(图中写成了master)会根据数据的量以及工作的复杂度,解析工作量,从而 ...
- 【个人笔记】003-PHP基础-01-PHP快速入门-03-PHP环境搭建
003-PHP基础-01-PHP快速入门 03-PHP环境搭建 1.客户端(浏览器) IE FireFox CHROME Opera Safari 2.服务器 是运行网站的基本 是放置程序代码的地方 ...
- Android入门之环境搭建
欢迎访问我的新博客:http://www.milkcu.com/blog/ 原文地址:http://www.milkcu.com/blog/archives/1376935560.html 原创:An ...
- scala 入门Eclipse环境搭建
scala 入门Eclipse环境搭建及第一个入门经典程序HelloWorld IDE选择并下载: scala for eclipse 下载: http://scala-ide.org/downloa ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(二十一)NIFI1.7.1安装
一.nifi基本配置 1. 修改各节点主机名,修改/etc/hosts文件内容. 192.168.0.120 master 192.168.0.121 slave1 192.168.0.122 sla ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十三)kafka+spark streaming打包好的程序提交时提示虚拟内存不足(Container is running beyond virtual memory limits. Current usage: 119.5 MB of 1 GB physical memory used; 2.2 GB of 2.1 G)
异常问题:Container is running beyond virtual memory limits. Current usage: 119.5 MB of 1 GB physical mem ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十二)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网。
Centos7出现异常:Failed to start LSB: Bring up/down networking. 按照<Kafka:ZK+Kafka+Spark Streaming集群环境搭 ...
随机推荐
- Benchmark of Large-scale Unconstrained Face Recognition-blufr 算法的理解
Many efforts have been made in recent years to tackle the unconstrained face recognition challenge. ...
- Linux 系统版本查询命令
.# uname -a (Linux查看版本当前操作系统内核信息) .# cat /proc/version (Linux查看当前操作系统版本信息) .# cat /etc/issue 或 cat / ...
- 在VMware中创建一个新的虚拟机 ,安装Linux4.X系统 ,之后在此基础上安装openfiler(网络存储管理实用程序)
到此为止虚拟机的前期设置准备好了 下面来为此虚拟机添加iso镜像 (这个是在http://www.openfiler.com/community/download openfiler官网上面下载的) ...
- SQL Server - SQL Server/ bcp 工具如何通信
问题-BCP通讯 ref: https://stackoverflow.com/questions/40664708/bcp-cannot-connect-to-aws-sql-server-but- ...
- day12 bash中的if、for
bash 变量bash 定义:x= 作用:记录状态 规则:字母开头,后面可以接字母.数字.下划线 export args:将变量定义为全局变量 $$[]:括号中可以进行简单的数学整数运算,可以用ech ...
- Eclipse中servlet简易模版
package ${enclosing_package}; import java.io.IOException; import javax.servlet.ServletException; imp ...
- SqlSugar入门级教程+实例 (.net core下的)
官方参考:http://www.codeisbug.com/Doc/8 前言:这应该是目前最好用的ORM框架之一了,而且支持.net core,网上除了官方文档其他参考就少了点,自己整理了一下,大致包 ...
- Heartbeat基本介绍----HA / vmware HA FT
Heartbeat是High-Availability Linux Project (Linux下的高可用性项目)的产物,是一套提供防止业务主机因不可避免的意外性或计划性宕机问题的高可用性软件.Hea ...
- django-filter 实现过滤时查询是否包含在数组的方法,in数组的实现
查了半天无解,还是在官网找到的,记录一下 使用 BaseInFilter 官网地址:https://django-filter.readthedocs.io/en/master/ref/filters ...
- iOS扩展Extension之Today
1.简介 扩展(Extension)是iOS 8中引入的一个新特性.扩展让app之间的数据交互成为可能.在iOS 8系统之前,每一个app在物理上都是彼此独立的,app之间不能互访彼此的私有数据.而在 ...